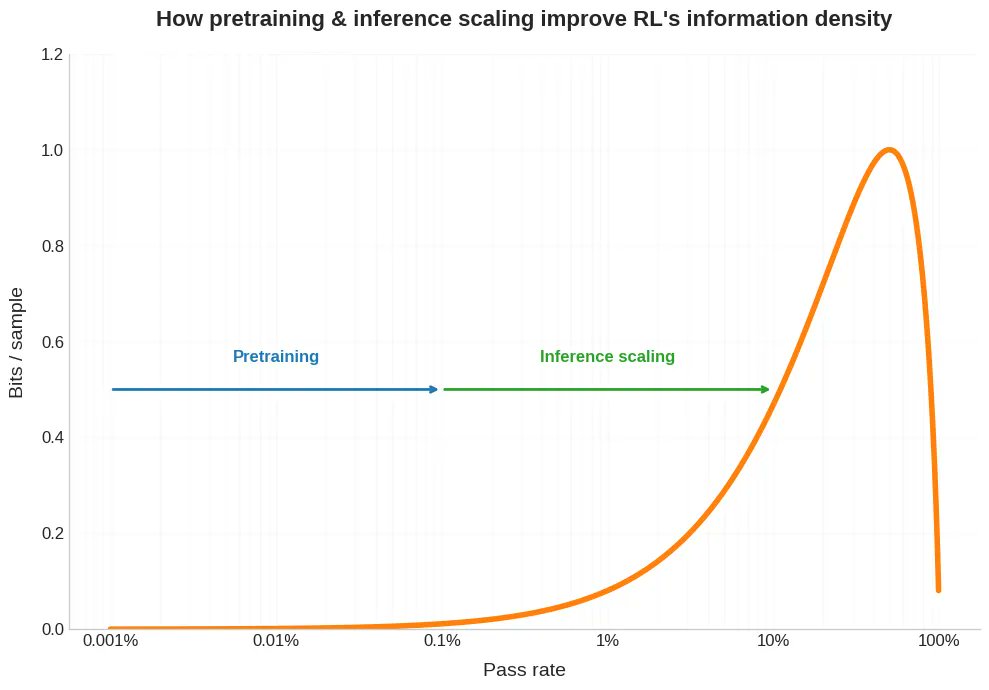
Nueva entrada en el blog. Últimamente se ha hablado mucho de que en RL se necesita mucha más capacidad de cómputo para obtener una sola muestra que en el preentrenamiento. Pero esto es solo la mitad del problema. En RL, esa muestra costosa también suele proporcionar muchos menos bits. Y esto tiene implicaciones sobre la escalabilidad de RLVR, además de ayudarnos a comprender por qué el autoaprendizaje y el aprendizaje curricular son tan útiles para el aprendizaje por refuerzo, por qué los modelos de aprendizaje por refuerzo son extrañamente irregulares y cómo podemos pensar en lo que hacen los humanos de manera diferente. Enlace a continuación.