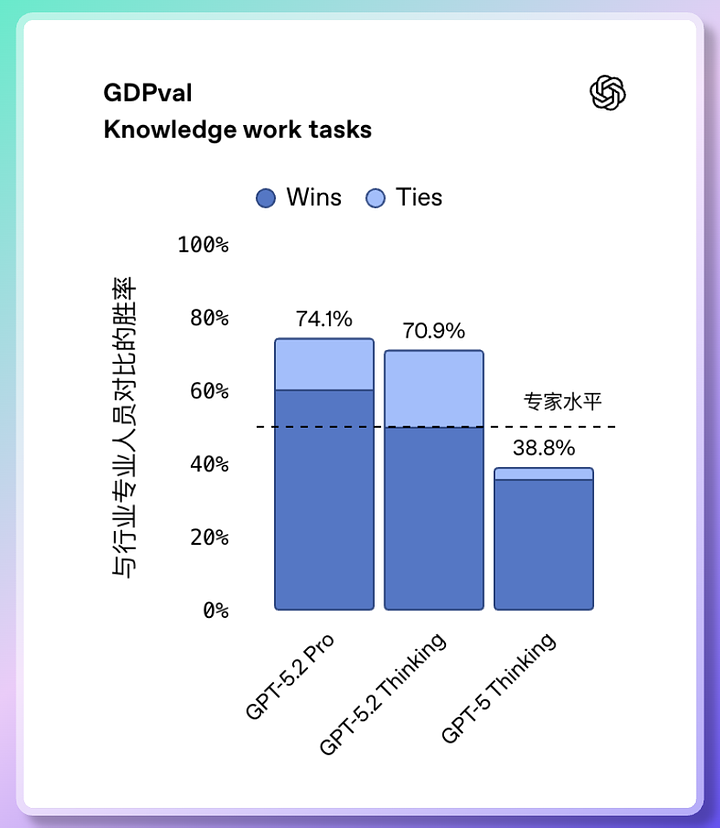
Analyse complète du modèle GPT-5.2 : Optimisé pour les professionnels en activité compétences bureautiques améliorées Le mode adulte sera lancé l'année prochaine Dans sa présentation officielle, OpenAI désigne GPT-5.2 comme suit : "Conçu pour le travail intellectuel." Dans le test GDPval (qui couvre 44 tâches professionnelles), GPT-5.2 Thinking a obtenu un score aussi élevé que 70,9 %, ce qui signifie qu'il peut rivaliser avec les experts du secteur dans la plupart des emplois basés sur la connaissance. Que peut-il faire ? ✅ Créer un modèle financier complet ✅ Concevoir une présentation PowerPoint d'entreprise bien structurée ✅ Rédaction de rapports d'analyse et de recommandations d'investissement ✅ Analyser des documents de données complexes s'étendant sur des dizaines de pages En termes de rapidité : il accomplit les tâches 11 fois plus vite que les experts humains, mais pour seulement 1 % du coût. 💡 Les données officielles montrent que les utilisateurs professionnels de ChatGPT économisent en moyenne 40 à 60 minutes par jour. Les utilisateurs intensifs peuvent économiser plus de 10 heures par semaine.
