唐傑@jietang 是清華大學教授、智譜(GLM 系列模型出自他們家)AI 首席科學家,也是國內最懂大模型的人之一。他剛發了長微博(見評論),談2025 年對大模型的感悟。 有趣的是,唐杰和Andrej Karpathy 的觀察有不少共鳴,但也有一些不同的重點。兩個頂尖專家的視角放在一起看,能看出更完整的圖像。 內容比較長,但有句話我要特別放在前面高亮一下: > AI 模型應用的第一原理不應該是創造新的App,它的本質是AGI 取代人類工作,因此研發替代不同工種的AI 是應用的關鍵 如果你在做AI 應用開發,你應該反覆思考這句話:AI 應用的第一原理不是創造新產品,而是取代人類工作。想清楚這一點,很多事情的優先順序就清楚了。 唐傑的核心觀點有七層邏輯。 --- 第一層:預訓練沒死,只是不再是唯一主角 預訓練仍然是讓模型掌握世界知識和基礎推理能力的根基。 更多的數據、更大的參數、更飽和的計算,仍是提升模型智商最有效率的辦法。這就像還在長身體的孩子,飯量(算力)和營養(數據)必須管夠,這是物理規律,沒辦法繞彎。 但光有智商不行,現在的模型有個毛病:容易「偏科」。為了刷榜單(Benchmark),許多模型都在針對性地做題,導致在真實複雜的場景下反而不好用。這好比孩子上完九年義務教育(預訓練)後,必須把他扔到真實的職場裡去實習,去處理那些書本上沒有的爛攤子,這才是真本事。 所以接下來的重點就是「中後訓練」(Mid and Post training)。中後訓練這兩個階段負責「啟動」模型的能力,尤其是長尾場景的對齊能力。 什麼是長尾場景?就是那些不常見但真實存在的需求。例如幫律師整理某類特殊合約、幫醫生分析某種罕見疾病的影像。這些場景在通用測試集裡佔比很小,但在真實應用中至關重要。 通用benchmark 一方面評測了模型效果,但也可能讓許多模型過度擬合。這和Karpathy 說的「訓練在測試集上是一門新藝術」觀點一致。大家都在刷榜,但榜單刷了高分不等於能解決真實問題。 --- 第二層:Agent 是從「學生」到「打工人」的跨越 唐傑用了個形象的比喻: > 如果沒有Agent 能力,大模型就是個「理論博士」。一個人書讀得再多,讀到了博士後,如果不能動手解決問題,那也只是知識的容器,產生不了生產力。 這個比喻精準。預訓練是上課,強化學習是刷題,但這些都還在「學習階段」。 Agent 是讓模型真正「工作」的關鍵,是進入真實世界、產生實際價值的門檻。 不同Agent 環境的泛化和遷移並不容易。你在一個程式碼環境裡訓出來的能力,換到瀏覽器環境就不一定好使。現在最簡單的方法,還是不斷堆疊更多環境的數據,針對不同環境做強化學習。 以前我們做Agent,是給模型外掛各種工具。現在的趨勢是,直接把使用工具的資料寫進模型的「DNA」裡去訓練。 這聽起來有點笨,但確實是當下最有效的路徑。 Karpathy 也把Agent 列為今年最重要的變化之一,他以Claude Code 為例,強調Agent 要能「住在你電腦裡」,調用工具、循環執行、解決複雜問題。 --- 第三層:記憶是剛需,但怎麼做還沒想清楚 唐傑花了不少篇幅講記憶。他認為,模型要在真實環境中落地,記憶能力是必須的。 