1/n : Ce que la plupart ignorent, c'est que l'équipe DeepSeek a percé le cercle d'auto-amélioration tant redouté et recherché pour le domaine le plus complexe des LLM - la génération de preuves pour les problèmes difficiles. Il sera intéressant de voir où la boucle se rompt. Que quelqu'un réveille Eliezer Yudkowsky ! @teortaxesTex
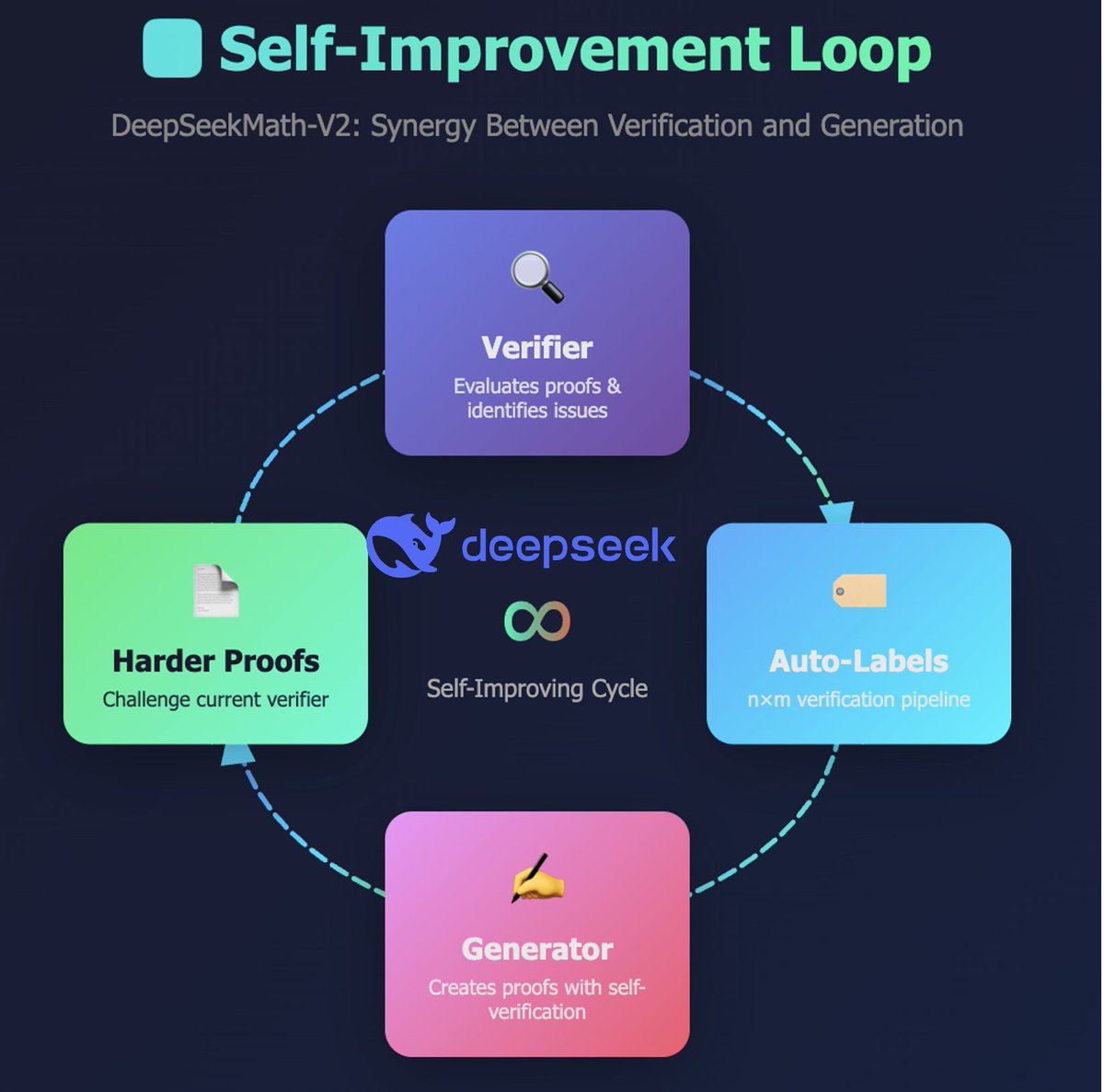
2/n : Le moment « Je suis vraiment bête » (comparable au « moment eurêka » de DeepSeek R1) La percée technologique la plus importante de l'article DeepSeekMath-V2 n'est pas la performance de niveau Or de l'IMO ! Alors, quelle est-elle ? Il s'agit de la capacité à doter le modèle des aptitudes nécessaires pour vérifier de manière fiable sa propre génération échantillonnée. Cela s'est avéré très difficile pour les modèles linéaires (même ceux basés sur le raisonnement). Citation: Lorsqu'un générateur de preuves ne parvient pas à produire une preuve parfaitement correcte du premier coup – ce qui est fréquent pour les problèmes complexes des compétitions comme les OIM et les OMC – une vérification et un perfectionnement itératifs peuvent améliorer les résultats (dans une certaine mesure). Cela consiste à analyser la preuve avec un vérificateur externe et à inciter le générateur à corriger les problèmes identifiés. Nous avons toutefois observé une limitation critique : lorsqu’on lui demande de générer et d’analyser sa propre preuve en une seule opération, le générateur a tendance à revendiquer l’exactitude même lorsque le vérificateur externe identifie facilement les défauts. Autrement dit, bien que le générateur puisse affiner les preuves en fonction des retours externes, il ne parvient pas à évaluer son propre travail avec la même rigueur que le vérificateur dédié. Cette observation nous a incités à doter le générateur de preuves de véritables capacités de vérification. @gm8xx8 @teortaxesTex @rohanpaul_ai @ai_for_success
3/n : Le modèle DeepSeekMath-V2 a littéralement été menacé de ne pas tricher. Vous pouvez le lire dans le modèle de message. Liang Wengfeng est un parent strict !