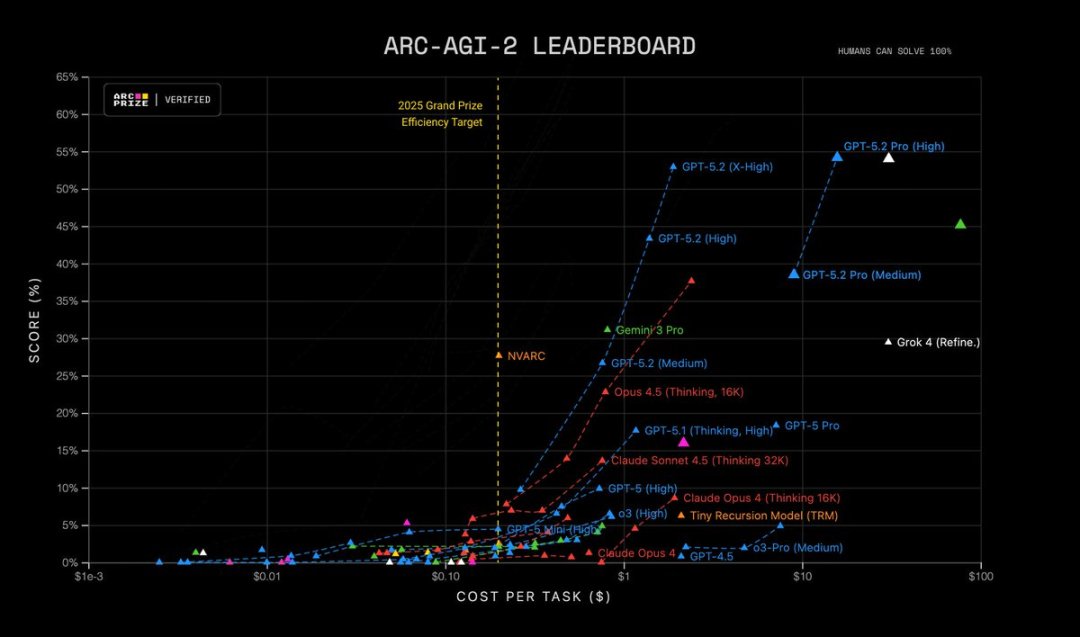
1️⃣ Raisonnement : Solides compétences en logique multi-étapes et en mathématiques GPT-5.2 Thinking a obtenu des résultats records dans de multiples évaluations exigeantes de raisonnement scientifique et mathématique : Quiz scientifique GPQA Diamond : 92,4 % (Version Pro : 93,2 %) Raisonnement abstrait ARC-AGI-1 : 86,2 % (Le premier modèle à franchir le seuil des 90 %) Raisonnement d'ordre supérieur ARC-AGI-2 : 52,9 %, établissant un nouveau record pour le modèle Mind Chain. Évaluation des mathématiques avancées de FrontierMath : 40,3 %, dépassant largement la génération précédente ; Problèmes du concours de mathématiques HMMT : 99,4 % Évaluation de mathématiques AIME : Solution complète à 100 %

