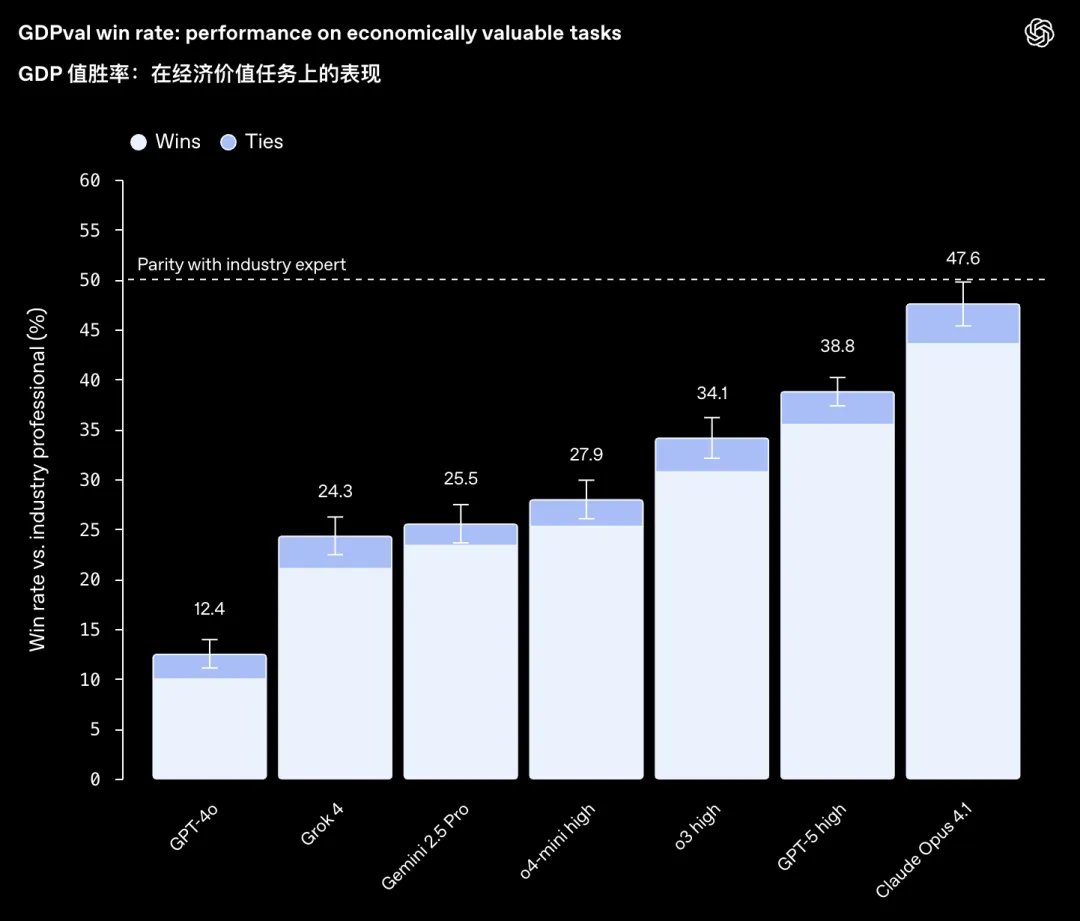
サムは、OpenAI の年末レポートカードである GPT 5.2 が正式にリリースされたことに大喜びしています。 バージョン番号に騙されないでください。これは OpenAI の年末の大きなサプライズです。 公式の位置付けは、専門的な知識作業のためのこれまでで最も強力なモデルです。 このモデルの性能は大幅に向上しましたが、価格も40%も大幅に上昇しました。 コスト削減の一般的な傾向の中で、モデルの価格を上げるには通常、強固な基盤が必要です。 このモデルに自信を与えるものは何でしょうか? 少し前に、OpenAI は、国内総生産 (GDP) という主要な経済指標にヒントを得た GDPval を設計しました。 1,320 の専門タスクは、米国の GDP に貢献する上位 9 つの業界から厳選された 44 の職業をカバーしています。 このタスクでは、営業プレゼンテーション、会計スプレッドシート、緊急治療室のスケジュール、製造フローチャート、短いビデオなどの本物の成果物を提出する必要があります。 GDPval が初めて発表されたとき、Claude Opus 4.1 は 47.6 というスコアで大きくリードしていました。 しかし今日、GPT-5.2 によってスコアが直接 70% 以上に向上しました。
コーディング能力 SWE-Bench Pro は、現実世界のソフトウェア エンジニアリングを厳密に評価します。 Python のみをテストする SWE-bench Verified とは異なり、SWE-Bench Pro は 4 つの言語をテストし、汚染に対する耐性が強く、より挑戦的で、より多様で、より産業的に関連性の高いものになるよう設計されています。 GPT-5.2 Thinking は、SWE-Bench Pro で 55.6% という新たな最先端のパフォーマンスを達成し、Claude Opus 4.5 の 52% と Gemini 3 Pro の 43.3% を上回りました。

