从失败中重生:前端人工智能代理落地案例的真实回顾 今天在FEDay大会上,我分享了一个关于实现前端代理的案例研究。核心内容并非庆祝胜利,而是讲述一个团队如何从“技术成功”走向“产品失败”,以及这次失败如何促使我们对认知框架进行关键性升级。 这个故事的价值不在于成功的方法论,而在于我们遇到的陷阱以及我们思维的演变。

2025年被誉为“智能体之年”。随着Deep Research、Manus和Claude Code的发布,科技界一片沸腾。 许多团队都在问同一个问题:“我们应该构建一个代理吗?”

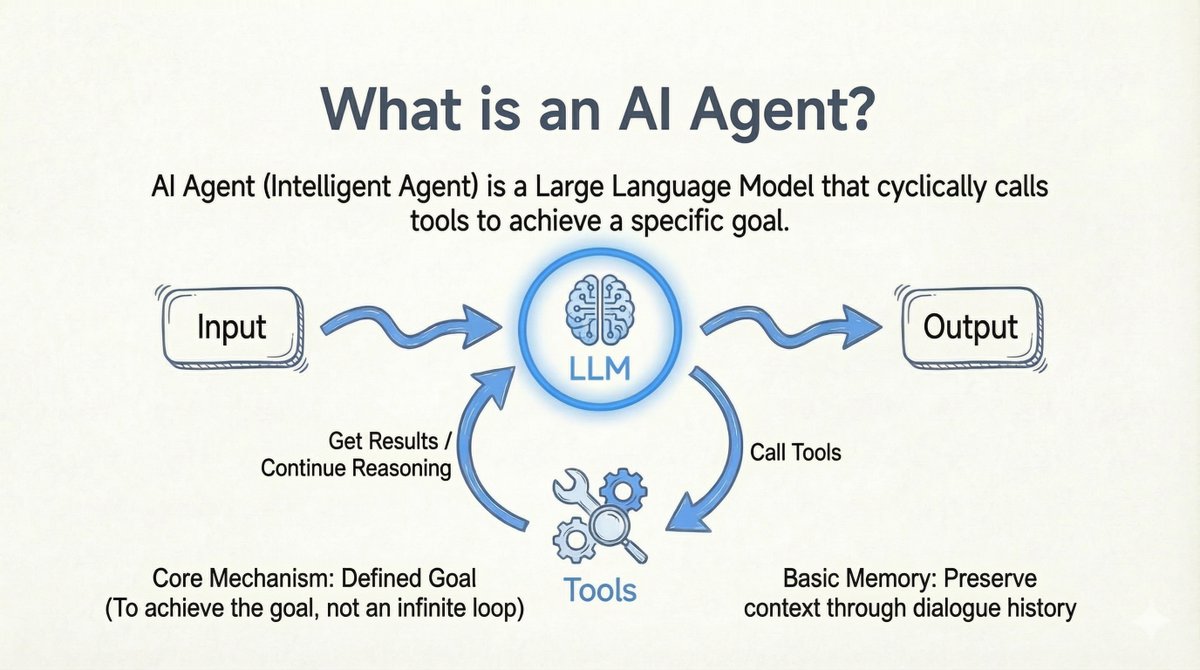
在深入探讨之前,让我先明确一下我对人工智能代理的定义: > AI 代理:一个大型语言模型 (LLM),它循环调用工具以实现特定目标。 - 循环中的工具:模型调用工具 -> 获取结果 -> 继续推理。 - 明确终点:它的目的是实现一个目标,而不是无限循环。 - 灵活的目标来源:目标可以来自用户或其他LLM。 - 基本记忆:通过对话历史记录保持上下文。
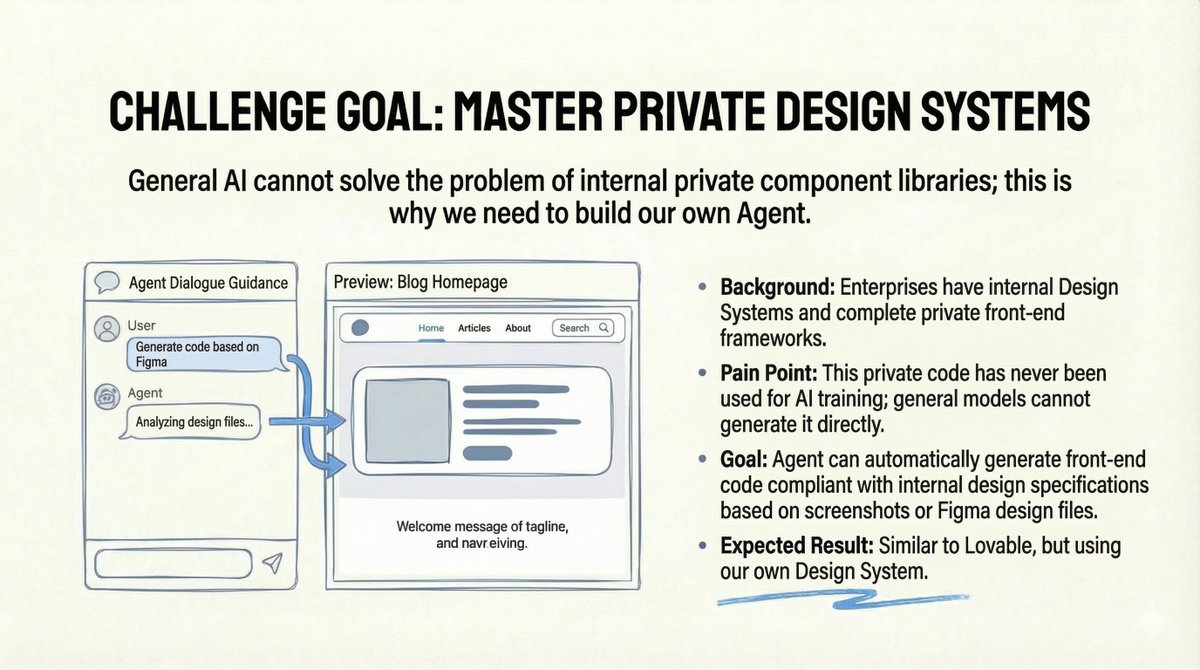
