ChatGPTのメモリシステムは優れていますが、一般的に多くのリソースを消費します。OpenAIはどのようにして8億人のユーザーにサービスを提供できるメモリシステムを実現したのでしょうか? 誰かが ChatGPT のメモリ システムをリバース エンジニアリングしたところ、予想よりもはるかに単純であることがわかりました。 ベクター データベースはなく、チャット ログ RAG も処理されません。 代わりに、次の 4 つの異なるレベルを使用します。 環境に合わせて調整されたセッションメタデータ 長期間保存された明確な事実、 最近のチャットの簡単な要約。 そして、現在の会話のスライディング ウィンドウ。 このブログ投稿では、各レイヤーがどのように機能するか、そしてこのアプローチが従来の検索システムよりも優れている理由を詳しく説明します。

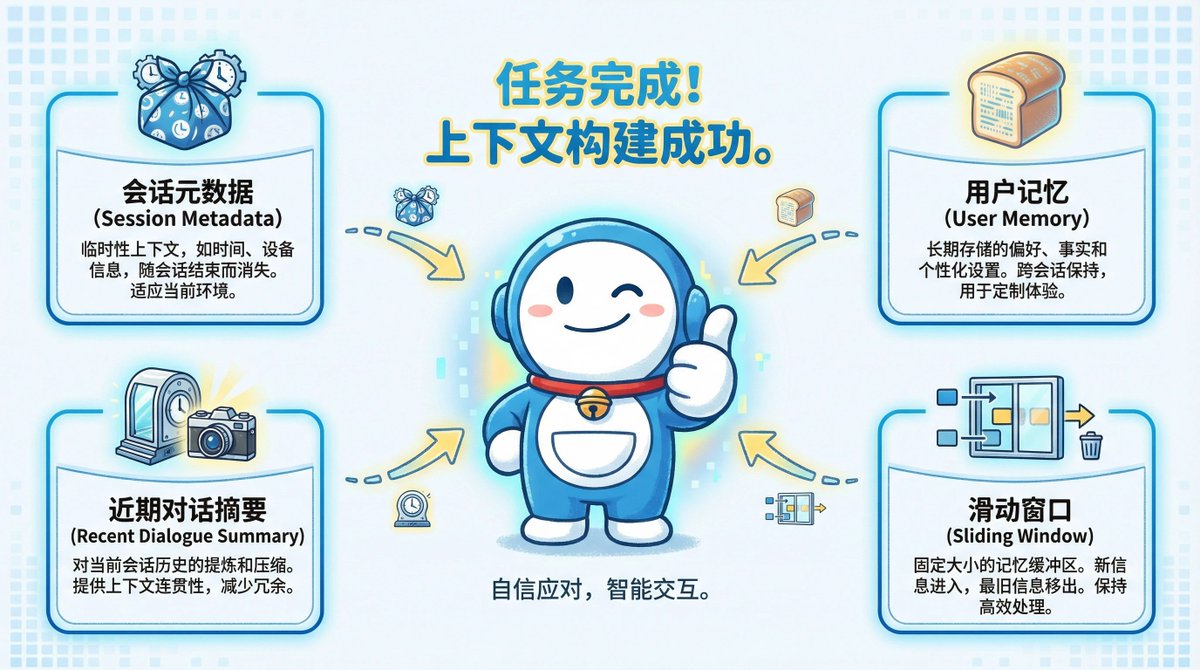
その中核は 4 層のコンテキスト スタックです。 会話をするたびに、AI はこの「ポータル」を構築し、あなたに関するすべての重要な情報を一度にモデルに挿入します。 連携して動作する 4 つのレイヤーで構成されています。

最初のレイヤーには、デバイスや場所などの一時的な環境情報が含まれており、セッションが終了すると消えます。 2 番目のレイヤーは永続的な個人プロファイルであり、記憶するように要求した重要な事実を保存します。

3 番目のレイヤーは、最近の興味に関する「ゆるいマップ」であり、チャットの全文ではなく、チャットのタイトルの概要のみが含まれます。 最下層には、スライディング ウィンドウのように現在の会話の完全な記録が含まれており、即時の継続性が確保されます。 ウィンドウがいっぱいになるとどうなりますか?

スライディング ウィンドウとは、長さ制限に達したために現在のチャット ウィンドウが「スライド」し、最も古いメッセージが削除された場合でも、永続的なメモリと最近の関心の概要は保持されることを意味します。 これにより、長い会話でも AI があなたを「忘れる」ことがなくなります。
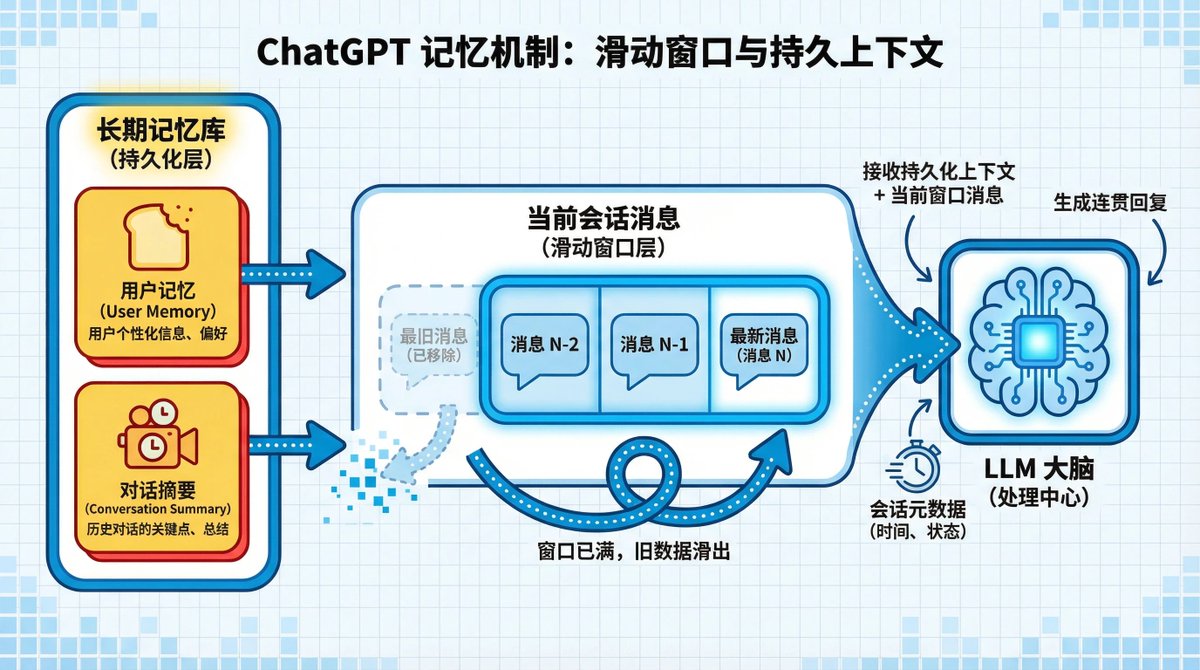
この4層アーキテクチャは、エンジニアリングの創意工夫の結晶です。パーソナライゼーション、パフォーマンス、そして計算コストの完璧なバランスを実現し、複雑なシステムを必要とせずに最高のユーザーエクスペリエンスを提供します。

このようにして、素早く応答し、ユーザーのことをより深く理解してくれるスマートアシスタントを手に入れることができます。x.com/manthanguptaa/…ポイント オリジナルリンク: