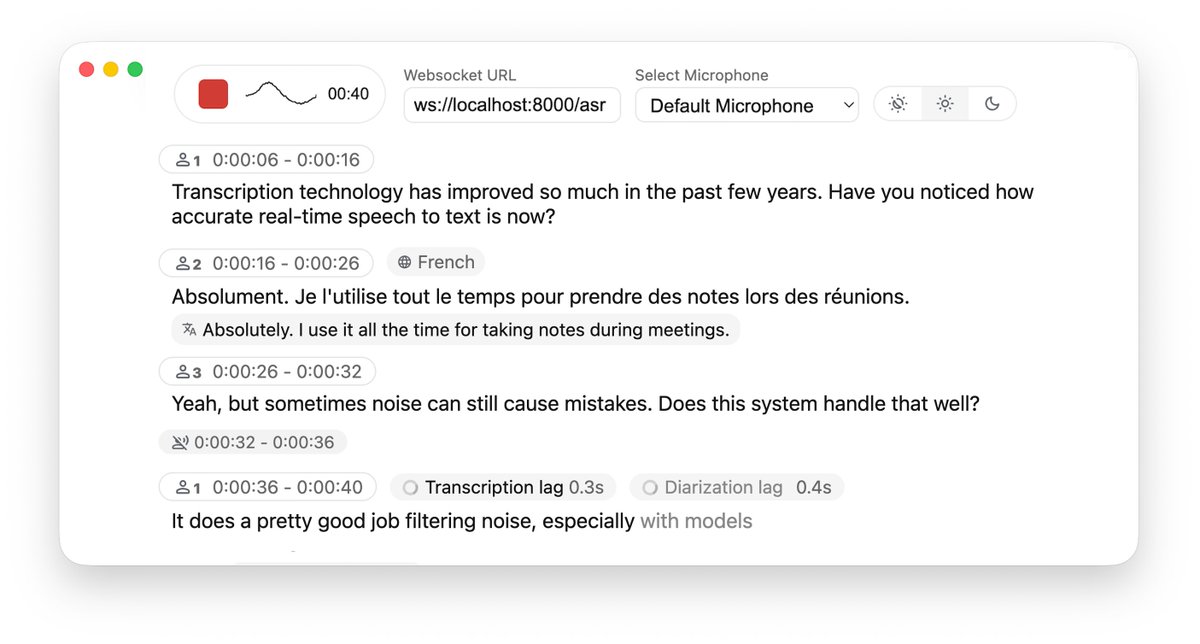
Para obter a conversão de fala em texto em tempo real em um projeto, geralmente é necessário escolher uma API na nuvem, o que não só é caro, como também levanta preocupações sobre a privacidade dos dados. Embora a implantação local do Whisper seja gratuita, a latência e a experiência de segmentação de frases ao processar áudio em streaming costumam ser insatisfatórias. Me deparei com o projeto de código aberto WhisperLiveKit no GitHub, que oferece uma solução completa de reconhecimento e tradução de fala local em tempo real, otimizada especificamente para problemas de latência de streaming. Além de oferecer suporte à transcrição em tempo real de alta precisão, também possui reconhecimento de locutor (diarização) e detecção de atividade de fala (VAD) integrados, que podem distinguir com precisão quem está falando e quando há pausas. GitHub: https://t.co/SVCcyqdqhG O backend é extremamente flexível, suportando integração com o Faster Whisper ou o mecanismo mlx-whisper otimizado para Apple Silicon, e até mesmo integrando o modelo NLLW para alcançar a tradução em tempo real de 200 idiomas. O projeto inclui exemplos prontos para uso em Python, tanto para o lado do servidor quanto para o lado da web, com suporte para implantação em Docker. Ele fornece uma infraestrutura muito sólida para a construção de um sistema de gravação de reuniões ou interpretação simultânea que preserve a privacidade e tenha baixa latência.