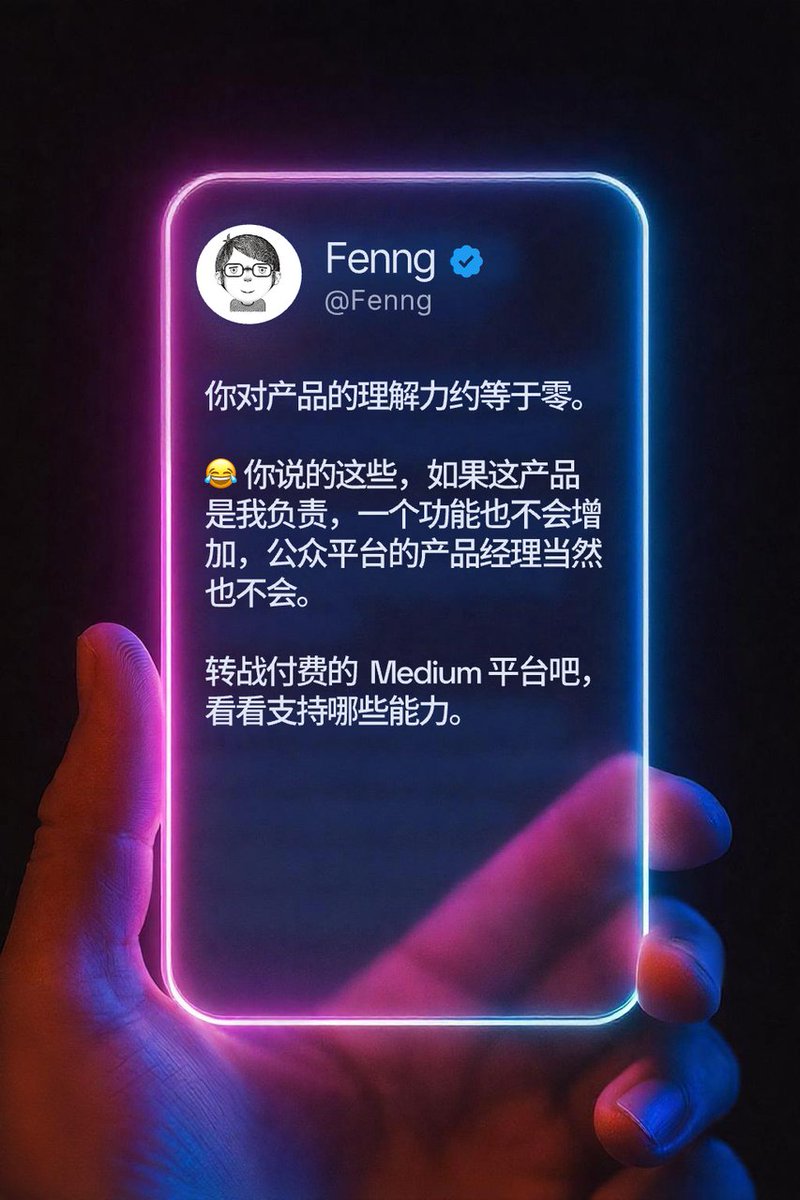
這幾天這種未來感的半透明發光卡片很火,如何製作的提示詞我也分享過,不過要做好也不太容易: - AI 畫圖中文支援不好,常出現亂碼 - 生成結果參差不齊,需要多次抽卡才能得到一張比較好的結果 - 成本較高,需重複產生多張,且需長時間等待 但你看我現在這張,效果就還挺好,中文文字、頭像和認證標籤都清晰準確,甚至表情符號都能正常顯示,那麼要怎麼做到這樣的效果呢? 🧵
這裡確實用了點黑科技,就是Lovart ( hlovart.ai)的Layered Image Editing(分層影像編輯)功能,它能自動辨識一張圖片中的不同元素,把它們拆分成獨立圖層。甚至可以辨識&直接編輯文字!
具體步驟是這樣的,先找一張生成效果好的圖片,需要卡片是平的,如果是斜的就會比較麻煩,因為文字也要傾斜,比如我這裡選的是網友@CicidaMay 生成的這張圖,正面無傾斜,美觀清晰。

然後在Lovart 中新建一個Project,上傳這張圖片,選中圖片後,在浮動選單中選擇“Edit Element”,稍等幾分鐘,就會產生一個有多張圖層拼在一起的圖片,其中的文字都拆分成了獨立的圖層,可以自由編輯了。

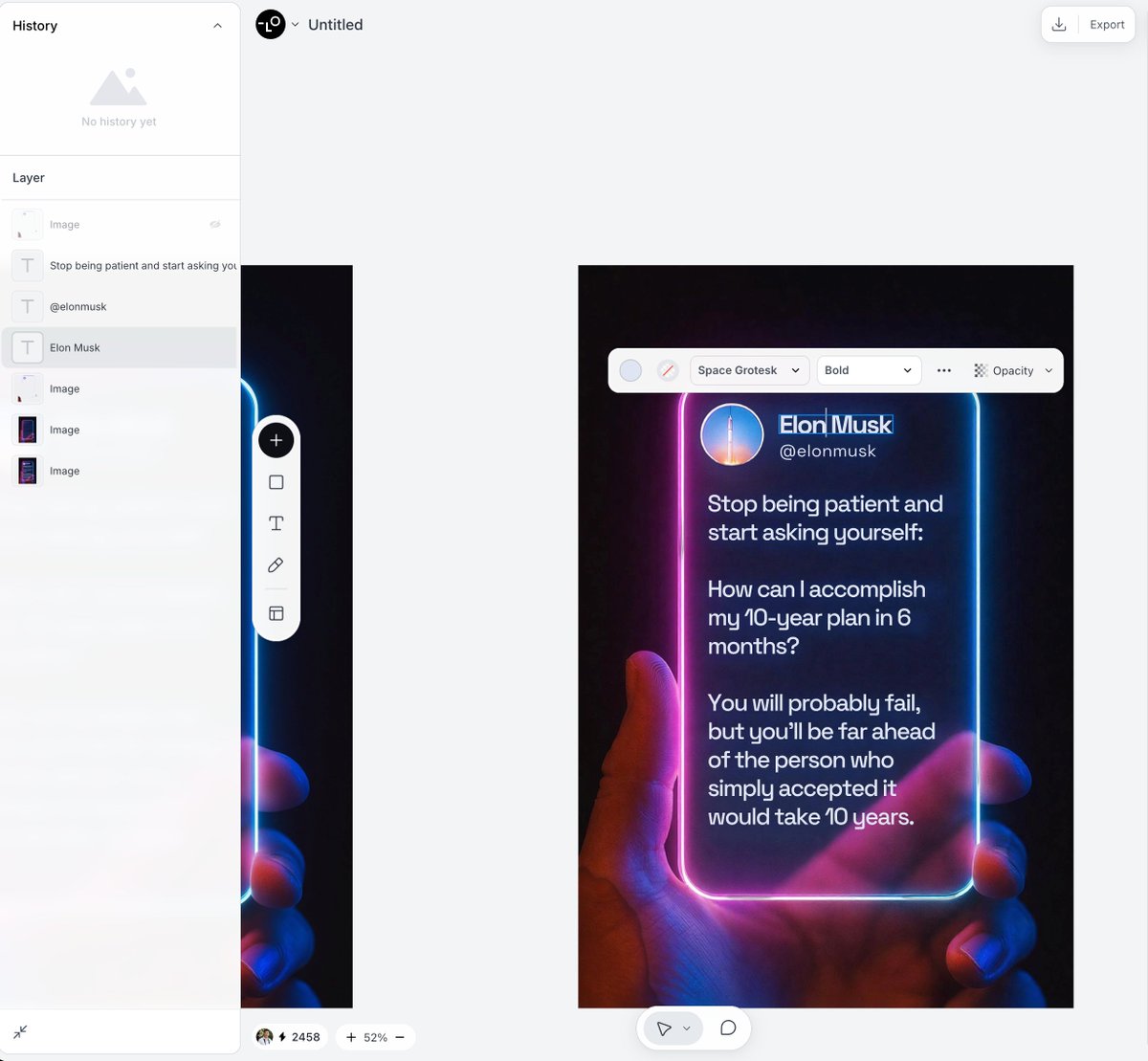
接下來找到頭像圖片、Twitter 認證標籤圖片 在頭像位置加上白色圓形的背景,然後把頭像圖片移除背景後放在頭像位置上,再雙擊文字,替換為其他文字即可。