GPT-5.2 Pro (High) est le modèle le plus performant sur ARC-AGI-2, atteignant un score de 54,2 % pour un coût de 15,72 $ par tâche ! Il surpasse tous les autres modèles.
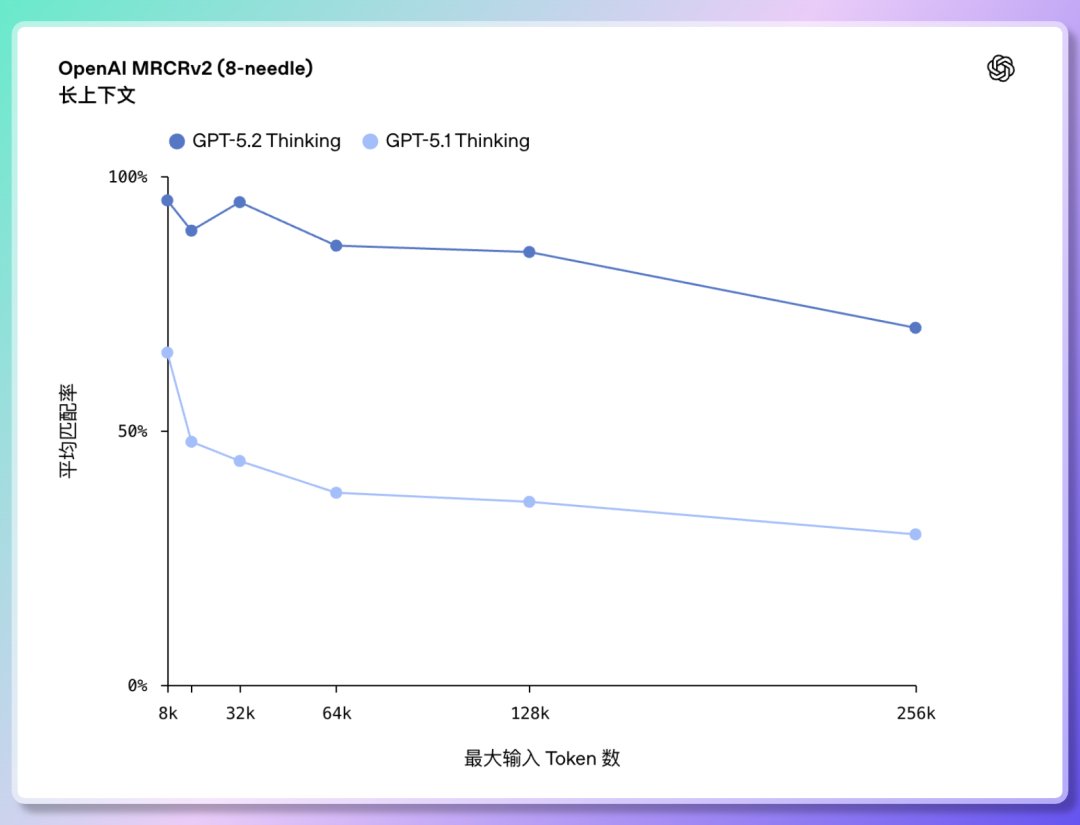
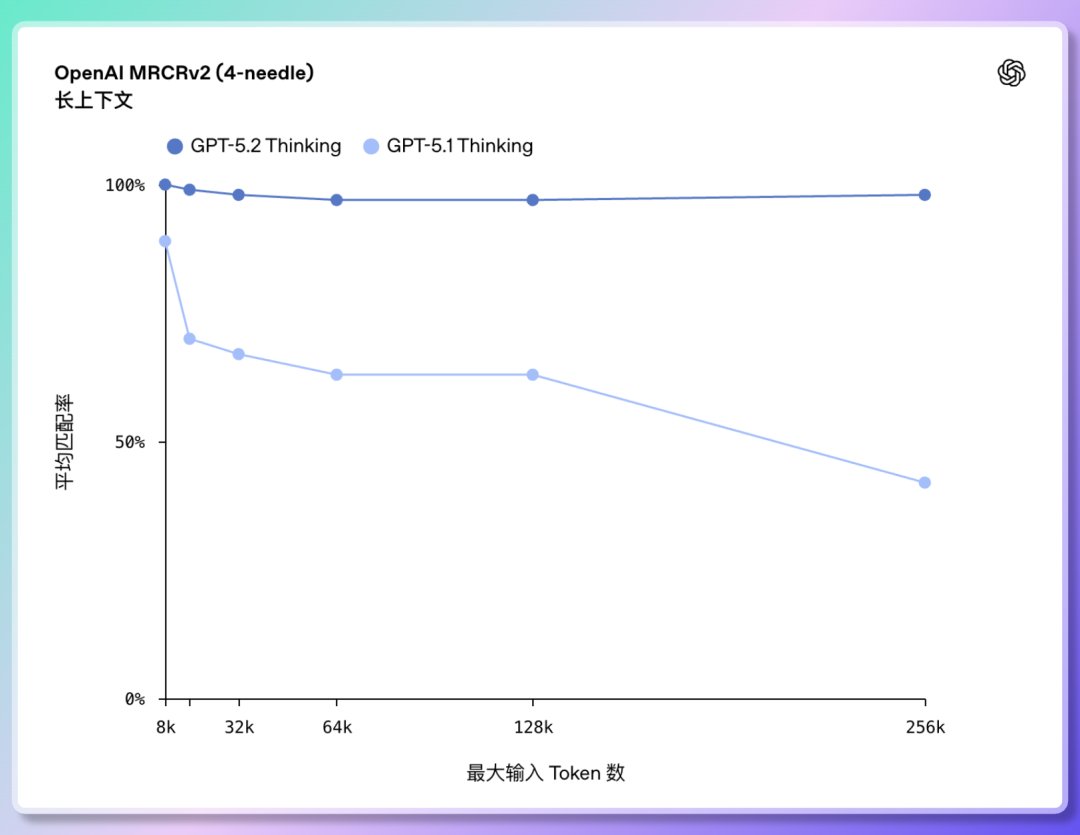
2️⃣ Compréhension de textes longs et raisonnement inter-documents : une précision proche de 100 % pour la première fois. GPT-5.2 peut gérer des longueurs de contexte allant jusqu'à 256 000 jetons (environ plus de 200 pages de documents). De plus, dans le test de compréhension de texte long « OpenAI MRCRv2 », GPT-5.2 Thinking a atteint un taux de précision de près de 100 %. Il peut gérer des projets de grande envergure répartis sur plusieurs fichiers ;
3️⃣ Compréhension visuelle : Capable de visualiser des images, de reconnaître des interfaces et d’interpréter des graphiques. Les capacités visuelles de GPT-5.2 ont été