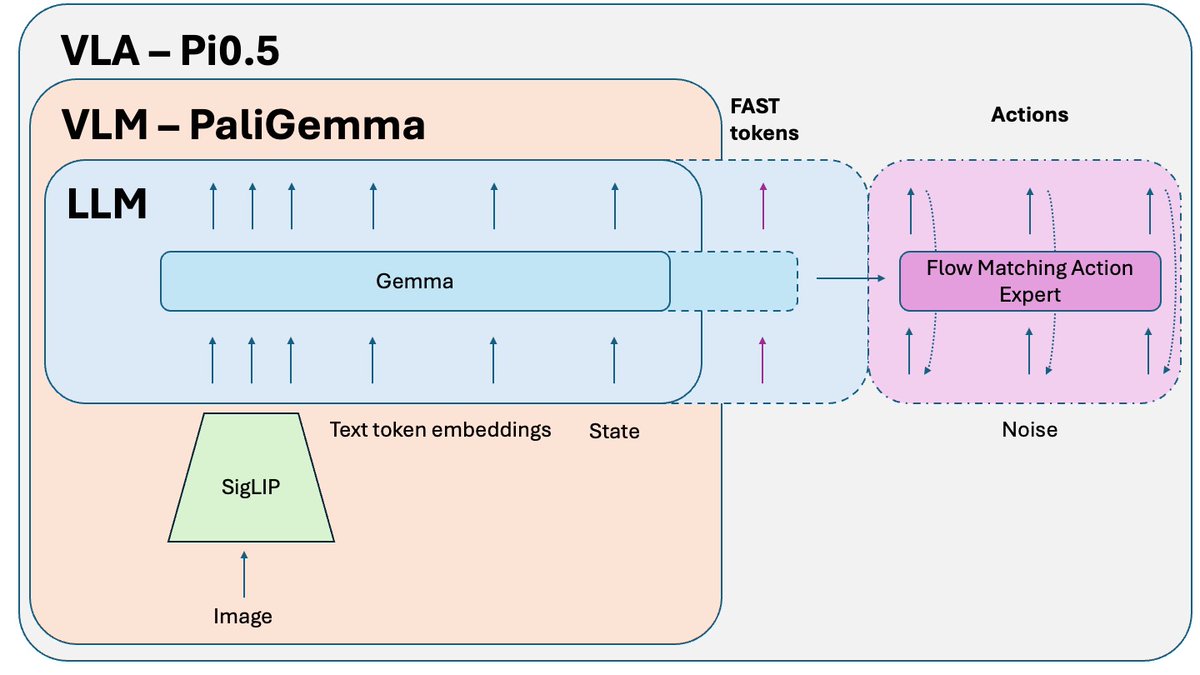
@physical_int 的 Pi0.5 是目前最好的开源端到端机器人策略之一🤖 它是 Pi0 的升级版,最新的 Pi 技术都是基于它开发的。我们来探讨一下它的工作原理:
与 Pi0 相比,有哪些变化? - FAST 分词 - Pi0 上有一个可选的 FAST 版本,但对于 Pi0.5 来说,它是训练过程中必不可少的一部分。 - 系统 2 - 根据 Hi Robot 论文,Pi 0.5 使用其 VLM 部分作为推理高级系统 2,用于推理和规划复杂任务。 - 更完善的训练方案和一些小的调整。
