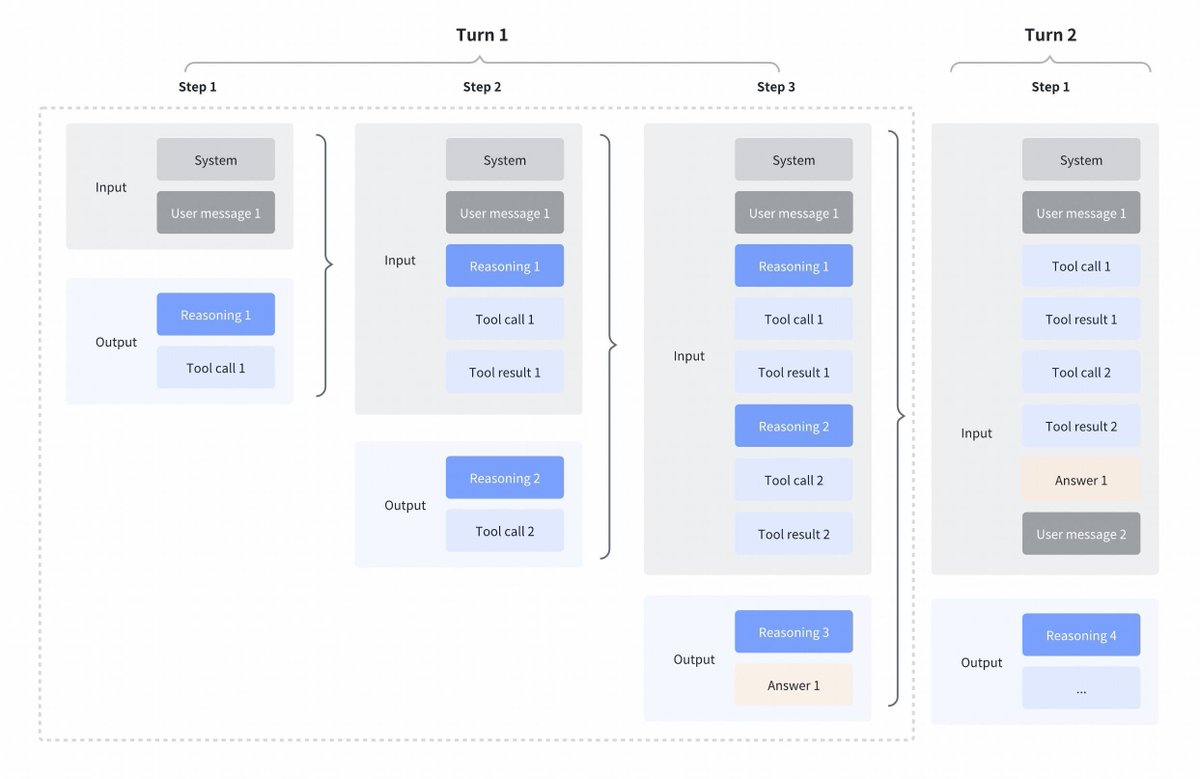
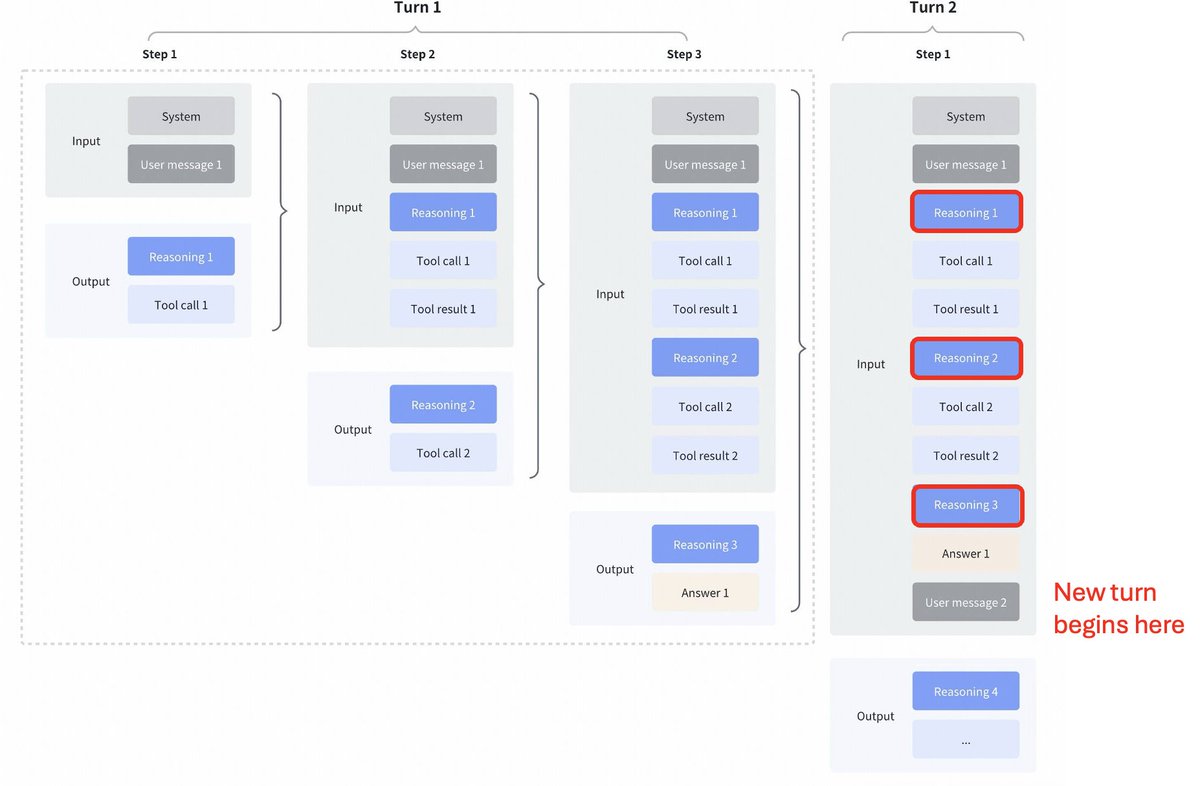
Interesting change of strategy by GLM4.7 compared to Kimi K2 Thinking, DeepSeek V3.2 and MiniMax M2.1 Interleaved thinking between tool calls: All these models supported interleaved thinking for tool calls, but they clear thinking from the previous turns as can be seen in the first screenshot below. Preserved thinking in GLM 4.7: Compare to that GLM 4.7 (for coding endpoints alone) preserves reasoning from previous turns, as can be seen in screenshot below (note red blocks) For the other api endpoint, the behaviour is same as before(discard reasoning from previous turns). This is sure to boost some performance, as the model will have past context. As @peakji, advises models need their past thought process to make good decision later. This is anti-context compression, but I guess for coding scenarios may be well worth it. I wish they made it configurable, so we could see impact ourselves.