Zhipu AI publie : GLM-4.7 introduit un mode de pensée à trois niveaux Avant de générer la réponse, GLM-4.7 effectue automatiquement une inférence interne : Analyser les objectifs de la tâche, formuler des raisonnements, prédire les obstacles potentiels et enfin générer un résultat visible. Il peut également « se souvenir de son processus de réflexion précédent » au cours de plusieurs cycles de dialogue. Les utilisateurs peuvent également « contrôler l'intensité de leur réflexion ». Dans le même temps, il améliore considérablement le codage et l'esthétique de l'interface, avec des performances proches de celles de GPT-5 et Claude 4.5. Auparavant, les pages web générées par GLM-4.7 ressemblaient à du « travail de développeur », mais maintenant elles ressemblent à du « travail de designer ». Il permet de générer des pages web épurées et modernes, ainsi que de créer des diaporamas et des affiches à la mise en page soignée. Il gère automatiquement la mise en page, les couleurs et les proportions du texte pour une cohérence visuelle optimale. Ci-dessous se trouve un fichier PPT généré par GLM-4.7.

GLM-4.7 a apporté des optimisations significatives à la **cohérence visuelle** du contenu généré : Génère automatiquement des diapositives de code HTML, CSS et JavaScript structurées avec une mise en page et des proportions améliorées, ce qui donne des pages Web au style et à l'ergonomie modernes.
Site web conçu avec GLM-4.7 ↓

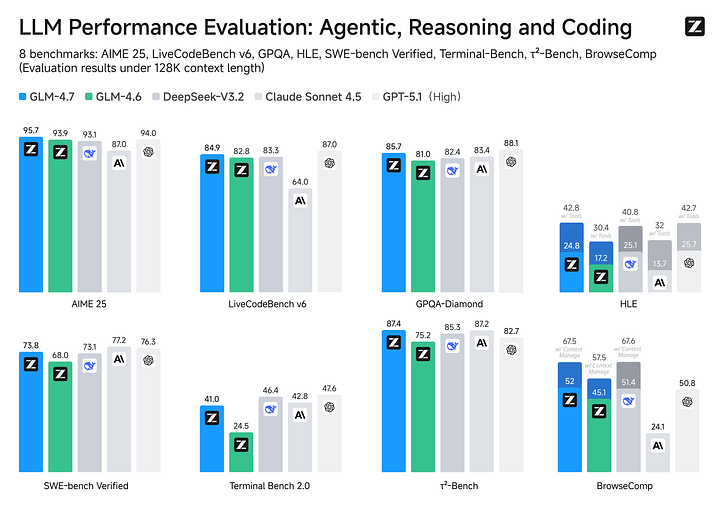
Grâce au modèle de raisonnement « réfléchir avant d'agir » GLM-4.7 a considérablement amélioré les capacités de codage, avec un taux d'achèvement des tâches nettement supérieur à celui de son prédécesseur (+10%~15%). Les performances des tâches de programmation atteignent 90 % du niveau Claude 4.5 ; la génération visuelle et de pages web est supérieure à Claude 4.5. Il présente des avantages en matière de « génération de code + mécanisme de réflexion + sortie visuelle ».
Les performances globales de GLM-4.7 se situent entre celles de GPT-5 et de Claude 4.5. La logique mathématique est proche de GPT-5 et supérieure à Claude 4.5. En termes de capacité de raisonnement, le GLM-4.7 est légèrement moins performant en moyenne que la série GPT-5, mais surpasse le Claude Sonnet 4.5 et le Kimi K2. GLM-4.7 peut utiliser activement des outils, tels que la recherche en ligne ou l'appel d'API externes. Il atteint 87,4 % dans τ²-Bench, surpassant GPT-5 (82,7 %).
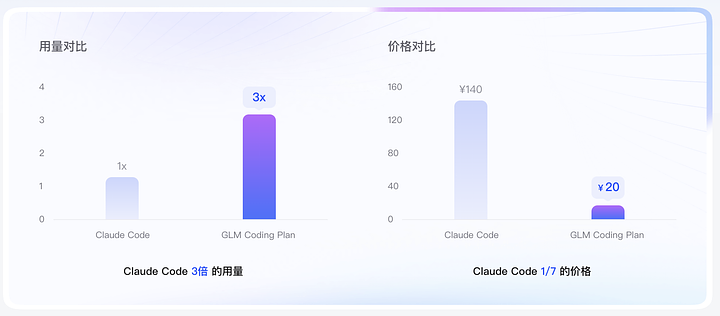
Découz.ais://t.co/AfaqxyMkip Concernant le prix : Les utilisateurs du plan de codage GLM seront automatiquement mis à niveau vers GLM-4.7. Comparé au modèle du code de Claude : Le coût représente 1/7 de son coût ; En utilisant un quota trois fois supérieur à celui de ses tâches de programmation, les performances ont atteint 90 % du niveau de Claude. C'est une option très avantageuse.
Présexiaohu.ai/c/a066c4/ai-gl…ps://t.co/Xphuggingface.co/zai-org/GLM-4.7nt du mogithub.com/zai-org/GLM-4.5BTD7CEr docs.bigmodel.cn/cn/guide/model…XUnPMcjYYc Documentation de l'API : https://t.co/Dn6U7WxNrW