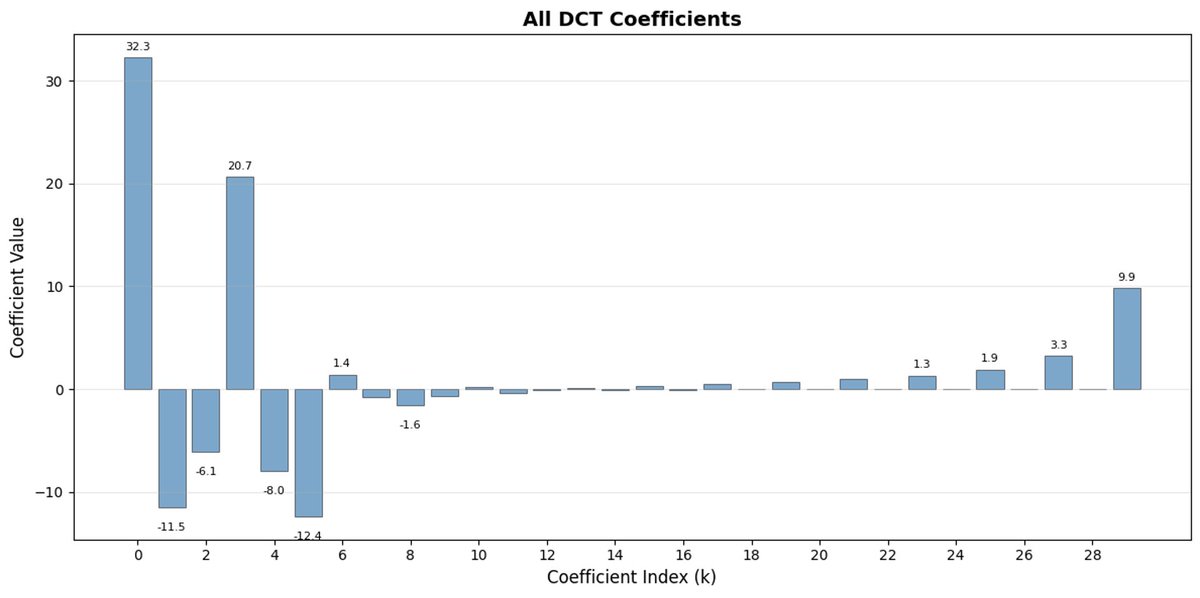
FAST 是一种分词方法,它使用 DCT(离散余弦变换)和 BPE(字节对编码)将动作序列压缩成信息非常密集的离散标记。 DCT 是 JPEG 图像压缩中使用的同一种算法。 它将信号表示为不同频率的余弦函数之和。前几个分量捕捉信号的整体趋势和形状,其余分量则捕捉越来越多的细节。 渐进式 JPEG 首先发送低频分量,图像看起来模糊,然后随着分量的增加而逐渐清晰。



