大家都知道大模型是有tokenizer的,記錄著大模型使用的分詞表,也是大模型理解語意和進行計算的最小單位。但不知道大家有沒有過這樣的腦洞?為啥要分詞?依照UTF-8編碼直接塞進去不是更好嗎? 來看今天這個新模型,Bolmo-8B,他們就是直接拋棄了傳統的方式,而是使用UTF-8 位元組作為基本單位,把每個字元都看成字節序列來處理
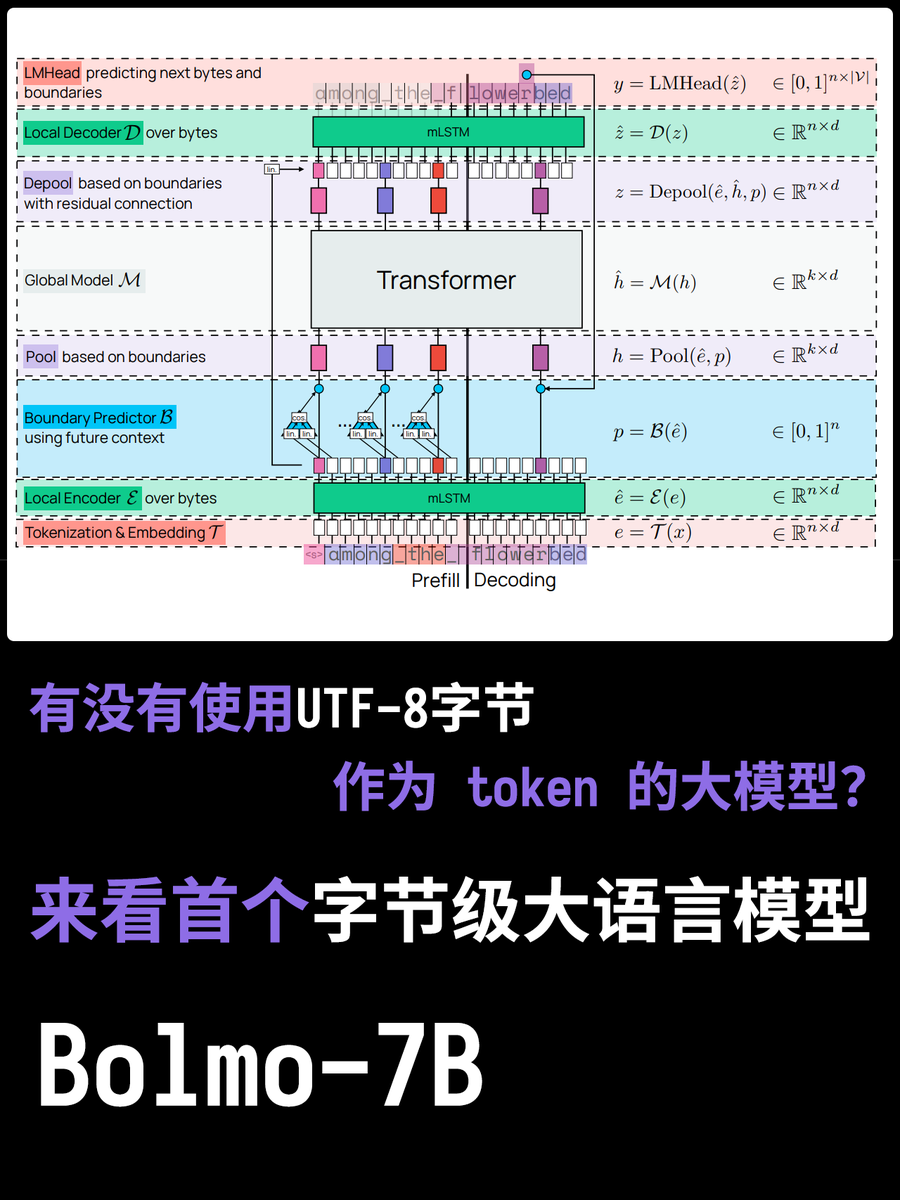