considérablement améliorées : son taux d’erreur dans le raisonnement sur les images a diminué de près de 50 %, et il est capable de comprendre : structures de graphiques (telles que les graphiques linéaires financiers, les graphiques de données expérimentales) ; Disposition de l'interface logicielle ; Relations spatiales dans les schémas de circuits imprimés et les dessins de conception de produits.

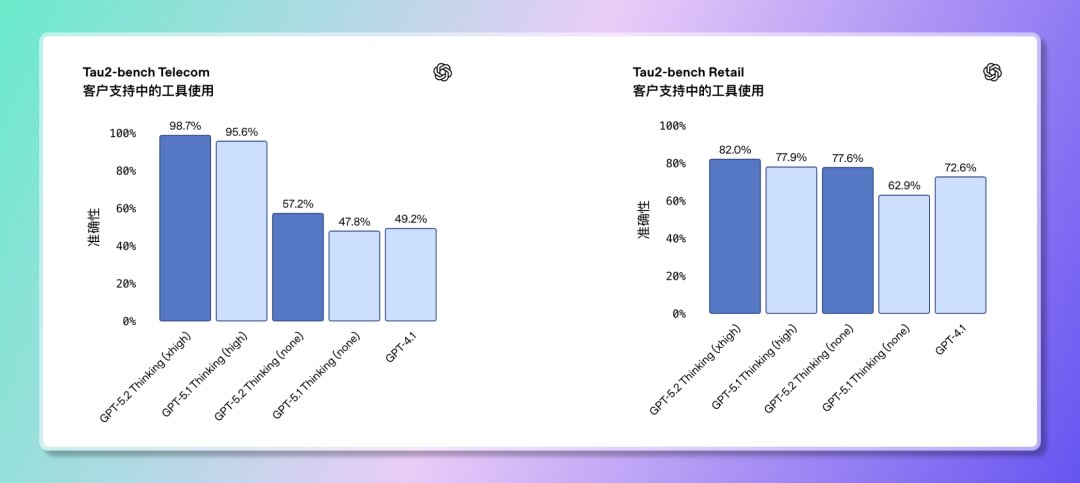
4️⃣ Utilisation des outils et exécution des tâches : Capable de planifier et de réaliser des tâches en plusieurs étapes de manière indépendante. GPT-5.2 a obtenu un score de 98,7 % au test de référence Tau2-Bench Telecom, démontrant ainsi ses capacités matures d'appel d'outils dans des tâches complexes à plusieurs tours. Il peut réaliser le travail de bout en bout.
