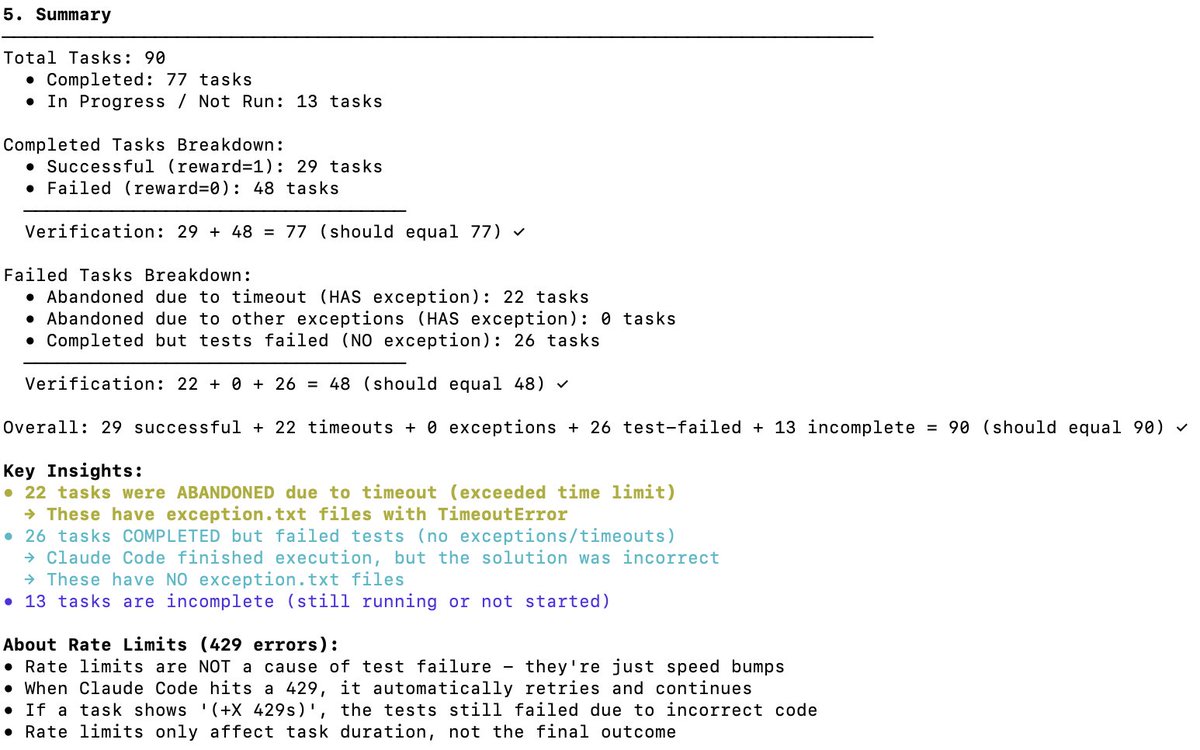
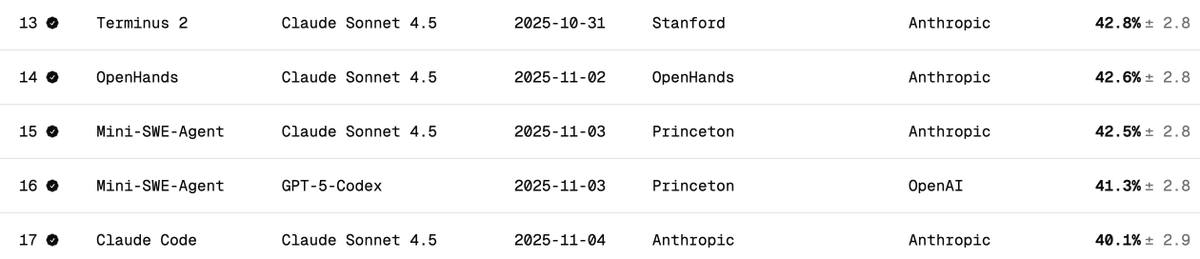
Vérification indépendante des performances de DeepSeek V3.2 sur Terminal Bench 2 Terminal Bench évalue la capacité d'un modèle à prendre en charge/exécuter un agent dans un environnement terminal (par exemple, Claude Code, Codex CLI, Gemini CLI). À mon avis, il s'agit du benchmark LLM le plus important pour le développement de logiciels d'IA. Il implique l'utilisation de l'IA pour interagir avec votre interface de ligne de commande (CLI) afin de télécharger des logiciels, développer du code, effectuer des tests, etc. Quel est le score officiel ? Le score officiel de DeepSeek v3.2 est de 46,4 (Pensée) et 37,1 (Non-Pensée), comme indiqué dans le tableau ci-dessous. Ils ont utilisé le framework Claude Code, comme décrit dans l'article. Quelles sont les performances de Claude Code + Sonnet 4.5 sur ce test de performance ? Vous trouverez ci-dessous les résultats des tests de performance du terminal Claude Sonnet 4.5 sur différents câblages. Notez que le résultat est d'environ 40 % pour le câblage Claude Code. Quels scores ai-je obtenus pour DeepSeek V3.2 avec Claude Code Harness ? J'ai effectué des tests avec DeepSeek-Reasoner (Thinking). Sur près de 90 tests, 77 ont pu être exécutés avant que Harbor (l'orchestrateur) ne cesse de fonctionner. 77 est un nombre pertinent pour se faire une idée, en supposant qu'il s'agisse d'échantillons non biaisés. - 29 - Réussi - 48 - Échec (22 délais d'attente dépassés + 26 codes d'erreur générés) Cela porte le score à 38% (plutôt impressionnant, et déjà proche de Claude Code + Sonnet 4.5 à 40%). Ce qui est certain, c'est que si le modèle DeepSeek v3.2 disposait de plus de temps, il pourrait certainement terminer davantage de tâches ayant expiré et dépasser largement