這麼做最大的好處是-"strawberry有幾個r?"這樣的問題就能輕鬆回答了!因為每個字母都是單獨的utf8編碼。 但是帶來的問題也是實打實的,有的時候一個詞可以很複雜,單有的時候一個詞很簡單,傳統tokenizer能不同程度的平衡這個問題,但是輪到用utf8,每個詞都要消耗單詞長度的token,計算資源分配很不靈活。
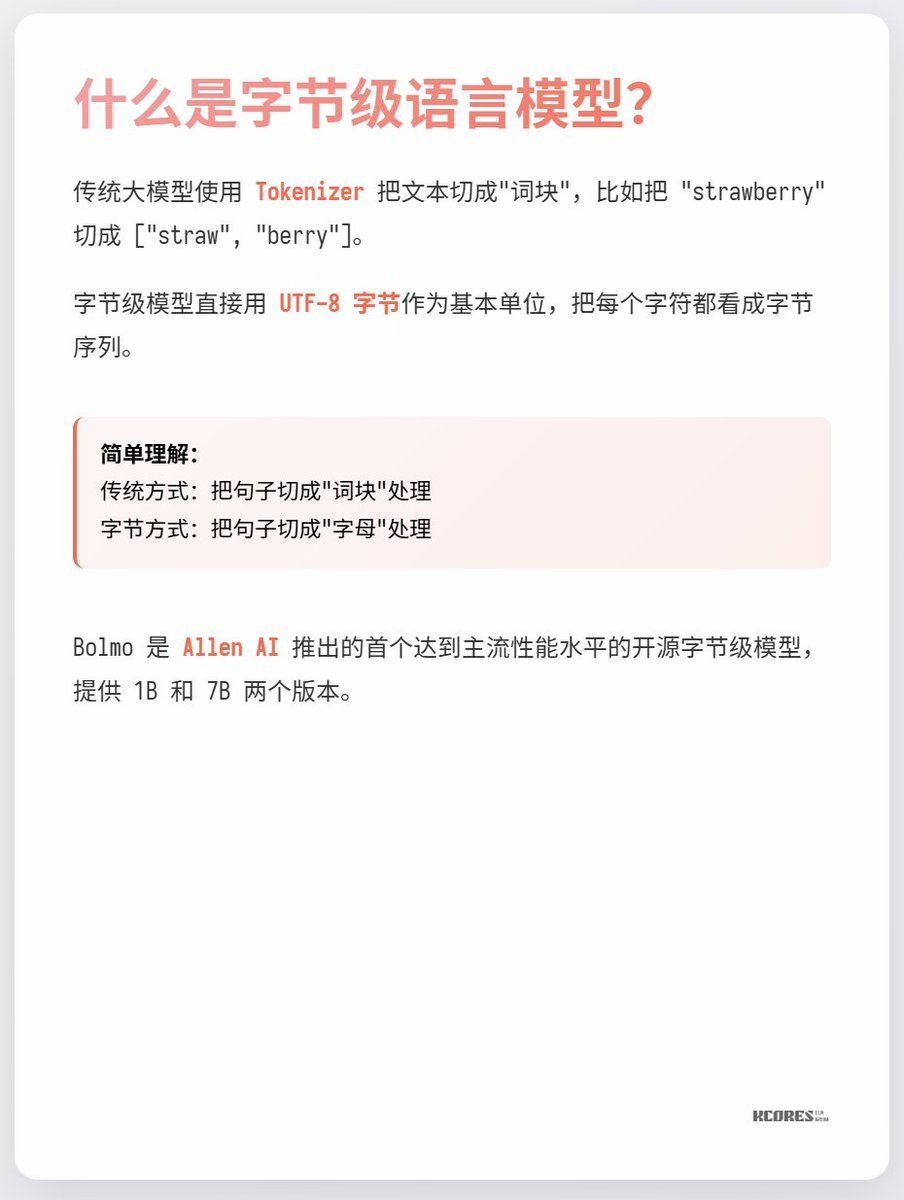



而Bolmo 這個模型取了個巧,他不是從0訓練的,而是把現有的模型"字節化", 它內置了個Local Encoder/Decoder, 將字節序列壓縮成"潛在token",再送入傳統Transformer 處理。這樣只需要少量的成本就能轉換了。

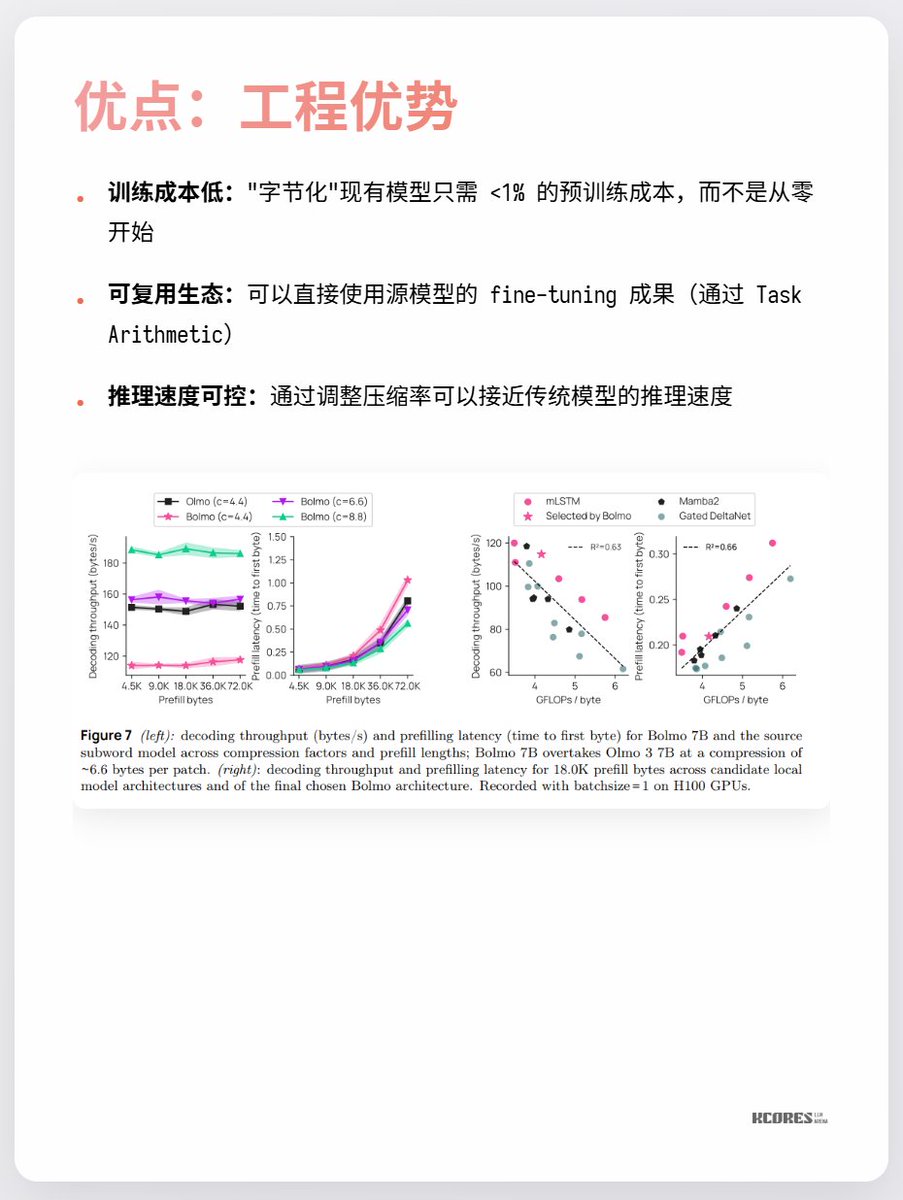

