史丹佛大學的這篇論文值得了解👇🏻 他們建構了一個AI智能體框架,從零數據起步,沒有人工標註,沒有精心設計的任務,也沒有任何演示,但它竟然超越了所有現有的自博弈方法。 這個框架名為Agent0:透過工具整合推理,從零資料中釋放自我進化的智能體。 它所取得的成就令人難以置信。 你之前見過的所有「自我提升」的智能體都有一個致命的缺陷:它們只能產生比它們已經知道的稍微難一點的任務,所以它們會立即達到瓶頸。 Agent0打破了這個天花板。 關鍵在於: 他們從同一個基礎LLM中產生兩個智能體,並讓他們競爭。 • 課程智能體- 產生越來越難的任務• 執行智能體- 嘗試使用推理+工具來解決這些任務 每當執行智能體變得更好時,課程智能體就會被迫提高難度。 每當任務變得更難時,執行智能體就會被迫進化。 這創造了一個閉環、自我強化的課程螺旋,而且這一切都是從頭開始的,沒有數據,沒有人,什麼都沒有。 只是兩個智能體互相推動,達到更高的智能水準。 然後他們添加了作弊碼: 一個完整的Python工具解釋器在循環中。 執行智能體學習透過程式碼來推理問題。 課程智能體學習創建需要使用工具的任務。 所以兩個智能體都在不斷升級。 結果呢? → 數學推理能力提高+18% → 一般推理能力提高+24% → 擊敗R-Zero、SPIRAL、Absolute Zero,甚至使用外部專有API的框架→ 所有這些都來自零數據,只是自我進化的循環 他們甚至展示了難度曲線在迭代過程中上升:任務從基本的幾何開始,最終達到約束滿足、組合、邏輯謎題和多步驟依賴工具的問題。 這是我們所見過的最接近LLM中自主認知成長的東西。 Agent0不僅僅是「更好的RL」。 它是智能體引導自身智能的藍圖。 智能體時代已經解鎖。

開始閱讀前,記得按讚、轉發或收藏 本Threads內容由人機協同內容引擎發布 https://t.co/Gxsobg3hEN
核心思想:Agent0從同一個基礎LLM創建兩個智能體,並迫使它們進入競爭性的回饋循環。一個發明任務,一個試圖生存。這種持續的推拉產生的前緣難度問題是任何靜態資料集都無法比擬的。
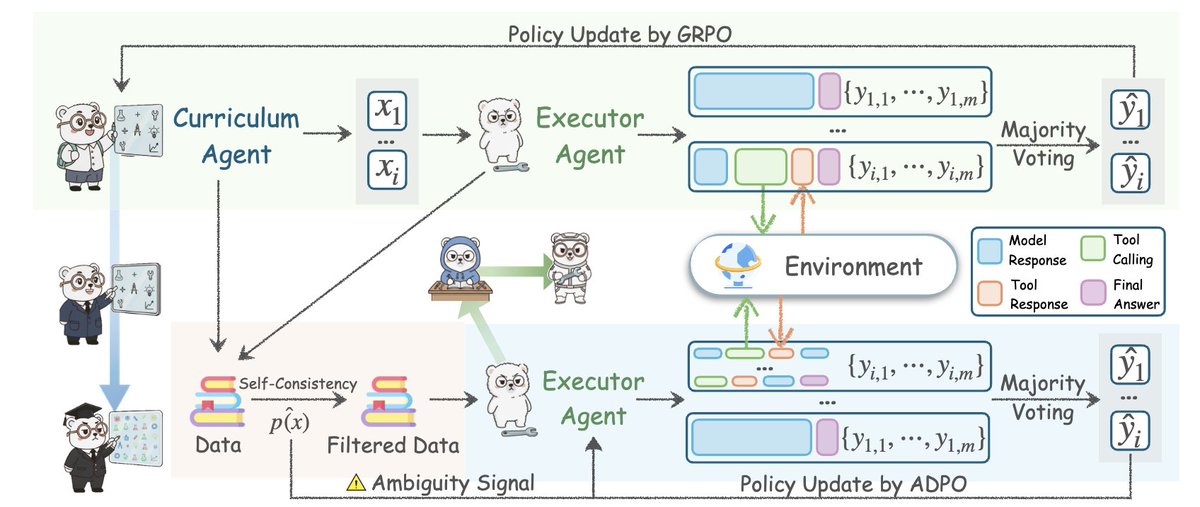
突破不在於自博弈,而在於工具整合推理。執行智能體可以在解決方案中運行真正的Python程式碼,獲得輸出,並更新其推理。這使得課程智能體透過製作需要使用工具的問題來回應。一個良性循環。

他們解決了自進化智能體的最大失敗模式:停滯。大多數智能體只產生比他們目前水準稍微難一點的問題。 Agent0使用不確定性、取樣答案之間的分歧和工具呼叫頻率來檢測執行智能體的弱點。在此處閱讀完整論文arxiv.org/abs/2511.16043w

我個人理解,這其實就是利用LLM構建兩個Agent來進行對抗其實也是一種GAN的思維邏輯換句話說,發展就是在不斷解決陰陽對沖的過程中形成的但想讓這個系統運轉逃離不開給Agent賦予“搜索&創造工具”的能力只要有這個能力,Agent就可以通過RL不斷去解決人類碰撞
最後,感謝你花時間閱讀了這篇推文! 關注@Yangyixxxx ,分享AI信息,商業洞察與增長實戰 如果你喜歡這篇內容,也請按讚並轉發第一條推文,把有價值的內容分享給更多人~