挑战:私有设计系统 朋友的团队正面临着一个企业级的难题:公司拥有一套完整的内部设计系统和一个私有的前端框架。然而,由于这些代码是私有的,因此从未有公开的AI模型基于这些代码进行训练。通用模型根本无法生成符合其内部规范的代码。 目标很明确:打造一款类似“Lovable”的工具,但采用他们自己的设计系统。用户可以上传 Figma 设计稿或屏幕截图,代理程序会自动生成符合内部标准的前端代码。 听起来很完美,对吧?
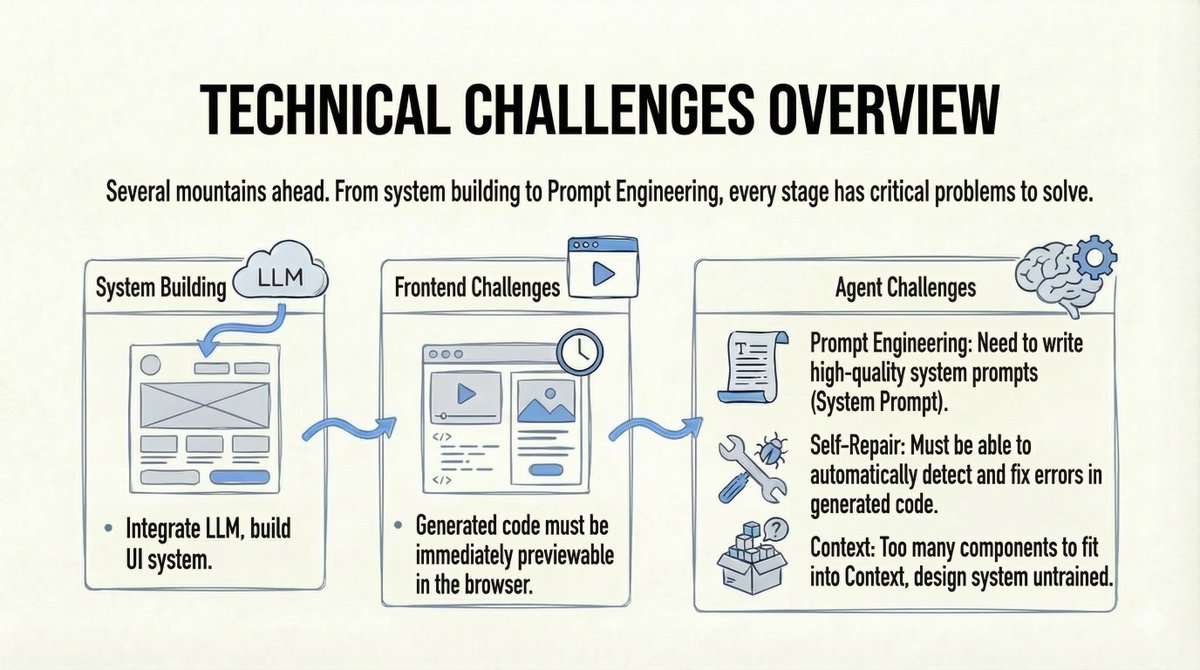
现实检验:挑战是巨大的: 1. 构建一个完整的代理系统比看起来要难得多(用户交互、上下文工程等)。 2. 该模型必须理解和使用它从未见过的私有组件。 3. 我们需要实时浏览器预览生成的代码。 4. 如果代码出现故障,我们需要自动修复功能。
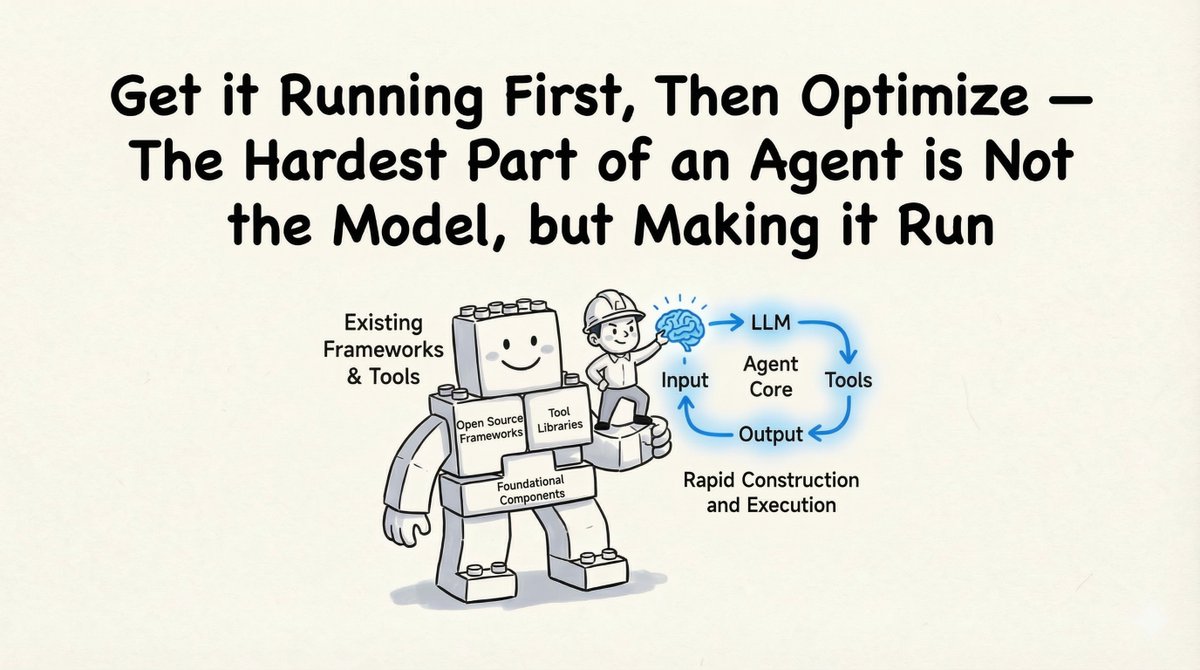
技术上的成功:我们是如何实现的 作为一名技术顾问,我给出的第一条建议非常务实:“先让它运行起来,再进行优化。”构建代理程序并不是最难的部分;完成整个执行循环才是。