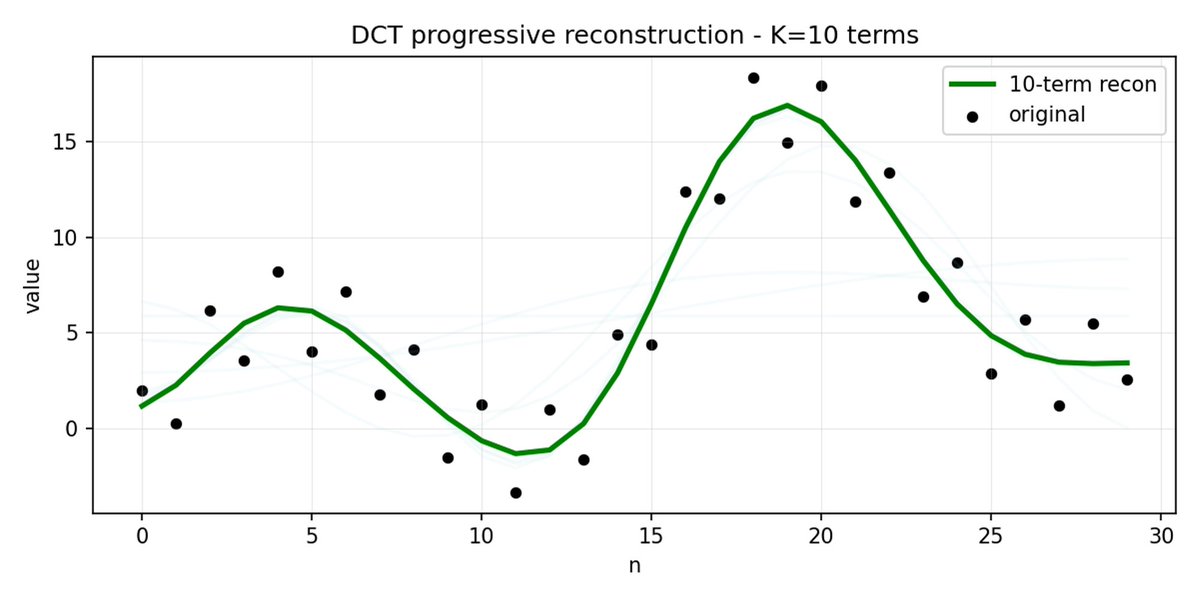
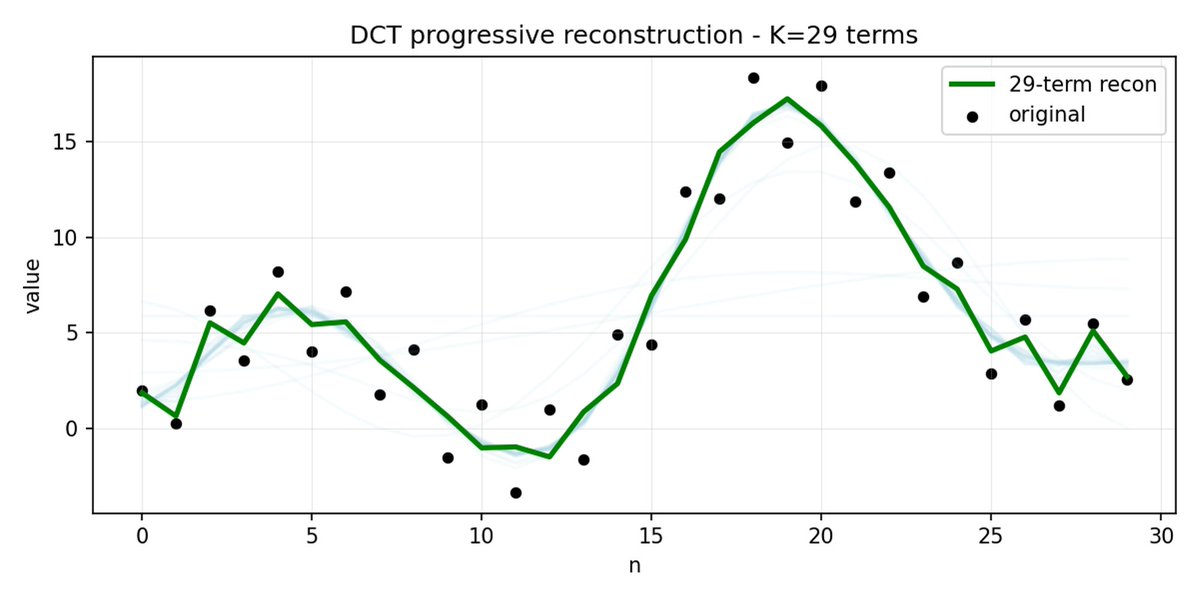
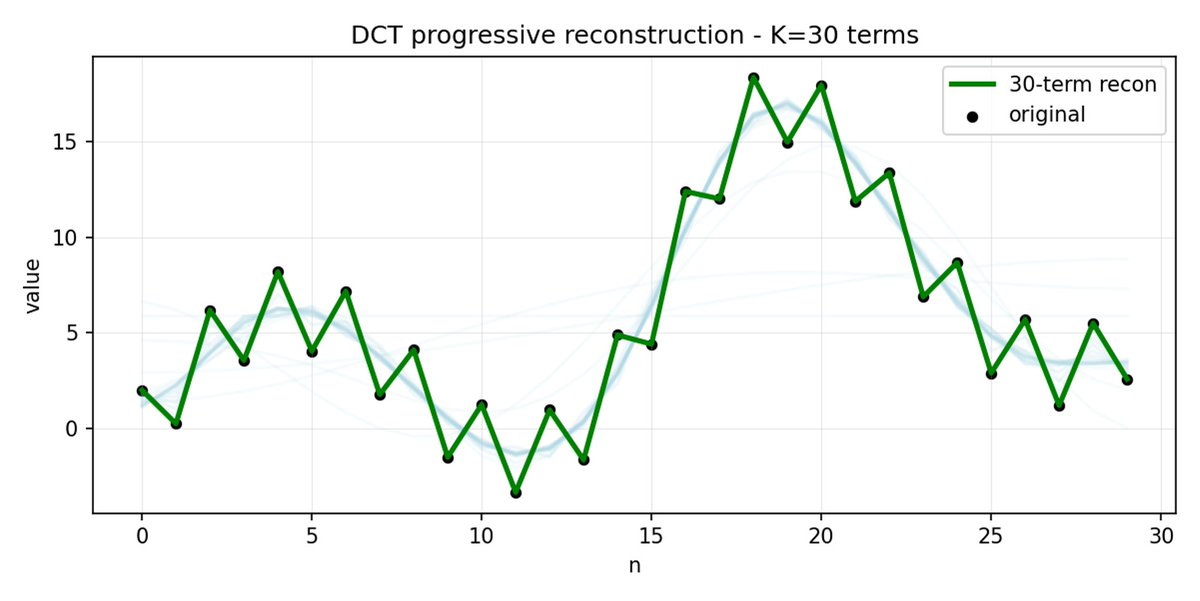
FAST 对动作块也执行相同的操作。 与其预测 30 个相关的行动值,不如预测一个更短、更有意义的表示。 通常情况下,你只需要保留几个主要系数(其中包含原始信号的大部分能量),仍然可以很好地重建轨迹。
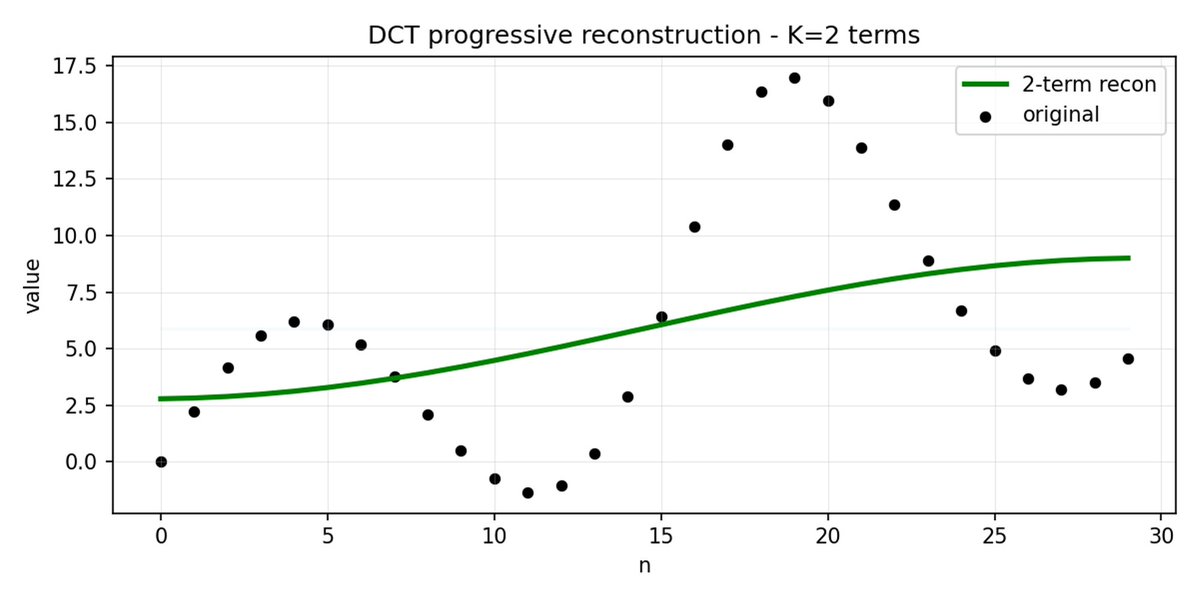