les 38 % ; j'estime même qu'il pourrait atteindre 50 %. Mais alors, la comparaison ne serait plus pertinente (les concepteurs du test déconseillent de modifier les paramètres de délai d'expiration). Comparaison avec d'autres modèles OSS : Les modèles ci-dessous utilisent un faisceau Terminus 2 1. Kimi K2 Thinking - 35,7% 2. MiniMax M2 - 30% 3. Qwen 3 Coder 480B - 23,9% Conclusion: Les performances sont à la pointe de la technologie pour un modèle OSS, et il est incroyable qu'elles égalent presque celles de Claude 4.5 ; cependant, mon score était inférieur à celui de l'équipe DeepSeek : 46,4 (encore une fois, les 13 derniers tests n'ont pas été exécutés). Je soupçonne qu'ils aient modifié le comportement du code Claude. Ce dernier interpelle le modèle de manière spécifique (par exemple, via ) que DeepSeek v3.2 ne connaît peut-être pas ou ne gère pas aussi bien. C'était formidable de savoir que DeepSeek disposait d'un point d'accès à l'API Anthropic ; cela a grandement facilité les tests avec Claude Code. Il m'a suffi de placer le fichier settings.json dans Docker. DeepSeek (@deepseek_ai) devrait partager de manière transparente la façon dont ils ont obtenu ces scores. Coût et accès au cache : Le plus incroyable, c'est que l'exécution des 77 tests ne m'a coûté que 6 $ (Harbor a abandonné les 13 derniers pour une raison inconnue). Près de 120 millions de jetons ont été traités, mais comme la plupart étaient en entrée et ont ensuite été mis en cache (DeepSeek implémente automatiquement la mise en cache sur disque), les coûts sont restés très faibles. Demandes adressées à l'équipe Terminal Bench : Veuillez faciliter la reprise des missions interrompues avant leur achèvement. Merci pour cet excellent outil de référence. @terminalbench @teortaxesTex @Mike_A_Merrill @alexgshaw @deepseek_ai