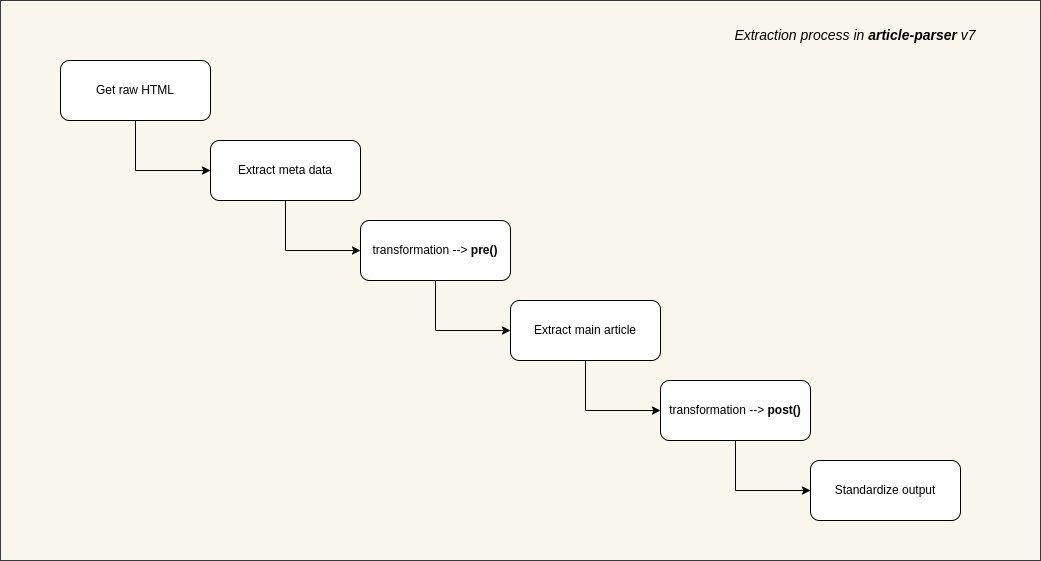
Quando você quer extrair conteúdo de uma página da web para alimentar inteligência artificial ou criar um aplicativo de leitura posterior, o maior obstáculo geralmente não são as requisições de rede, mas sim como extrair com precisão o texto principal de uma tela cheia de anúncios, barras laterais e navegação. Descobri recentemente a biblioteca de código aberto article-extractor, que foi projetada especificamente para resolver esse problema. Ela consegue identificar e extrair de forma inteligente os dados principais de artigos a partir de URLs complexas. Ele pode remover automaticamente elementos desnecessários da página e retornar títulos estruturados, texto principal, imagens de capa, autores e até mesmo tempo de leitura. GitHub: https://t.co/bF0hvCYr8I Ele oferece suporte à lógica de transformação personalizada, permitindo que você escreva regras de pré-processamento ou pós-processamento para domínios específicos, o que melhora muito a precisão da extração. É compatível com Node.js, Bundle e ambientes de navegador, e suporta a configuração de proxies e cabeçalhos personalizados para lidar facilmente com estratégias anti-raspagem. Se você desenvolve agregadores de conteúdo, leitores de RSS ou precisa limpar dados de páginas da web para treinar modelos de grande porte, esta biblioteca vale a pena ser adicionada ao seu conjunto de ferramentas.