5️⃣ Les compétences en programmation continuent d'évoluer : les tests d'ingénierie logicielle battent des records dans tous les domaines Dans le test SWE-Bench Pro (tâche d'ingénierie logicielle industrielle réelle), le score de GPT-5.2 Thinking s'est amélioré à 55,6 %, tandis qu'il a également atteint un nouveau record de 80 % dans le test SWE-Bench Verified. Les premiers développeurs ont souligné que GPT-5.2 est plus performant dans des scénarios tels que le développement front-end et la conception d'interfaces 3D, et peut générer du code et des interfaces complets et exécutables.
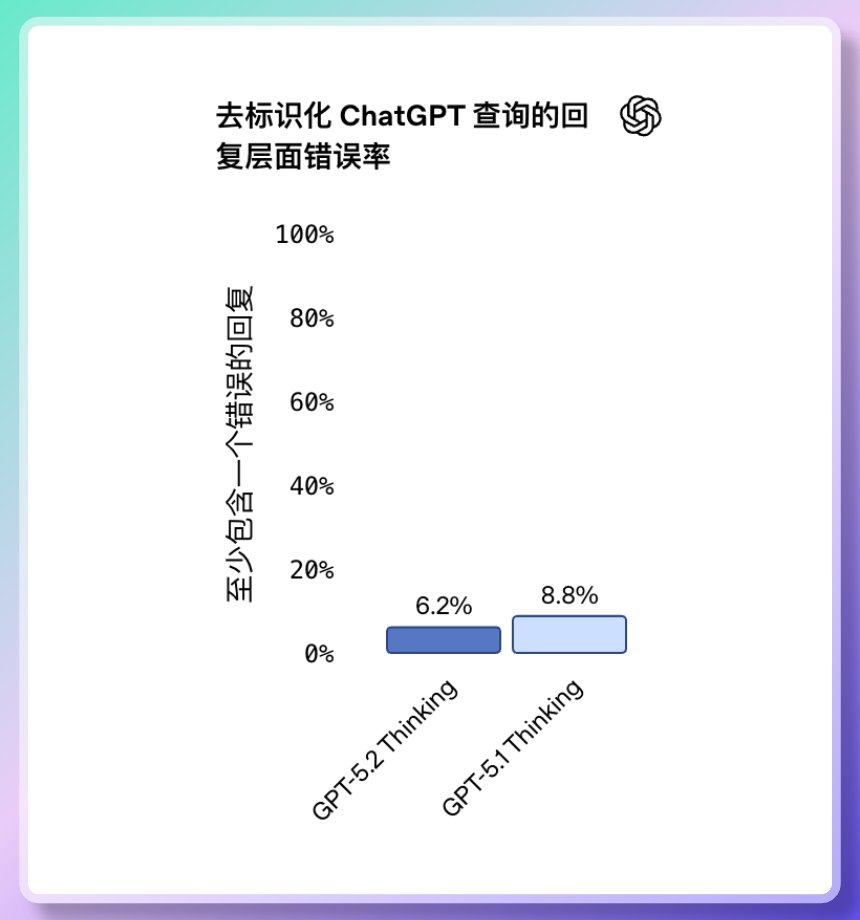
Moins d'erreurs, une plus grande stabilité et une meilleure compréhension du comportement humain. GPT-5.2 a réduit le « taux d'illusion » (taux de fausses réponses) de 38 %. Il répond aux questions de recherche, de rédaction et d'analyse de manière plus fiable et réduit les cas de « fabrication de faits ». Par ailleurs, la sécurité de la réponse du modèle a été considérablement améliorée dans les tâches liées à la santé mentale. Ils sont plus robustes dans les situations délicates telles que la santé mentale, l'automutilation, le suicide et la dépendance affective.
Le « mode adulte » de ChatGPT arrive bientôt. OpenAI prévoit de lancer le « mode adulte » de ChatGPT au premier trimestre 20mp.weixin.qq.com/s/I8pxgiRUPWbl…va introduire un mécanisme de reconnaissance de l'âge afin de protéger automatiquement les mineurs contre l'accès à des contenus sensibles. Détails : https://t.co/WsoEbc1Ke5