他把人類記憶分成四層: - 短期記憶,對應前額葉 - 中期記憶,對應海馬體 - 長期記憶,分佈在大腦皮質 - 人類歷史記憶,對應維基百科與史書 AI 也要模仿這個機制,大模型對應的可能是: - Context 視窗→ 短期記憶 - RAG 擷取→ 中期記憶 - 模型參數→ 長期記憶 一個想法是「壓縮記憶」,把重要訊息精簡後存在context 裡。目前的「超長上下文」只是解決了短期記憶,相當於把它能用的「便條紙」變長了。如果未來context 視窗夠長,短中長期記憶都有可能實現。 但有個更難的問題:怎麼更新模型本身的知識?怎麼改參數?這還是個未解難題。 --- 第四層:線上學習和自我評估,可能是下一個Scaling 範式 這一段是唐傑觀點裡最前瞻的部分。 現在的模型是「離線」的,訓練好就不變了。這有幾個問題:模型不能真正自我迭代,重新訓練浪費資源,還會丟掉很多互動資料。 理想情況是什麼?模型能在線學習,邊用邊學,越用越聰明。 但要實現這一點,有個前置條件:模型要知道自己對不對。這就是“自我評估”。如果模型能判斷自己的輸出質量,就算是機率性地判斷,它就知道了優化目標,就能自我改進。 唐傑認為,建構模型的自我評價機制是個難題,但也可能是下一個scaling 範式的方向。他用了幾個字:continual learning、real time learning、online learning。 這和Karpathy 提到的RLVR 有一定呼應。 RLVR 之所以有效,正是因為有「可驗證的獎勵」,模型能知道自己對不對。如果這個機制能泛化到更多場景,線上學習就有可能實現。 --- 第五層:AI 應用的第一原理是「替代工種」 這是對我啟發最大的一句話: > AI 模型應用的第一原理不應該是創造新的App,它的本質是AGI 取代人類工作,因此研發替代不同工種的AI 是應用的關鍵 AI 的本質不是創造新的App,而是取代人類工作。 兩條路: 1. 把以前需要人參與的軟體AI 化。 2. 創造對齊人類某個工種的AI 軟體,直接取代人類工作。 Chat 已經部分取代了搜索,同時也融合了情感交互,下一步就是取代客服、取代初級程式設計師、替代資料分析師。 所以,明年2026 年的爆發點在於「AI 取代不同工種」。 創業者要思考的不是“我要開發個什麼軟體給用戶用”,而是“我要造一個什麼樣的AI 員工,去幫老闆把某個崗位的人力成本砍掉”。 換句話說,別老是想著做一個「AI+X」的新產品,先想想哪些人類工作可以被取代,再倒推產品型態。 這和Karpathy 關於「Cursor for X」的觀察遙相呼應。 Cursor 本質上是「程式設計師這個工種的AI 化」,那麼各行各業都會出現類似的東西。 --- 第六層:領域大模型是個「偽命題」 這個觀點可能會讓某些人不舒服,但唐傑說得很直接:領域大模型就是個偽命題。都AGI 了,哪有什麼「領域專用(domain-specific)AGI」? 之所以有領域大模型存在,是因為應用企業不願意在AI 模型公司面前認輸,希望用領域know-how 建構護城河,把AI 馴化為工具。 但AI 的本質是「海嘯」,走到哪裡都會把一切捲進去。一定會有領域公司主動走出護城河,被捲進AGI 的世界。領域的數據、流程、Agent 數據,慢慢都會進入主模型。 當然AGI 還沒實現之前,領域模型會長時間存在。但這個時間窗口有多長?不好說,AI 發展實在太快了。 --- 第七層:多模態和具身智能,前景光明但道路艱難 多模態肯定是未來。但當下的問題是:它對提升AGI 的智慧上限幫助有限。 文本、多模態、多模態生成,可能還是分開發展更有效率。當然,探索三者結合需要勇氣和金錢。 具身智能(機器人)更難。難點和Agent 一樣:通用性。你教會機器人在A 場景工作,換個場景又不行了。怎麼辦?採數據、合成數據,都不容易,還貴。 怎麼辦?採數據,或合成數據。都不容易,都貴。但反過來,一旦資料規模上去了,通用能力出來了,自然就形成門檻。 還有個問題往往被忽略:機器人本身也是個問題。不穩定、故障頻繁,這些硬體問題也在限制具身智能的發展。 唐傑預判2026 年這些都將有長足進步。 --- 把唐傑這篇文章串起來,其實是一張相當清晰的路線圖: 當下,預訓練scaling 依然有效,但要更重視對齊和長尾能力。 近期,Agent 是關鍵突破口,讓模型從"會說"進化到"會做"。 中期,記憶系統和線上學習是必修課,模型要學會自我評估和迭代。 長期,工種替代是應用的本質,領域護城河會被AGI 沖垮。 遠景,多模態和具身各自發展,等待技術和數據的成熟。 --- 把唐杰和Karpathy 的觀點放在一起看,可以看出幾個共識: 第一,2025 年的核心變化是訓練範式的升級,從「預訓練為主」變成「多階段協同」。 第二,Agent 是里程碑,是模型從學習走向工作的關鍵跨越。 第三,benchmark 刷分和真實能力之間有鴻溝,這個問題越來越被重視。 第四,AI 應用的本質是替代或增強人類工種,不是為了做App 而做App。 不同的重點也有意思。 Karpathy 更關注「AI 是什麼形狀的智慧」這個哲學問題,唐傑更關注「怎麼讓模型在真實場景落地」的工程問題。一個偏「理解」,一個偏「實現」。 兩個視角都需要。理解清楚了,才知道方向對不對;工程跟上了,才能把想法變成現實。 2026 年,會很精彩。
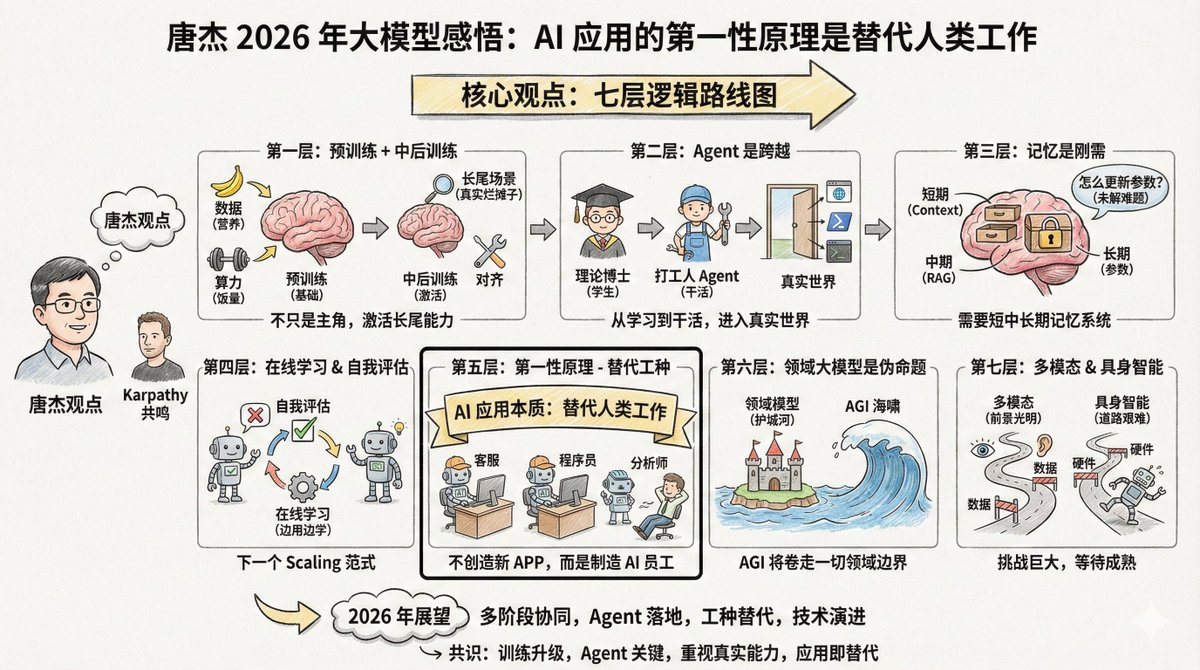
以下內容來自唐傑微博: weibo.com/2126427211/QjI… 最近的一些感悟,分享一下,希望對大家有用。 -預訓練使得大模型已經掌握世界常識知識,並且具備簡單推理能力。更多資料、更大參數和更飽和的計算仍然是scaling基座模型最有效率的辦法。 -激活對齊和增強推理能力,尤其是激活更全面的長尾能力是保證模型效果的另一個關鍵,通用benchmark的出現一方面評測了模型通用效果,但也可能使得很多模型過擬合。真實場景下是如何讓模型更快、更好的對齊長尾的真實場景,增強實際體感。 mid和post training使得更多場景的快速對齊和強推理能力成為可能。 -agent是模型能力擴展的里程碑,也是體現ai模型進入人類真實(虛擬/物理)世界的關鍵。沒有agent能力,大模型將停留在(理論學習)階段,就類似一個人不斷學習,即使學習到博士,也只是知識積累,還沒有轉化為生產力。原來的agent是透過模型應用來實現,現在模型已經可以直接將agent資料整合到訓練過程,增強了模型的通用性,其實難題還是不同agent環境的泛化和遷移並不是那麼容易,因此最簡單辦法也只有不斷增加不同agent環境的資料和針對不同環境的強化學習。 -實現模型記憶成為必須做的事情,這也是一個模型應用到真實環境必須有的能力。