1. 基础:Claude Agent SDK 我们没有重新发明轮子,而是基于 Claude Agent SDK 进行开发。 - 已证实:克劳德·科德证明了这种架构是可行的。 - 即用型:内置工具涵盖 90% 的场景。 - 可扩展:支持自定义工具、MCP(模型上下文协议)和自定义技能。 (您可以在这里找到一些开源的原型代码:https://t.co/eon1eb3ECD)

2. 预览方案:本地文件系统 我们最初尝试使用 Sandpack(基于浏览器的沙箱)进行代码预览,但它在处理复杂的私有组件时表现不佳。转折点:我们为代理程序提供了一个本地文件系统(每个会话一个虚拟机或目录)。这使得代理程序可以自由地读取、写入、修改和编译代码。
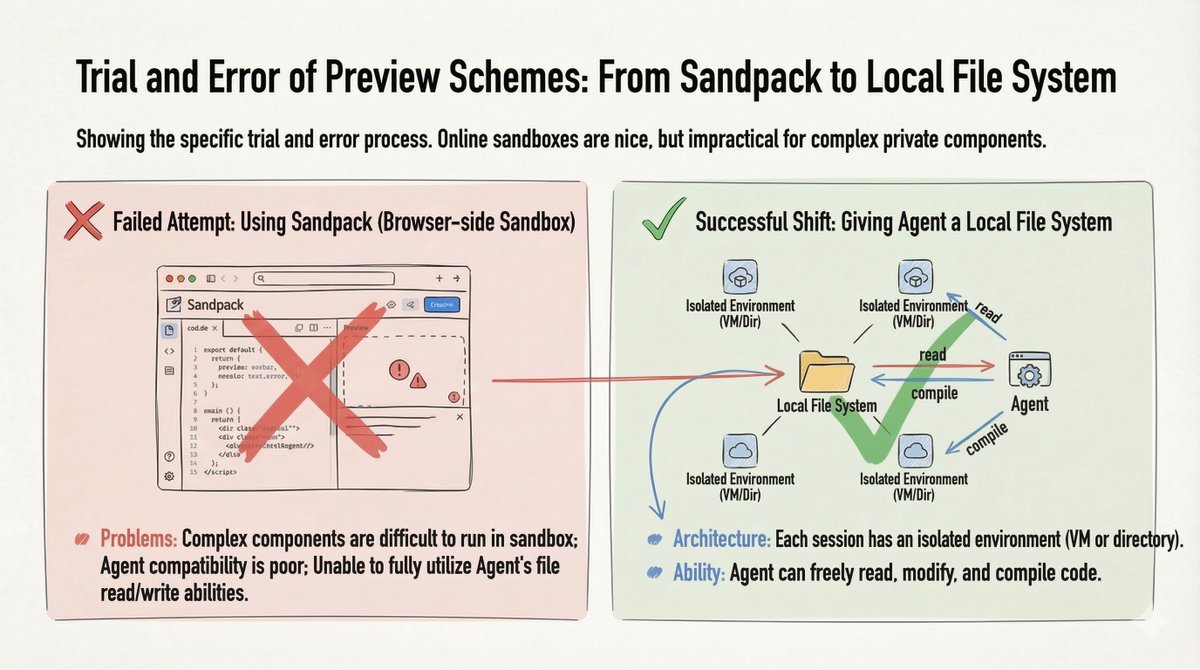
为代理程序提供本地文件系统是最大限度发挥其功能的唯一途径。

3. 解决“未知组件”问题 如何教会人工智能使用它从未见过的组件库? 像对待新员工一样对待它。我们将设计系统规范、组件列表和 API 文档转换成了 Markdown 格式。 无需复杂的 RAG:我们只需允许代理对本地文档和“高质量参考代码”执行文件检索即可。

4. 质量保证:验证循环 为了确保代码真正有效,我们构建了一个自动化循环:生成 -> 验证 -> 修复 - 工具:静态代码检查、编译检查和可视化差异比较(使用 Chrome DevTool MCP)。 - 优化:我们将验证工具放置在 Skill 或 SubAgent 中,以避免污染主 Agent 的上下文窗口。

“产品失败”:上市后的沉默 系统运行正常。演示效果惊艳。我们正式上线后……几乎没人使用。 最初的新鲜感过后,用户流失率飙升。我们进行了深入的分析和用户访谈,意识到问题不在于技术,而在于产品逻辑与用户习惯的不匹配。
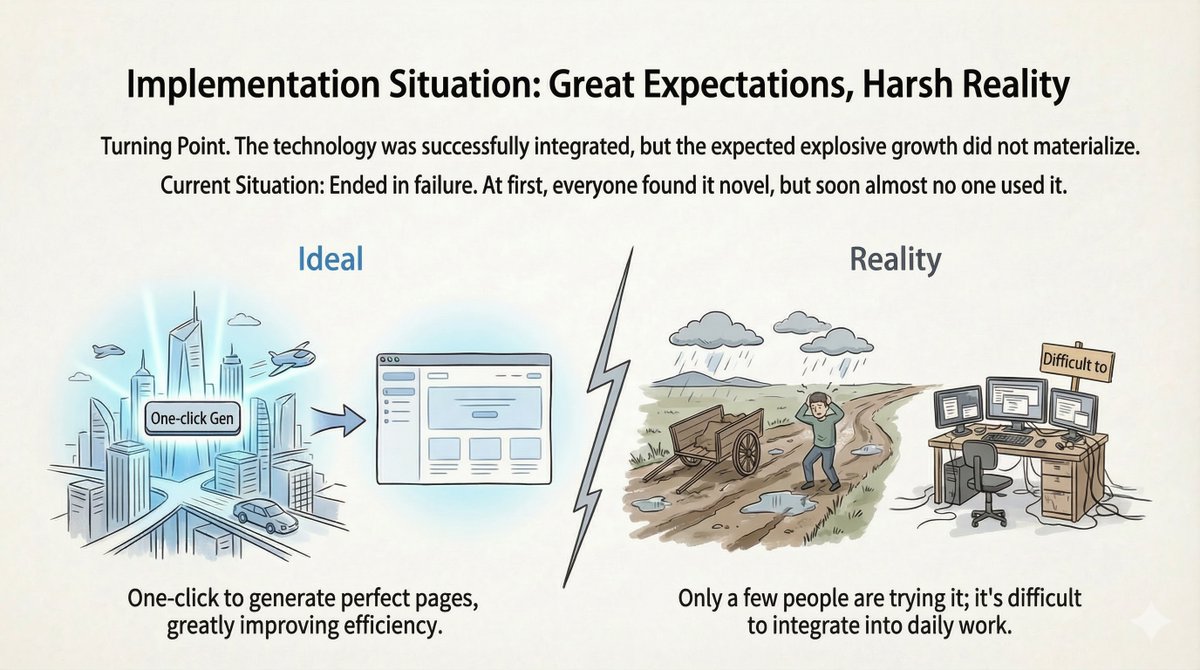
它失败的原因 1. 习惯阻力:设计师和项目经理习惯使用 Figma,而不是聊天窗口。从舒适区过渡到对话式界面是一个巨大的阻力点。大多数人甚至不知道该输入什么。 2. 80/20 瓶颈:代理程序完美地完成了 80% 的工作。但剩下的 20% 需要手动修改,这极其耗费精力。通常,这 20% 的工作决定了代码是否可用。 3. 工作流程碎片化:生成环境与实际开发环境脱节。开发人员必须手动复制粘贴代码,使过程变得繁琐。