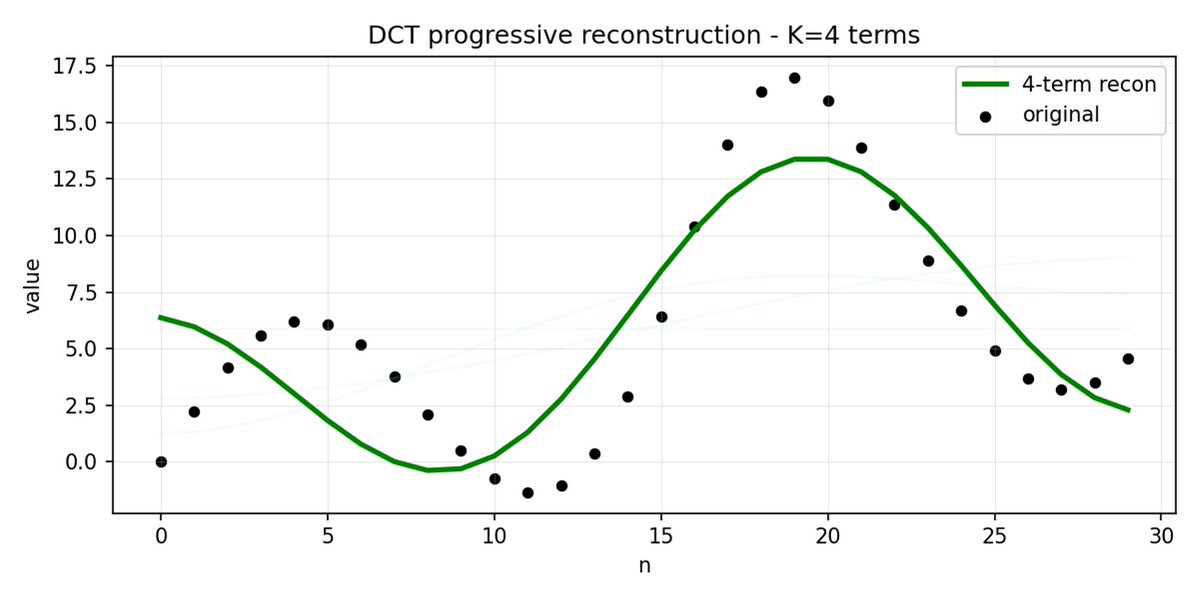
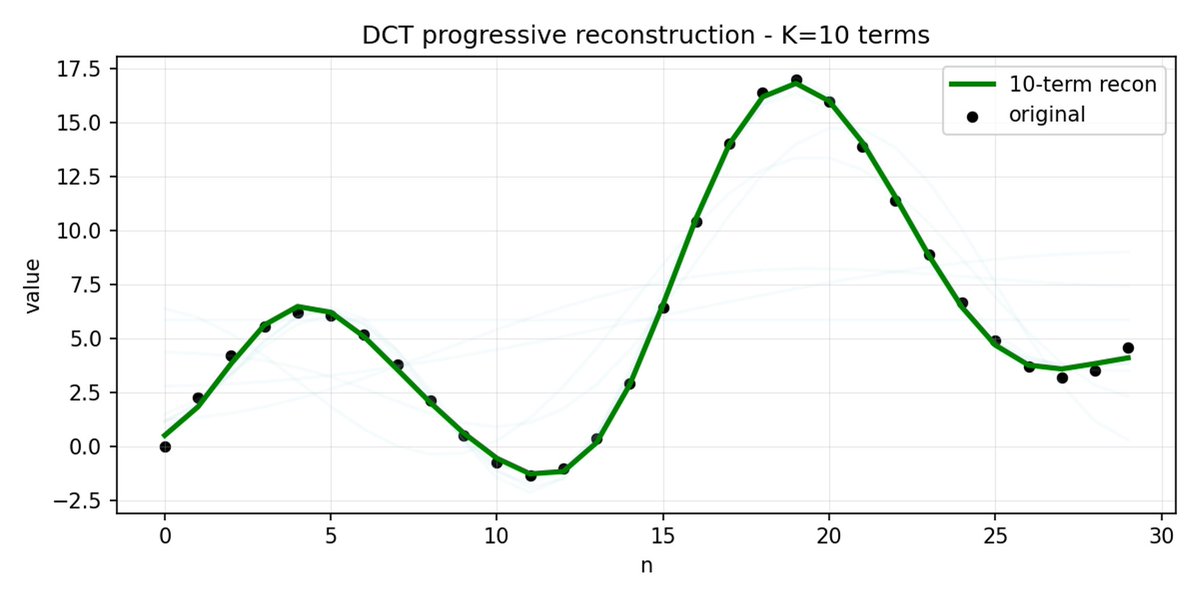
字节对编码 (BPE) 是 LLM 中最常用的分词方法。 它会查找最常见的词对,并将它们合并成单个词。 当应用于量化 DCT 时,许多高频分量的 0 系数以及不同关节的常见组合运动被合并到单个标记中,从而导致强压缩。
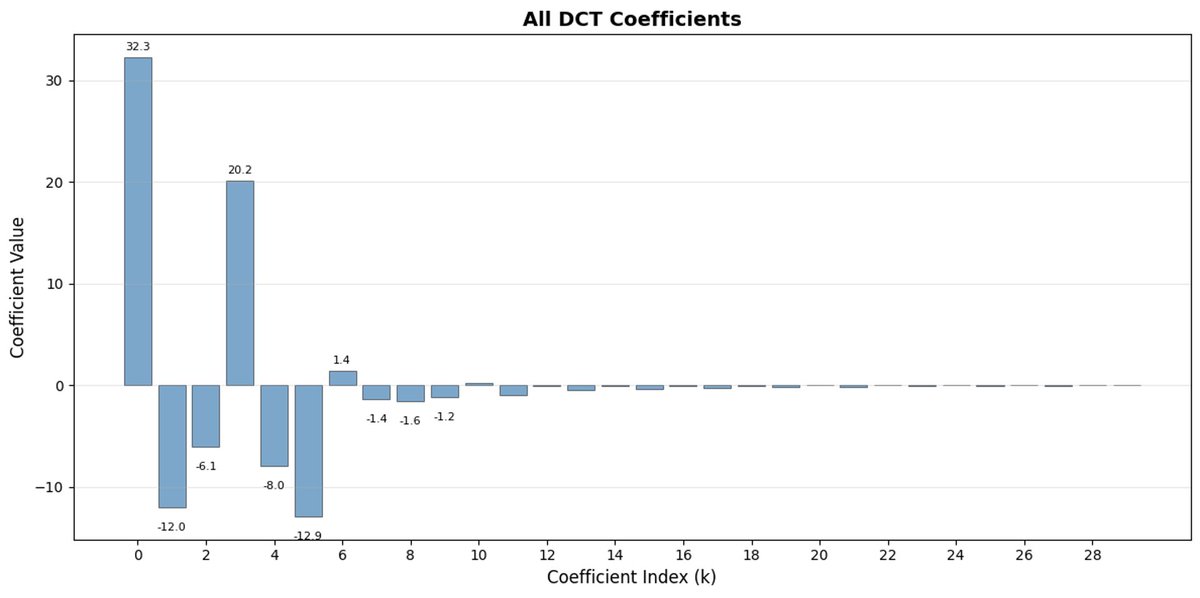
