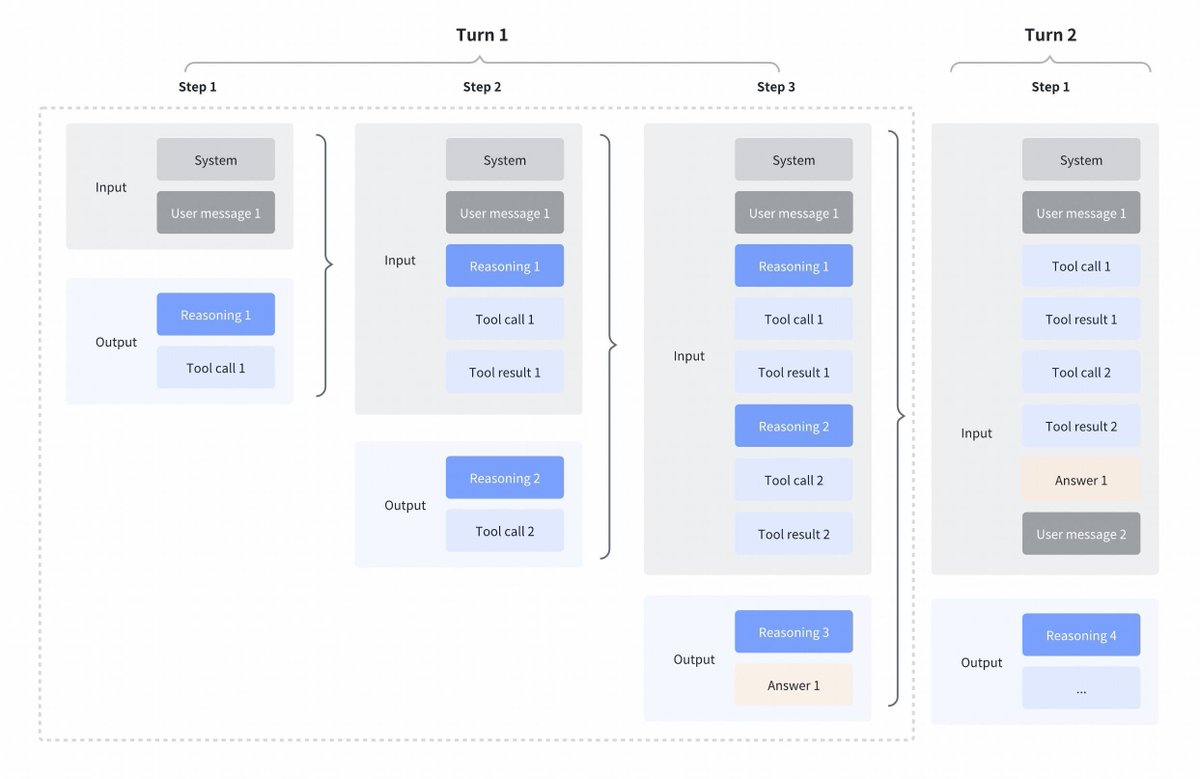
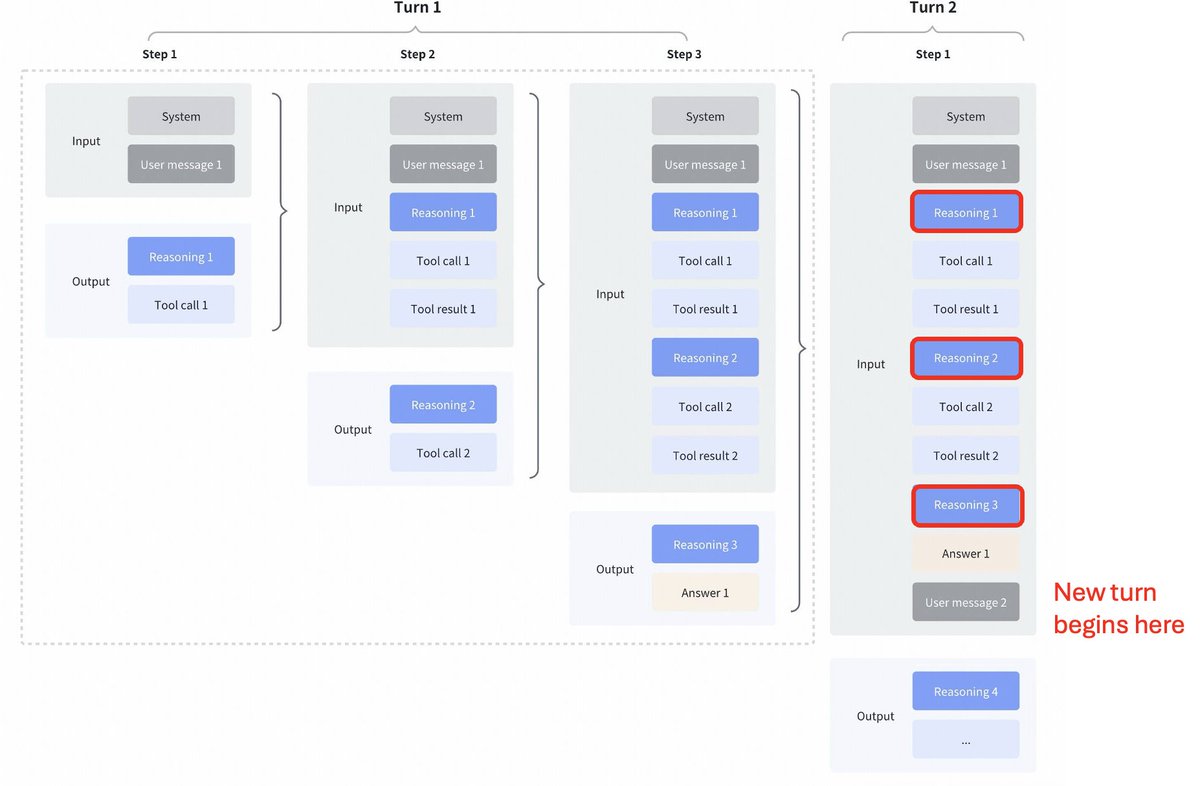
Changement de stratégie intéressant de la part de GLM4.7 comparé aux Kimi K2 Thinking, DeepSeek V3.2 et MiniMax M2.1 Réflexion entre les appels d'outils : Tous ces modèles prenaient en charge la pensée entrelacée pour les appels d'outils, mais ils effaçaient la pensée des tours précédents, comme on peut le voir dans la première capture d'écran ci-dessous. Pensée préservée dans GLM 4.7 : Comparativement à cela, GLM 4.7 (pour le codage des points d'extrémité uniquement) conserve le raisonnement des tours précédents, comme on peut le voir dans la capture d'écran ci-dessous (remarquez les blocs rouges). Pour l'autre point de terminaison de l'API, le comportement est le même qu'auparavant (on ignore le raisonnement des étapes précédentes). Cela devrait certainement améliorer les performances, car le modèle disposera d'un contexte antérieur. Comme le souligne @peakji, les modèles ont besoin de leur raisonnement antérieur pour prendre de bonnes décisions par la suite. Cela va à l'encontre de la compression du contexte, mais je suppose que dans certains cas de programmation, cela peut s'avérer très utile. J'aurais aimé qu'ils le rendent configurable, pour que nous puissions constater nous-mêmes son impact.