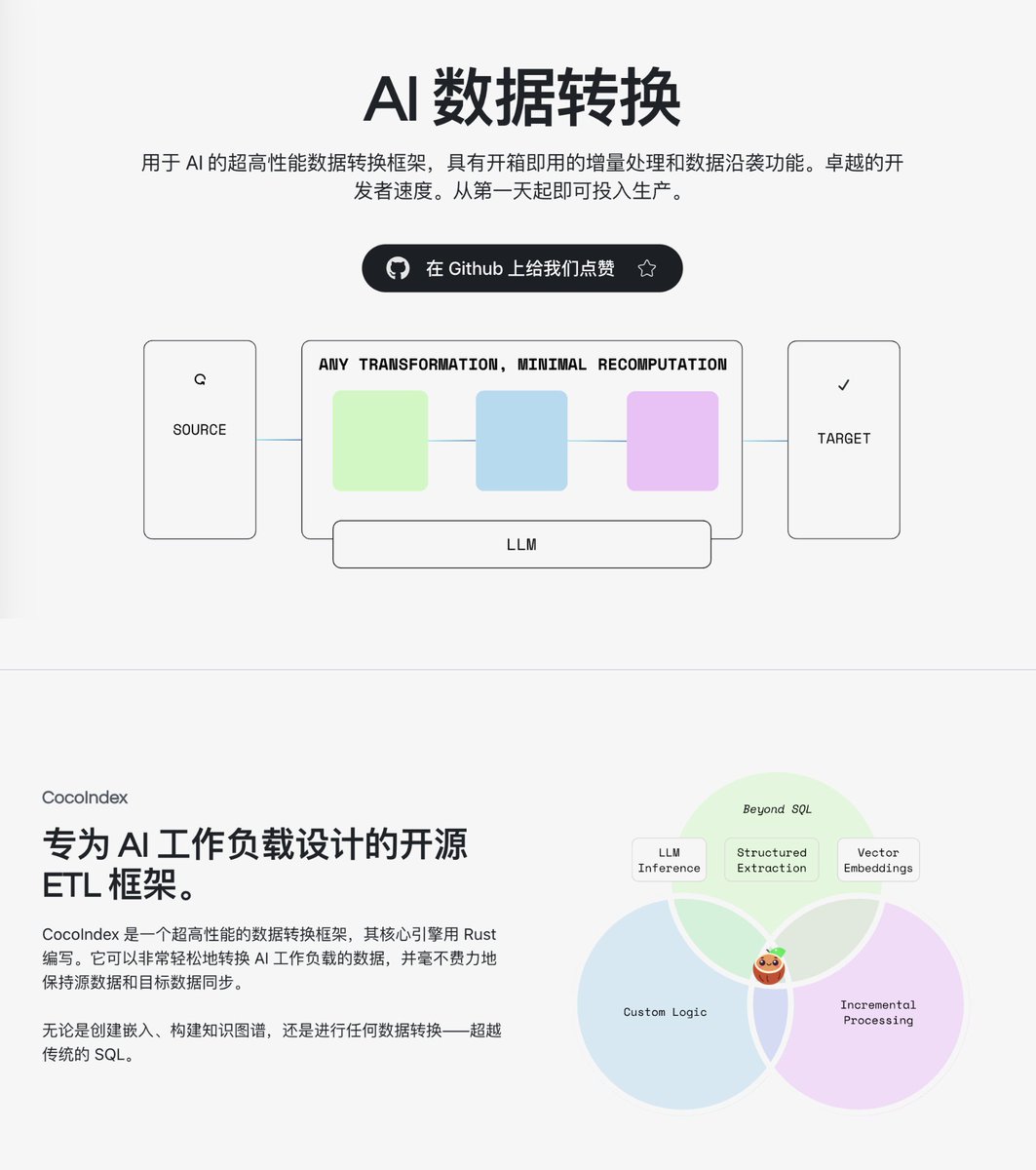
Ao desenvolver aplicações RAG ou construir bases de conhecimento, a parte mais problemática geralmente não é a seleção do modelo, mas sim o fluxo de processamento de dados. Isso exige a escrita de vários scripts em Python para limpar, segmentar e vetorizar os dados, e se os dados de origem mudarem, executar todo o processo novamente é demorado e caro. Recentemente, descobri o projeto de código aberto CocoIndex no GitHub, uma estrutura de transformação de dados de alto desempenho projetada especificamente para cenários de IA. Com apenas cerca de 100 linhas de código Python, você pode definir todo o processo, desde a leitura e divisão do arquivo em partes até a inserção do vetor na biblioteca. GitHub: https://t.co/RwUjyHJEym Ele oferece suporte a uma variedade de fontes e destinos de dados, incluindo arquivos locais, Amazon S3, Google Drive e bancos de dados vetoriais como Postgres, Qdrant e LanceDB. Além disso, também inclui componentes de conversão comumente usados, como segmentação de texto, geração de incorporação, análise de PDF e construção de grafos de conhecimento. Oferece uma vasta gama de exemplos que abrangem mais de 20 cenários de aplicação prática, incluindo pesquisa semântica, grafos de conhecimento, recomendação de produtos e pesquisa de imagens, que podem ser consultados e utilizados diretamente.