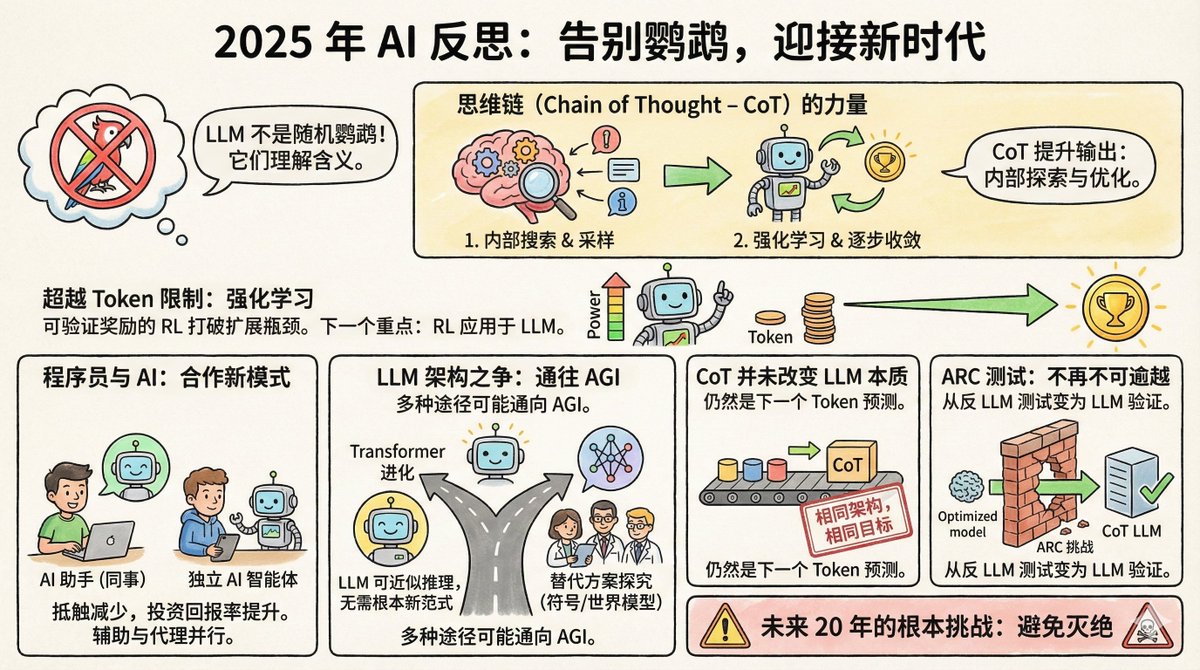
Redis 父親Salvatore Sanfilippo 最近發了一篇年終AI 反思,一共8 條觀點。 先說個背景:Salvatore 不是AI 圈的人,他是程式設計師圈的傳奇。 2009 年創造了Redis,這個資料庫如今是全球最受歡迎的快取系統之一。 2020 年他從Redis 退休,去做自己的事。 2024 年底回歸Redis,同時成了AI 工具的深度用戶,Claude 則是他的程式設計夥伴。 這種身分很有意思──他既是技術大牛,也是AI 的一般使用者,視角比純AI 研究者更接地氣。 一、隨機鸚鵡的說法,終於沒人信了 2021 年,Google 的研究員Timnit Gebru 等人發了篇論文,給大語言模型起了個綽號叫隨機鸚鵡。意思是這些模型只是在機率性地拼湊文字,既不理解問題是什麼意思,也不知道自己在說什麼。 這個比喻很形象,傳播很廣。但Salvatore 說,到2025 年,幾乎沒人再這麼說了。 為什麼?因為證據太多了。 LLM 在律師資格考試、醫學考試、數學競賽上的表現超過了絕大多數人類。更關鍵的是,研究者透過逆向工程這些模型,發現裡面確實形成了對概念的內部表徵,而不是簡單的字詞拼貼。 Geoffrey Hinton 的說法最直接:要準確預測下一個詞,你必須理解這個句子。理解不是預測的替代品,而是做好預測的必要條件。 當然,LLM 是不是真的理解,哲學上還可以爭論。但實用層面,這個爭論已經結束了。 二、思維鍊是個被低估的突破 思考鏈,就是讓模型在回答之前先把思考過程寫出來。看起來簡單,背後的機制卻很深。 Salvatore 認為它做了兩件事: 第一,它讓模型在回答前先取樣自己的內在表徵。說人話就是,先把和問題相關的概念、資訊調動到上下文裡,再基於這些資訊回答。這有點像人考試前先在草稿紙上列提綱。 第二,結合強化學習,模型學會如何一步一步把思考推向正確答案。每一個token 的產出都會改變模型的狀態,強化學習幫它找到那條能收斂到好答案的路徑。 這不是什麼神秘的東西,但效果驚人。 三、算力擴張的瓶頸被打破了 以前AI 圈有共識:模型能力的提升取決於訓練資料量,而人類產出的文字是有限的,所以擴張遲早會撞牆。 但現在有了可驗證獎勵的強化學習,情況改變了。 什麼是可驗證獎勵?就是有些任務,例如優化程式速度、證明數學定理,模型可以自己判斷結果好不好。程式跑得更快就是更好,證明對了就是對了,不需要人來標註。 這意味著模型可以在這類任務上持續自我提升,產生幾乎無限的訓練訊號。 Salvatore 認為,這將是AI 下一個大突破的方向。 還記得AlphaGo 第37 手嗎?那步棋當時沒人看懂,後來證明是神之一手。 Salvatore 覺得,LLM 在某些領域也可能走出這樣的路徑。 四、程式設計師的態度轉變了 一年前,程式設計師圈還分成兩派:一派覺得AI 輔助程式是神器,一派覺得是玩具。現在,懷疑派大規模倒戈了。 原因很簡單:投入產出比過了臨界點。模型確實會犯錯,但它節省的時間遠遠超過你修正錯誤的成本。 