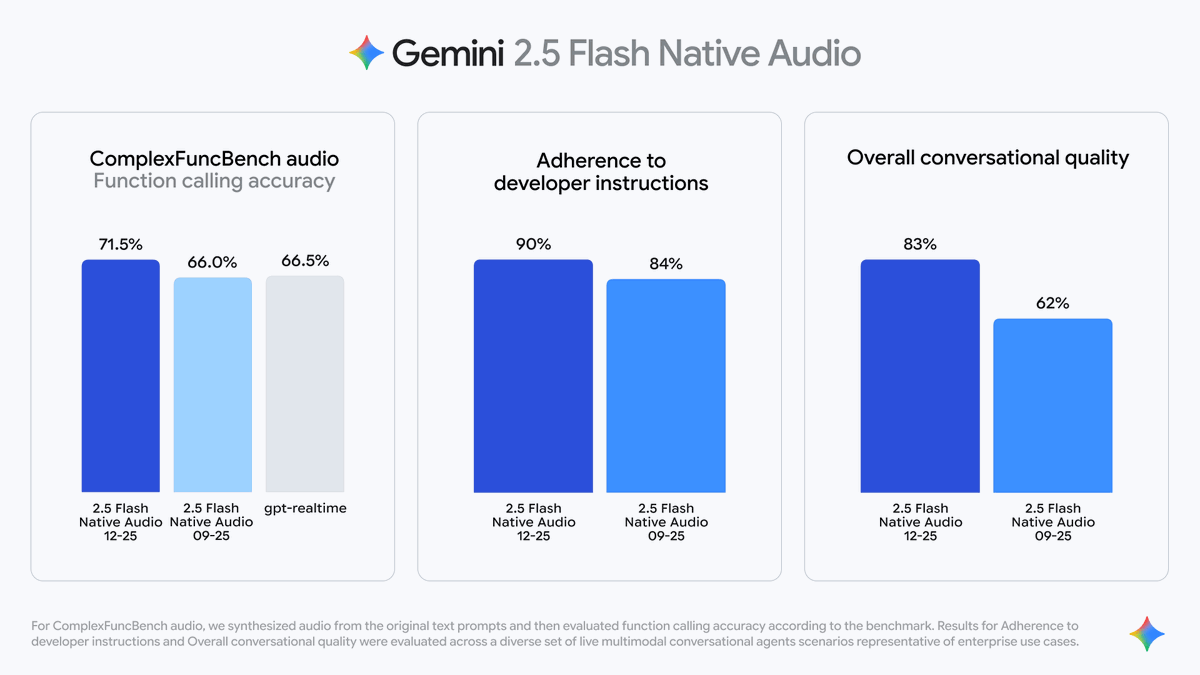
Google lance un nouveau modèle audio natif Flash Gemini 2.5 Utilisé pour piloter diverses applications vocales en temps réel L'expression « audio natif » fait référence à la capacité du modèle à générer directement une sortie vocale naturelle, plutôt que de générer d'abord du texte puis de synthétiser la parole. Non seulement il « comprend ce que vous dites », mais il « peut aussi répondre immédiatement avec une voix humaine », avec un ton, un rythme et des pauses plus naturels. Les trois capacités fondamentales ont été considérablement améliorées : 1️⃣ Des « appels de fonction » plus intelligents Gemini peut désormais accéder de manière proactive à des sources d'information externes pendant les conversations vocales, telles que : Appelez l'API météo ; Interroger la base de données ; Recevez des informations en temps réel sur l'actualité ou les marchés boursiers. Il ne se contente pas de « répondre », mais peut déterminer quand rechercher des informations et quand poursuivre la conversation pendant le dialogue, et peut « rechercher des informations tout en parlant » pour maintenir un flux audio fluide.
2️⃣ Amélioration de la compréhension des instructions Gemini 2.5 Flash Native Audio offre une meilleure compréhension des instructions vocales complexes. Les données de test de Google le confirment : Le taux de respect des consignes est passé de 84 % à 90 % ; L'exhaustivité et la précision du contenu produit ont été considérablement améliorées. 3️⃣ Amélioration de la fluidité conversationnelle Gemini 2.5 Flash Native Audio peut mémoriser le contexte de plusieurs conversations, rendant les transitions vocales plus naturelles.
Le modèle audio natif Flash Gemini 2.5 est désormais entièrement disponible sur Vertexiaohu.ai/c/xiaohu-ai/go…être utilisé dans l'API Gemini (aperçu). Détails : https://t.co/CnBlan3RBh