GPT-5.2 は、長いコンテキストの推論の分野で新たな業界ベンチマークを確立しました。 MRCR v2 (マルチターン共参照解決) メトリックは、多数の類似したリクエストと応答で構成される長い「干し草の山」ドキュメントに複数の同一の「針」ユーザー リクエストが挿入され、その後、モデルが n 番目の「針」に対応する応答を再現する必要があるかどうかを測定します。 GPT-5.2 は、4 ピン MRCR バリアント (最大 256,000 トークン) でほぼ 100% の精度を達成した最初のモデルです。

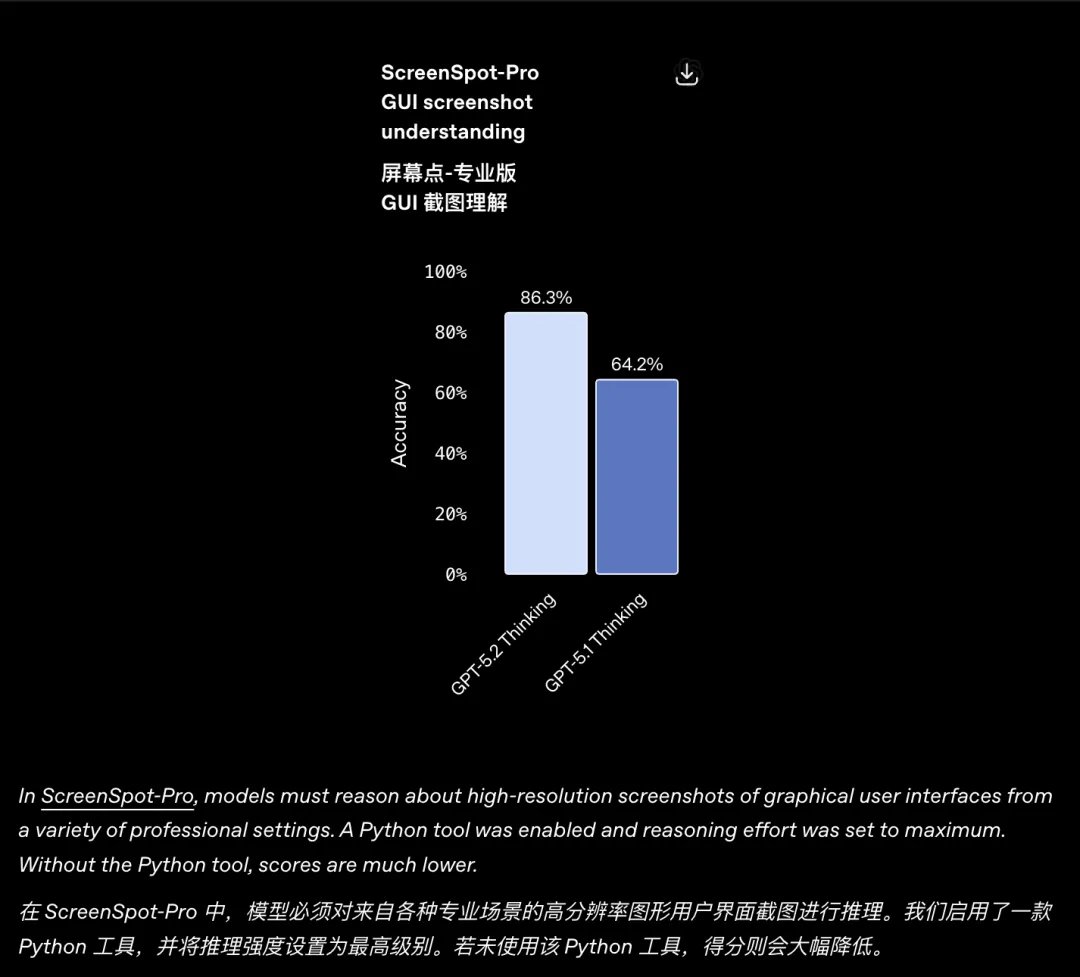
幻覚の減少 GPT-5.2のもう一つの大きな改良点は、「錯覚」の大幅な削減です。エラー率は前バージョンより30%低くなっています。 視覚的な理解 GPT-5.2 思考により、図式的推論やソフトウェア インターフェースの理解を伴うタスクでのエラー率がほぼ半分に減少しました。

標準バージョン: 入力 1.75 ドル、出力 14 ドル。 プロフェッショナル版: 入力 $21、出力 $168。 全体的に、価格は GPT 5.1 と比較して 40% 増加しました。 信じられない。 高すぎる。 今年の AI トレンドには、テキスト モデル (GPT 5.2) と画像モデル (Banana Pro) の価格上昇が含まれます。 来年の AI のトレンドはビデオモデルの価格上昇になるでしょうか?