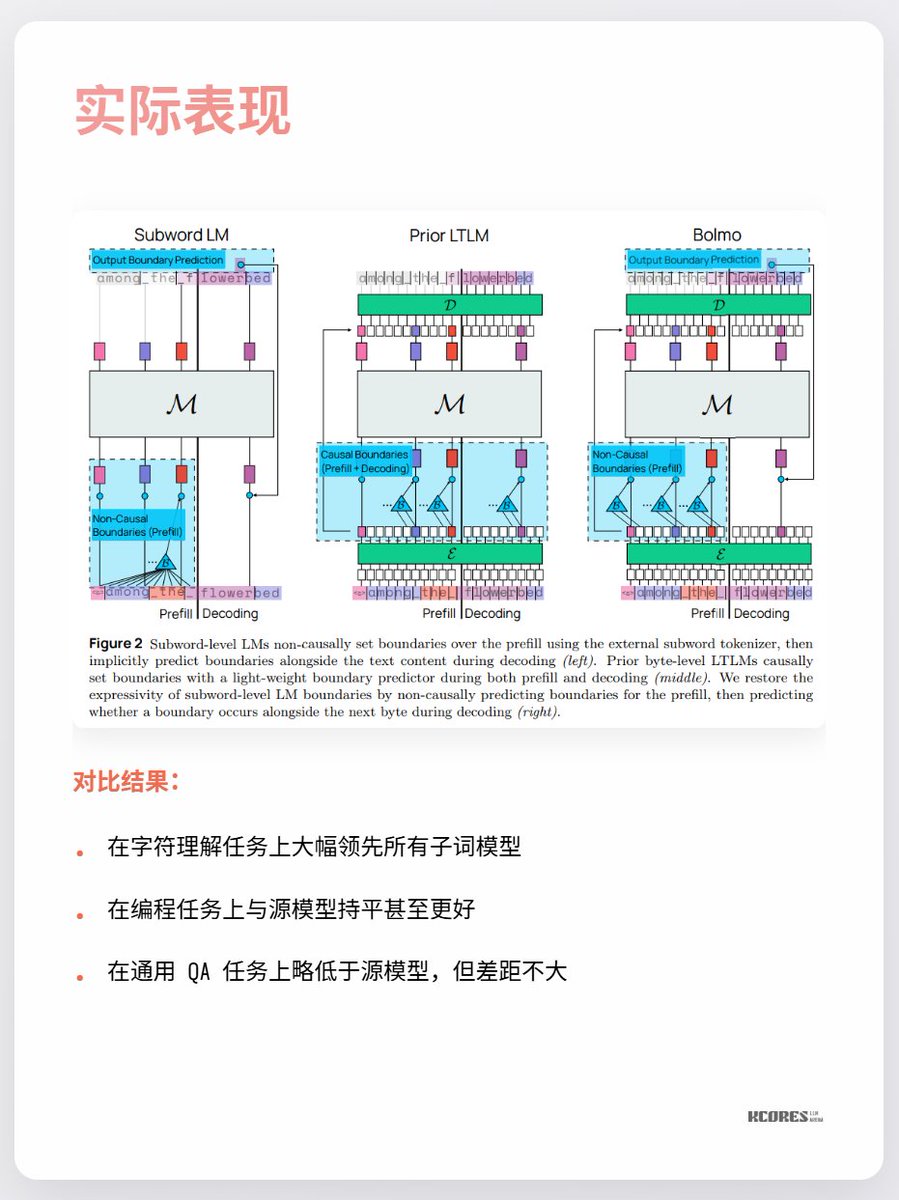
目前大家最大的爭議還是,看不到太大的受益,以及,更長的序列意味著更多的KV Cache,顯存壓力更大。以及,只有在字符理解這個單一任務上大幅領先,其它任務沒太大亮點。 總之可以持續關注下。科技爆發時期的螺旋探索總是很有趣的,像是我就比較喜歡水銀整流器(最後一張圖),但是現在都被IGBT取代了。