如果您的动作存在高频噪声(例如每个时间步的归一化伪影),FAST 的压缩效果可能会很差,系数不再接近于零,压缩效果也会下降。 真实机器人数据通常是平滑的,所以大多数情况下都没问题——只需注意数据预处理即可。
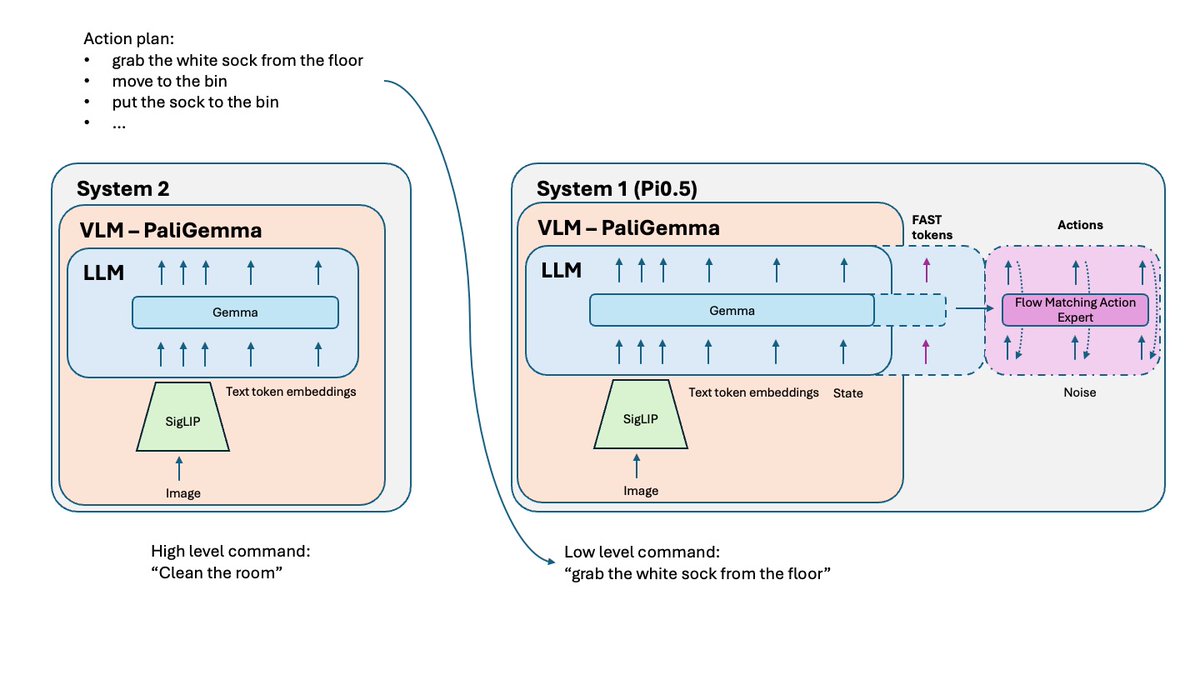
基于简单任务训练的 VLA 策略,在将这些任务组合成复杂的、长期的问题时可能会遇到困难。 为了解决这个问题,需要用到更高级别的系统 2。Pi0.5 使用与系统 1 (VLA) 相同的 VLM,但调用频率要低得多,用于推理问题并定义下一步操作。之后,该指令会被发送给系统 1 执行。