认知升级:重新定义问题 我们意识到我们问错了问题:“我们如何构建一个设计系统人工智能代理?”这使得代理本身成为了目标,而不是手段。 正确的问题是:“我们的设计系统的最终目的是什么?” 1. 全企业统一的设计规范。 2. 提高了开发效率。

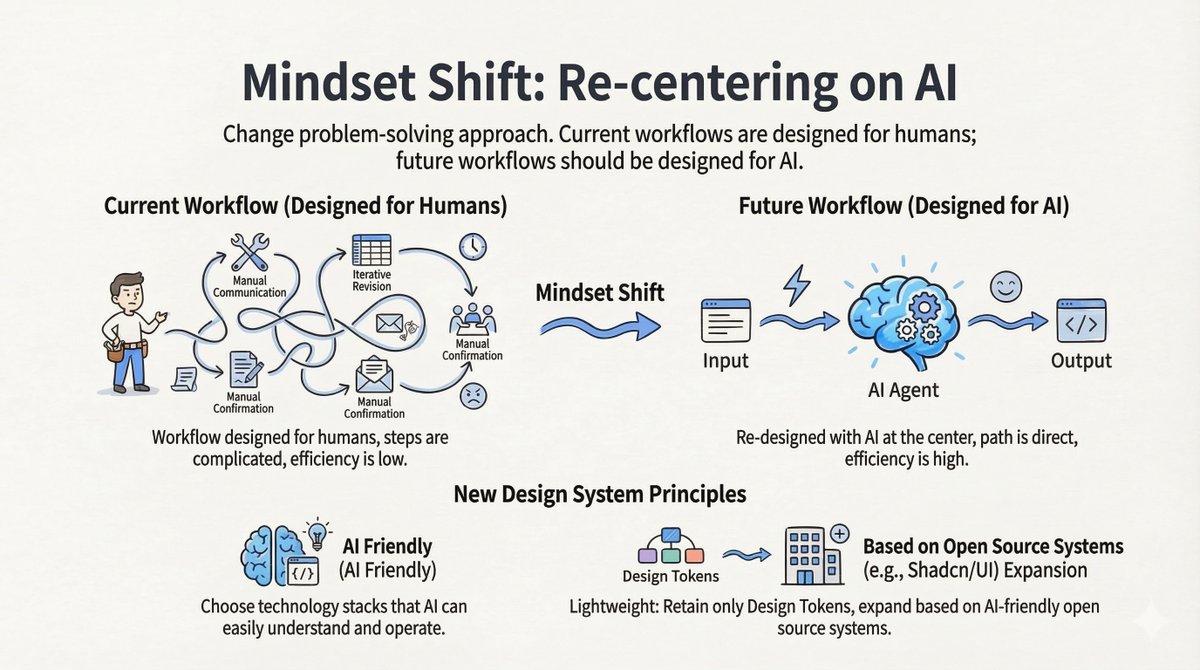
转变一:为人工智能设计,而非为人类设计 当前的工作流程以人为中心:人工沟通、迭代修改、人工确认。未来的工作流程必须以人工智能为中心:输入 -> 人工智能代理 -> 输出。 新的设计原则: - 对人工智能友好:选择法学硕士容易理解的技术栈。 - 轻量级:仅保留设计令牌。基于对人工智能友好的开源系统(如 shadcn/ui)进行扩展,而不是维护庞大的私有库。
第二阶段:从“代理人”到“技能人员” 最关键的转变是放弃了“独立代理平台”。 旧模型(孤岛):与开发者隔离的独立代理,造成摩擦。 新模型(集成):将设计系统变成可以嵌入到现有 AI 开发环境(如 Cursor 或 Claude Code)中的技能。