人類記憶分為短期(前額葉)、中期(海馬體)、長期(分佈式大腦皮質)、人類歷史(wiki或史書)四個階段。大模型如何實現不同階段的記憶是個關鍵,context、rag、模型參數可能分別對應了人類的不同記憶階段,但如何實現是個關鍵,一種辦法是壓縮記憶,簡單存在context,如果大模型可以支援足夠長的context,那麼基本上有可能實現短中長期的記憶。但如何迭代模型知識,更改模型參數這還是個難題。 -線上學習與自我評估。有了記憶機理,線上學習成為一個重點,目前的大模型定時重新訓練,這有幾個問題:模型無法真正的自我迭代,但模型的自學習自迭代一定會是下一個階段必然具有的能力;重新訓練還比較浪費,同時也會丟掉很多交互數據。因此如何實現線上學習是個關鍵,自我評估是在線學習的一個關鍵點,要想模型自我學習,模型首先要知道自己對還是不對,如果知道了(即使概率知道)模型就知道了優化目標,能夠自我改進。因此建構模型自我評估機制是個難題。這也可能是下一個scaling範式。 continual learning/real time learning/online learning? -最後,大模型的發展越來越端到端,不可避免的要把模型研發和模型應用結合起來。 ai模型應用的第一性不應該是創造新的app,他的本質是agi取代人類工作,因此研發替代不同工種的ai是應用的關鍵。 chat部分取代了搜索,部分其實融合了情感互動。明年將是ai替代不同工種的爆發年。 -寫在最後的是多模態和具身。多模態肯定是個未來也很有前景,當下的問題是多模態不大能幫助到agi的智能上界,而通用agi的智能上界到底在哪兒還不知道。可能最有效的方式還是分開發展,文本、多模態、多模態生成。當然適度的探索這三者的結合肯定能發現一些很不一樣的能力,這需要勇氣和雄厚的資本支持。 同理,如果看懂了agent就知道具身的痛在哪裡了,太難通用了(也不一定),但至少少樣本去激活通用具身能力基本上不可能。那怎麼辦呢,採數據,或合成數據,都不是那麼容易,也貴。但反之一旦資料規模上去了,通用能力出來了自然會形成門檻。當然這只是智能方面的難題,對於具身,機器人本身也是個問題,不穩定,故障頻繁都限制了具身智能的發展。 2026年這些都將有長足進步。 -也討論一下領域大模型和大模型應用。我一直認為領域大模型就是個偽命題,都agi了哪有什麼domain-specific agi……但,agi還沒實現,領域模型會長時間存在(多長,不好說,ai發展實在太快了)。領域模型的存在本質上是應用企業不願意在ai企業面前認輸,希望建構領域know how的護城河,不希望ai入侵,希望把ai馴化為工具。而ai的本質是海嘯,走到哪裡都將一切捲了進去,一定有一些領域公司走出護城河,自然就捲進了agi的世界。簡而言之,領域的資料、流程、agent資料慢慢的都會進入主模型。 而大模型的應用也要回到第一原理,ai不需要創造新的應用。 ai的本質是模擬人或代替人或幫助人實現人類的某些必須要做到事(某些工種)。可能是兩種,一種是ai化以前的軟體,原來需要人參與的改成ai,另一種就是創造對齊人類某個工種的ai軟體,取代人類工作。所以大模型應用需要幫助人、創造新的價值。如果做一個ai軟體沒人用,不能產生價值,那這個ai軟體一定沒有生命力。