Microsoft publie VibeVoice-Realtime-0.5B Modèle de synthèse vocale en temps réel La transcription quasi instantanée peut commencer avant même que l'orateur ait fini de parler 😅 Il prend en charge le chinois et l'anglais, mais la prise en charge du chinois est légèrement moins performante. Les principales caractéristiques sont : 🕒 Sortie audio quasi instantanée (300 millisecondes) 🗣️ La voix est naturelle et fluide, capable de lire de longs textes et de générer des enregistrements audio fluides jusqu'à 90 minutes de long. 💻 Permet un dialogue naturel entre jusqu'à 4 personnages, en maintenant un ton et un rythme constants (comme dans les interviews de podcast). 🎭 Il peut capter les changements émotionnels et reconnaître et exprimer automatiquement des émotions telles que la colère, les excuses et l'excitation. 🧩 Mémoire contextuelle : Maintenez une cohérence dans le ton, le rythme et la logique, en parlant couramment comme une vraie personne. 🔧 Petite taille et vitesse rapide, idéal pour l'intégration dans des applications (par exemple, pour permettre aux assistants IA de « parler » directement).
version anglaise
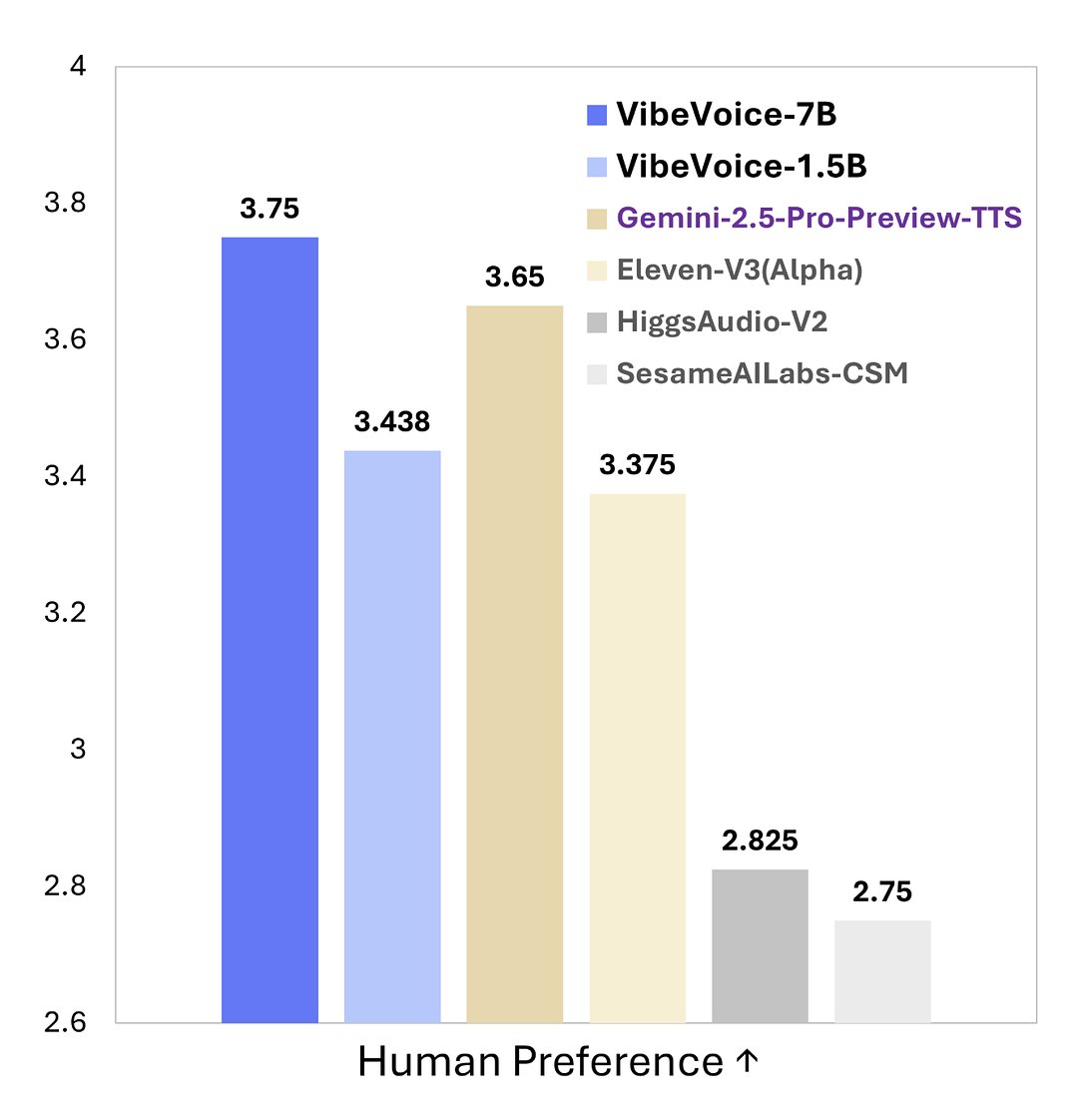
La note est assez élevée.
Présentation mixte xiaohu.ai/c/a066c4/vibev…s Pomicrosoft.github.io/VibeVoice/et d'études de cas, veuillez consulter : https://t.co/2U7qrPqWOk Adresse du projet : https://t.co/3DQV0xwNJO