什么是技能? 它其实就是 Markdown 文档(供 AI 阅读)+ 自动化脚本(用于初始化项目和安装系统)。 现在,开发人员在他们熟悉的环境中工作。当他们需要设计系统时,通用代理会调用这个“技能”,生成的代码会直接进入项目代码库。 (参考方法:anthropics/skills/tree/main/skills/web-artifacts-builder)

深度洞察:4 个关键要点 技术成功 ≠ 产品成功 很多工程师(包括我自己)都会陷入“只要能用就成功”的误区。用户并不关心你的技术栈;他们只关心你的技术能否解决他们的问题,并且不会打断他们的工作流程。 2. 设计“以人工智能为中心”的工作流程 我们常说“以用户为中心”,但我们必须加上一个层面:“以人工智能为中心”。不要让人工智能模仿人类的工作流程,而是要重新设计工作流程,使人工智能能够以最高效率运行,然后让人类享受成果。 3. 技能 > 代理人 独立代理平台面临着很高的普及门槛。将功能封装成可接入现有生态系统的技能,是一种更为务实的途径。 4. 行动 尽管最初的产品“失败”了,但认知上的提升却是无价的。不亲身实践,就无法学会从“人类工作流程”过渡到“人工智能工作流程”。
动手建造吧! 失败是可以接受的。它远胜于什么都不做。