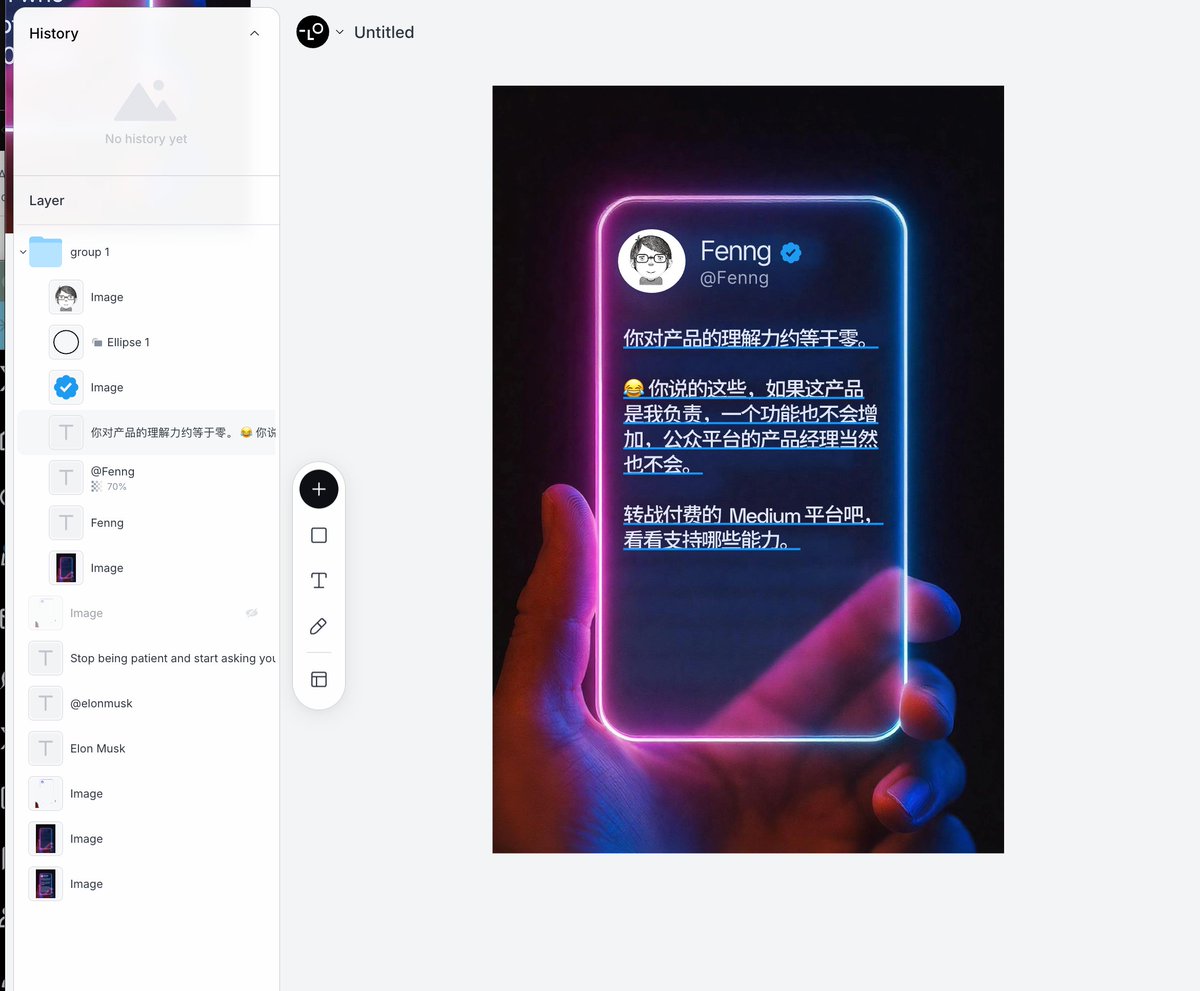
並且有了這個推文模板後,再做其他類似圖片就很容易了,只需要修改文字和替換頭像就可以產生新的圖片。 例如喜歡發納瓦爾寶典的朋友們以後可以用這個模板。

有時候如果頭像不是圓形的要稍微麻煩一點,但也可以讓AI 輔助把頭像變成圓形,選中圖片,然後在Lovart 右側聊天輸入框輸入提示詞: > 把這張圖片按照圓形裁剪,裁剪成一張圓形頭像 下面的模型選擇Nano Banna,提交後,稍等幾秒鐘就能得到一張圓形的高清的新圖片
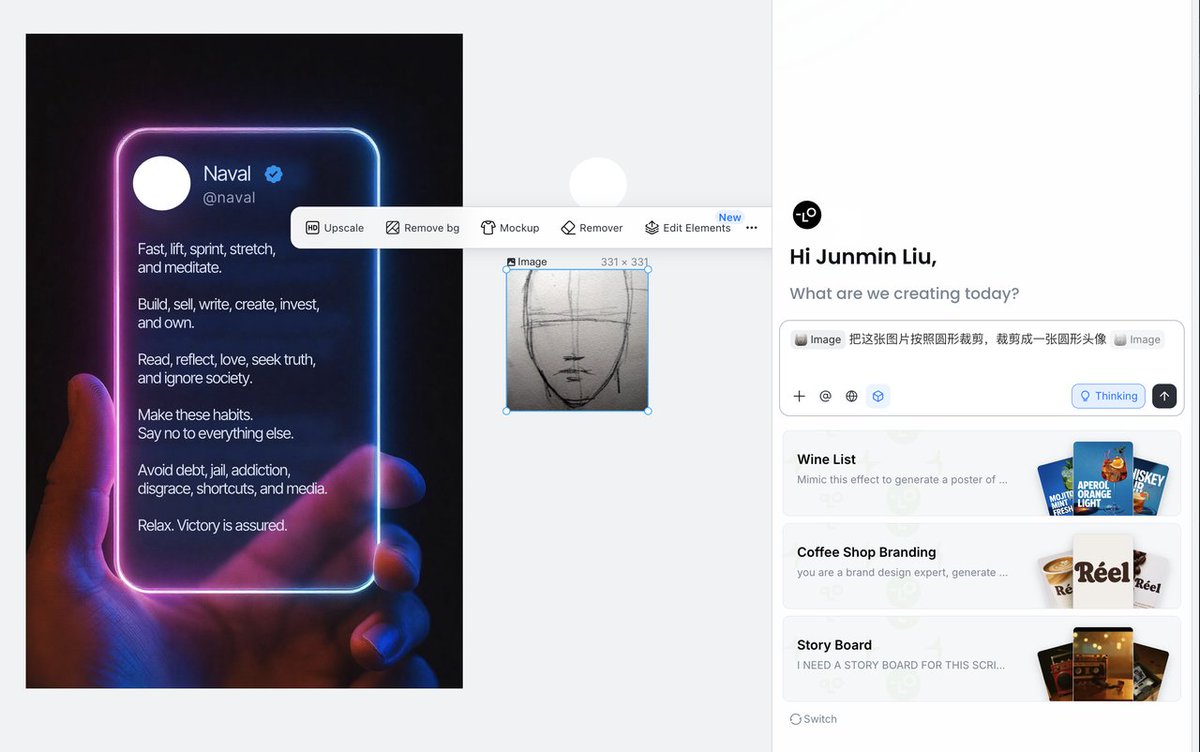