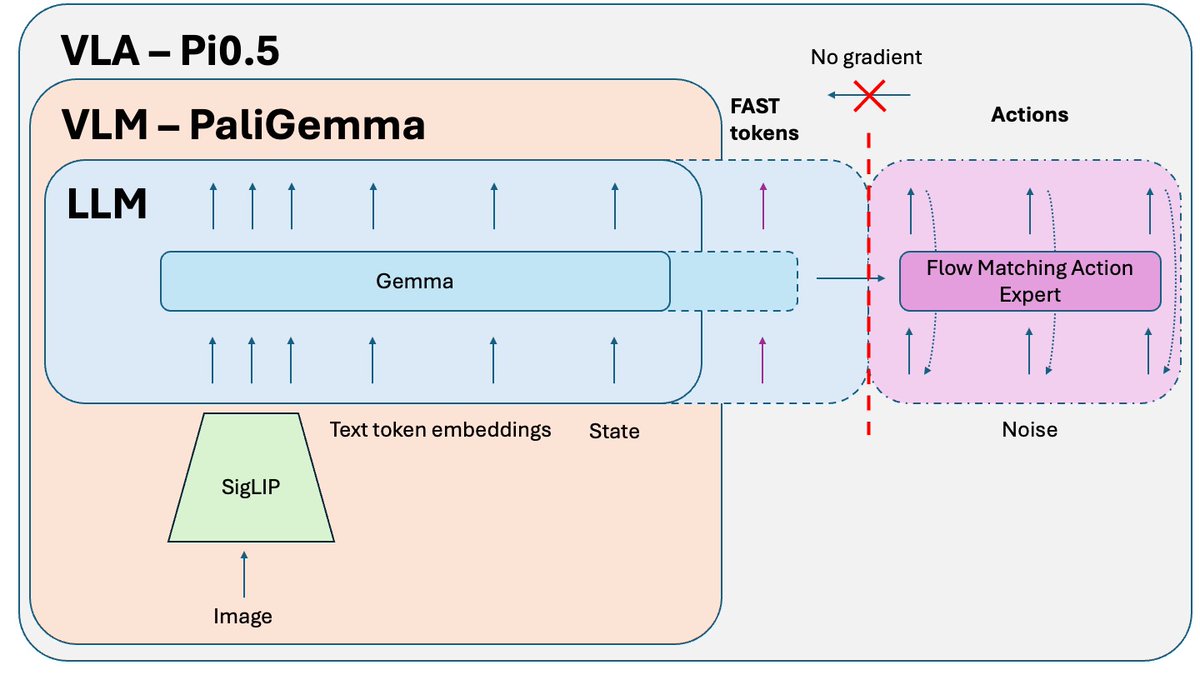
在 Pi0.5 论文之后发布的一个额外技巧,用于训练该模型的开源版本,是知识隔离。 当您联合训练 VLM 部分(已在互联网规模数据上预训练)和动作专家(随机初始化)时,来自动作专家的噪声梯度会破坏 VLM 的预训练结果。它会逐渐遗忘其预训练的知识。 解决方法是将梯度与动作专家隔离,并允许它仅影响动作专家权重,同时在 FAST 动作标记 + 相关非动作数据上训练 VLM。
推理过程中的另一个问题是,由于分块处理,运动不平滑。 模型预测下一个数据块,执行它,然后暂停以预测下一个数据块(如下视频,3 倍速)。 如果在前一个代码块执行之前尝试预测下一个代码块,而模型在执行一个截然不同的操作模式时跳转到另一个操作模式,则可能会导致致命的错误。 解决方案是图像修复——这通常用于图像生成。我们可以在执行上一个数据块的同时预测下一个数据块,但我们会强制新的预测与前一个数据块的结尾完全匹配。 其结果是运动更加流畅,没有跳跃和停顿,并且模型的性能和吞吐量更高。
如果你想深入了解(包括图片、演示和微调说明),请观看我的新视频:https://t.co/TDdhedJiDn