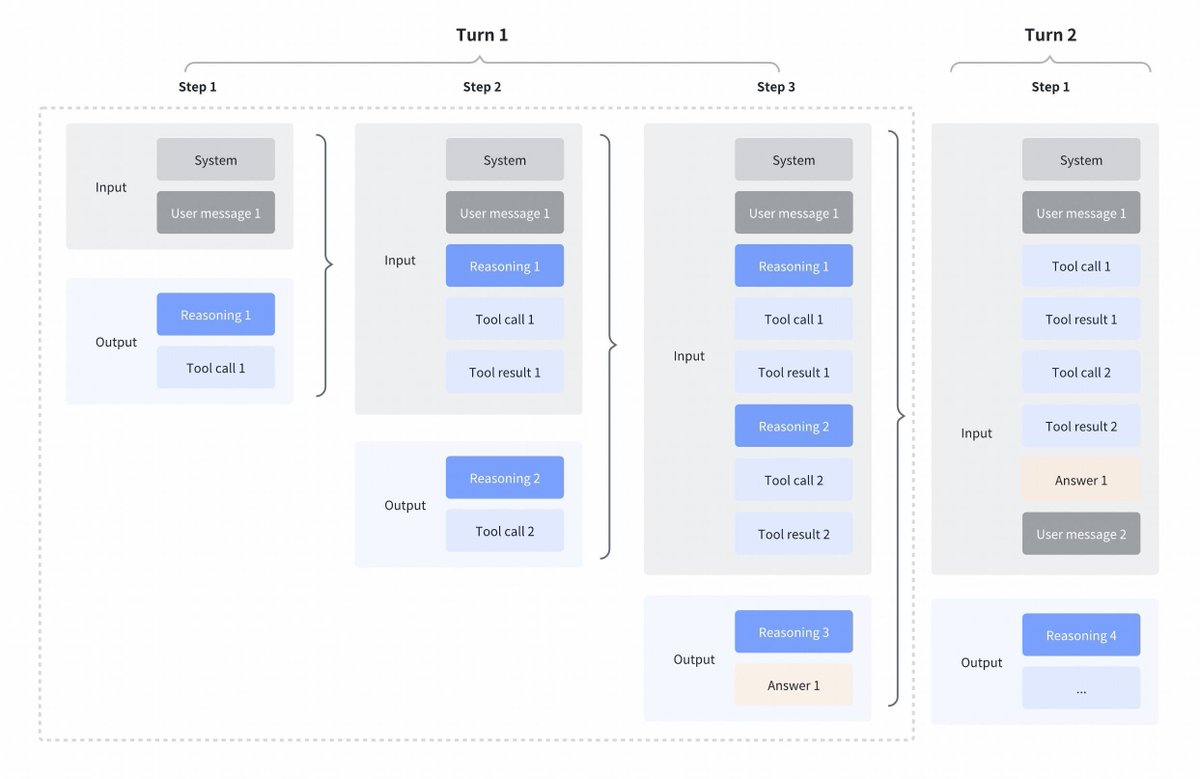
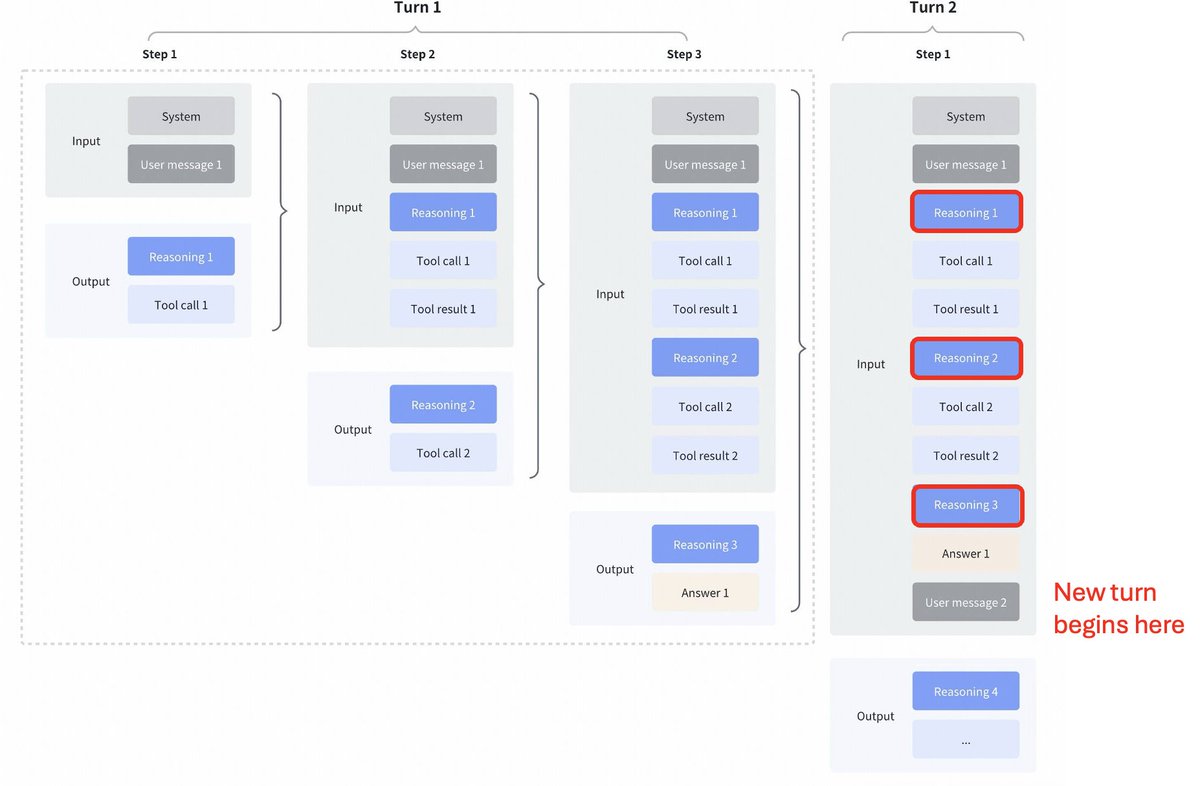
GLM4.7 的策略变化很有意思。 与 Kimi K2 Thinking、DeepSeek V3.2 和 MiniMax M2.1 相比 工具调用之间穿插思考: 所有这些模型都支持工具调用的交错思考,但它们能清晰地反映前一轮的思考,如下面的第一张截图所示。 GLM 4.7 中保留的思维模式: 相比之下,GLM 4.7(仅用于编码端点)保留了先前回合的推理,如下面的屏幕截图所示(注意红色方块)。 对于另一个 API 端点,其行为与之前相同(丢弃前几轮的推理)。 由于模型将拥有历史上下文信息,这肯定会提升一些性能。 正如 @peakji 所建议的,模型需要了解过去的思考过程才能在后续决策中做出正确的判断。这虽然违背了上下文压缩的原则,但我认为在编码场景下可能是非常值得的。 我希望他们能把它做成可配置的,这样我们就能亲眼看到效果了。