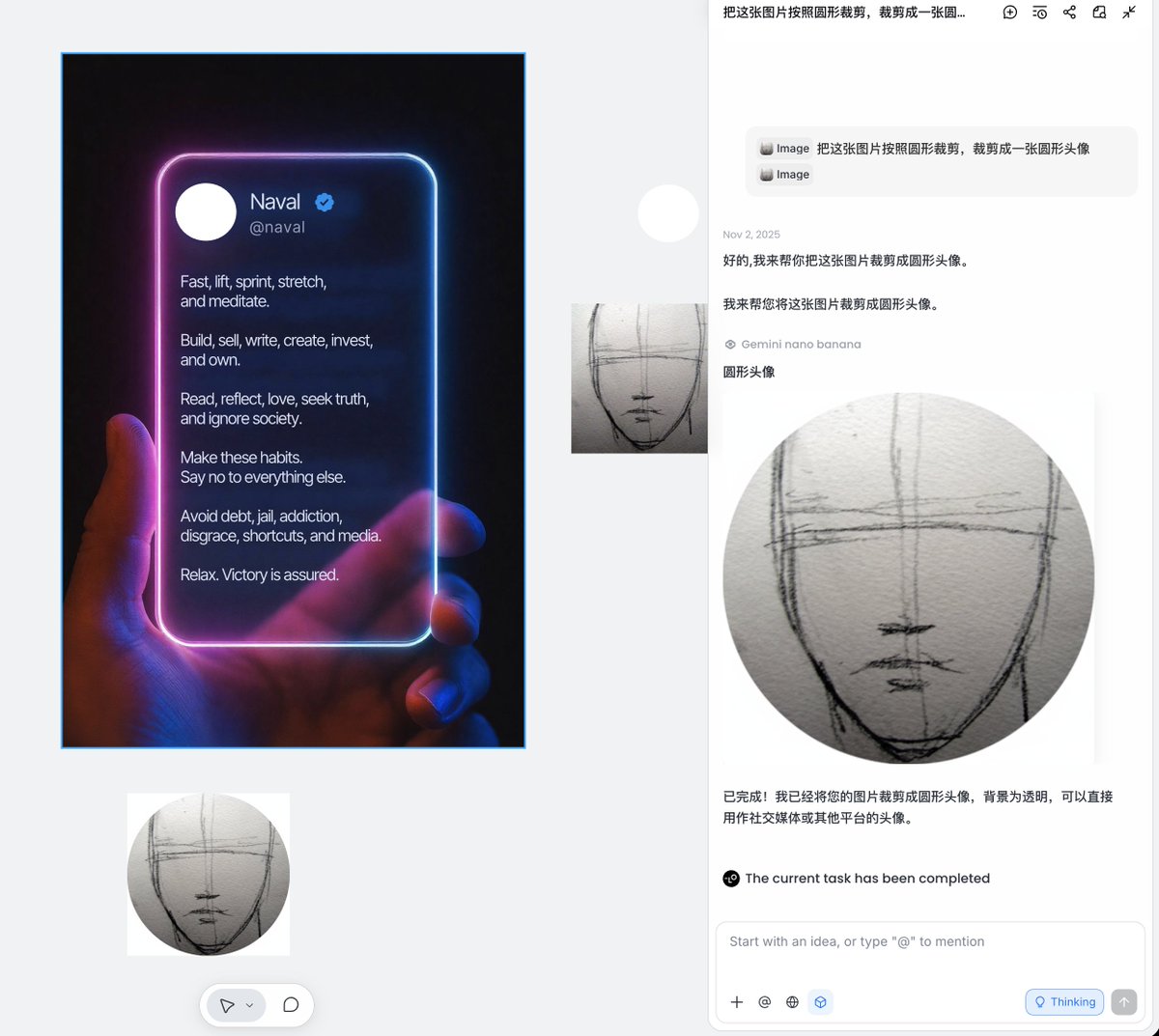
如果得到的圖片不是完全透明,也可以選取圖片,選擇選單中的“Remove bg”,即可得到一張透明背景的圓形頭像圖片。 縮放拖曳到頭像位置後,就大功告成了。

分層編輯還蠻有用的,比如說可以用來編輯海報、翻譯漫畫、摳圖、修改網頁設計等等


從AI Agent 產品設計的角度來說,Lovart 這種做法還是蠻科學的,讓用戶不僅可以用Agent 去生成圖片視頻,也可以讓用戶自己借助分層編輯、移除背景這類工具快速、低成本的完成一些AI 現在還不擅長的工作,比如寫中文文字。
如果說「分層編輯」這類工具是解決後期編輯問題,那麼模型就是前期生成的能力的關鍵,最近引入了兩個新模型: - Hailuo 2.3:是一個“會跳舞的視頻模型”,主打超寫實和場景重構。簡單說,就是生成的影片更真、更穩,動作更複雜。 - LTX 2:是新的開源視訊模型,亮點是能同步產生聲音,而且速度很快。
我測試了下,LTX 2 生成速度確實挺快,生成質量離Sora2 這樣的還有點差距,不過勝在便宜快速,並且能同步生成聲音,可以用來在創作前期低成本驗證一些劇本。
最近Lovart 在做活動,在11 月10 日前(UTC時間)訂閱年包的用戶,會送1 個月兩個新模型(Hailuo 2.3 + LTX 2)的無限使用權。 具體可以看官方網站:https://t.co/DLMGUiV8hK