有趣的是,程式設計師使用AI 的方式分成了兩派:一派把LLM 當"同事",主要透過網頁介面對話式地用。 Salvatore 本身就是這派,用Gemini、Claude 這些的網頁版,像跟一個懂行的人聊天一樣協作。 另一派把LLM 當"獨立自主的編碼智能體",讓它自己去寫程式碼、跑步測試、修bug,人類主要負責審核。 這兩種用法背後是不同的哲學:你是把AI 當助手,還是當執行者? 五、Transformer 可能就是那條路 一些知名AI 科學家開始探索Transformer 以外的架構,成立公司研究顯式符號表徵或世界模型。 Salvatore 對此持開放但謹慎的態度。他認為LLM 本質上是在一個可微分的空間裡近似離散推理,不是不可能在沒有根本性新範式的情況下就達到AGI。而且,AGI 可能透過多種完全不同的架構獨立實現。 換句話說,條條大路通羅馬。 Transformer 可能不是唯一的路,但也不一定是死路。 六、思維鏈沒有改變LLM 的本質 有人改口了。以前說LLM 是隨機鸚鵡,現在承認LLM 有能力了,但又說思維鏈從根本上改變了LLM 的本質,所以以前的批評仍然對。 Salvatore 直接說:他們在說謊。 架構沒變,還是Transformer。訓練目標沒變,還是預測下一個token。 CoT 也是由一個token 一個token 產生的,跟生成別的內容沒有本質區別。你不能因為模型變強了就說它"變成了另一個東西",來給自己的錯誤判斷找台階下。 這話說得挺不客氣,但邏輯上確實站得住。科學判斷應該基於機制,不能因為結果變了就改定義。 還有一個案例很能說明問題:ARC 測試。 七、ARC 測試從反LLM 變成了親LLM ARC 是François Chollet 在2019 年設計的測試,專門用來測量抽象推理能力。它的設計初衷就是抗記憶、抗暴力窮舉,只能靠真正的推理來解。 當時很多人認為,LLM 永遠過不了這個測試。因為它需要的是從極少樣本中歸納規則、應用到新情況的能力,這恰恰是隨機鸚鵡做不到的。 結果呢? 2024 年底,OpenAI 的o3 在ARC-AGI-1 上達到了75.7% 的準確率。 2025 年,即使是更難的ARC-AGI-2,頂尖模型也能達到50% 以上。 這個逆轉挺諷刺的。當初設計這個測試,就是為了證明LLM 不行。結果它反而成了證明LLM 可以的證據。 八、未來20 年的根本挑戰 最後一條只有一句話:未來20 年AI 的根本挑戰是避免滅絕。 沒有展開,就這麼一句話。但你知道他在說什麼。當AI 真的變得足夠強大,"怎麼確保它不會出大問題"就不再是科幻話題了。 Salvatore 不是AI 的狂熱信徒,也不是懷疑論者。他是一個既懂技術又在實際用AI 的人。不是純粹學術的視角,也不是純粹商業的吹捧,而是資深工程師的冷靜觀察。 他的核心判斷是:LLM 比許多人願意承認的要強大得多,強化學習正在開啟新的可能性,而我們對這些系統的理解還遠遠不夠。 這大概就是2025 年AI 發展的真實狀態:能力在加速,爭議在減少,但不確定性仍然巨大。