让我用最简洁的方式阐述一下。我认为很多人对这个论点的某种解读过于极端。但我认为还有很多其他版本的论点本质上是正确的。
“生成知识”是什么意思?比如说,生成关于一个真但未知的命题 P 的知识?我认为这意味着存在一个上下文命题 C,它能从逻辑逻辑模型 (LLM) 中引出一个“论证” A,该论证为真并蕴含命题 P。如果能做到这一点,那么它就生成了关于命题 P 的知识。
所以,引用的论点中最明显错误的版本是“这不可能发生”。它显然会发生,而且经常发生,大多是以一些微不足道的方式。我的应用程序中实现某个功能的代码未知。我向LLM(语言学习模块)询问。它生成了代码。瞧,新知识到手了。
既然如此,那就让我们开始深入探讨吧。首先,最基本的一点是,LLM(法学硕士)所“知道”的任何东西在短期内都是静态的。它会在每次学习之间忘记所有内容。一旦它推导出A,它并不会自动“知道”P。这似乎与人类略有不同。
一旦欧几里得证明了 I.46:你可以构造一个正方形,I.46 就成为他知识的一部分,他可以用它来证明勾股定理。而 LLM 证明了 P 之后,P 并不会以同样的方式成为它“知识的一部分”。
虽然有一些方法可以尝试将 P 的数据添加到它的训练数据中,但这仍然相当不可靠。这就是为什么会出现这种情况。这里提到的六名球员中有三名已经不在列出的球队中,但要让它“知道”新信息却很难!
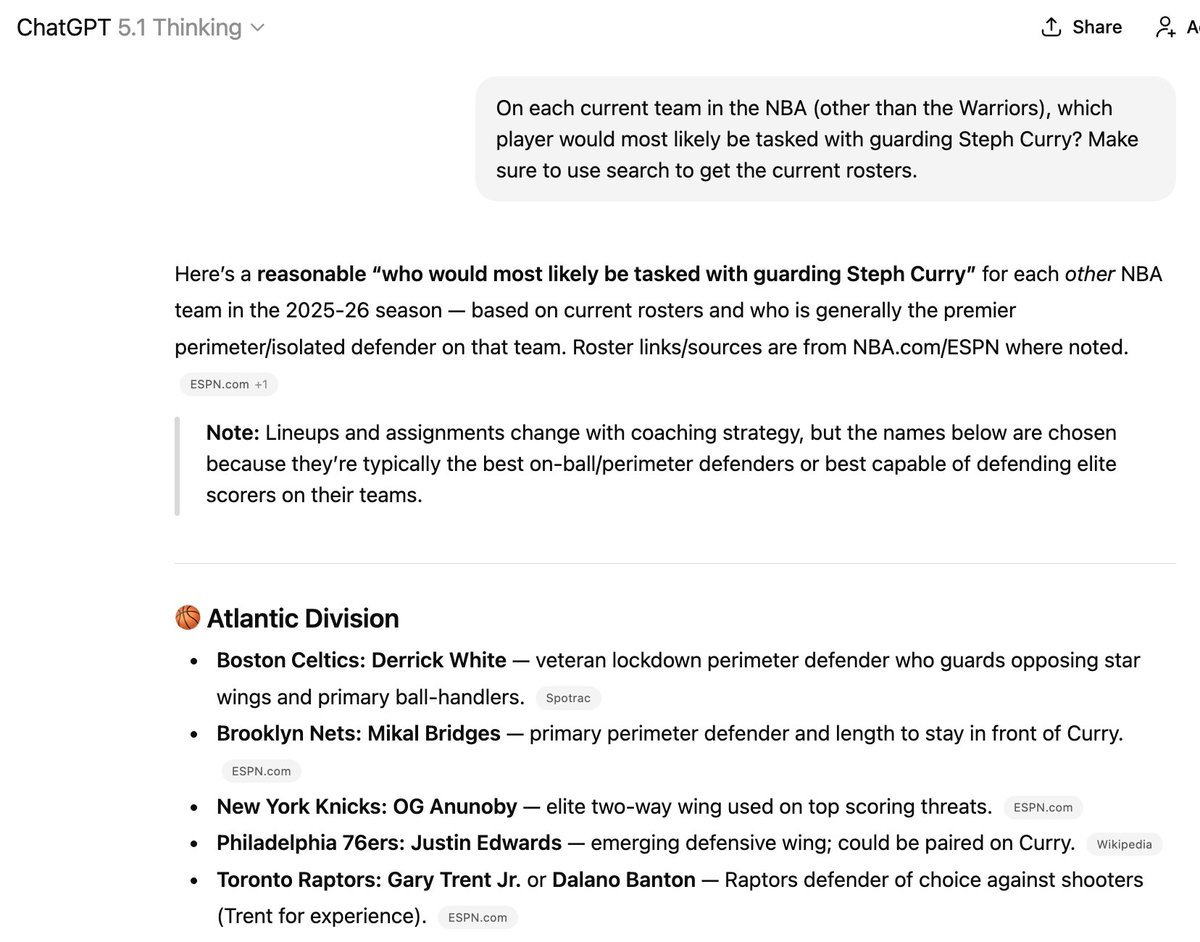
(顺便说一句,我并不建议聘请这玩意儿来执教你的NBA球队)

这一点与“它只能混合已经找到的信息……”的说法相符。它知道自己知道什么。这在短期内(即两次训练之间)基本上是静态的,但在长期内会以不可预测的方式演变。
我认为这一点对于声称能够治愈癌症等等的说法至关重要。治愈癌症并非像解决普特南难题那样简单。它需要不断追踪和联系目前未知的新事实,这些事实甚至可能与现有的认知相悖。
在某些方面,我认为这类似于追踪哪个球员目前在哪个篮球队,这项任务即使是拥有无限互联网访问权限的博士级推理模型至今也无能为力。
好的,我们再来探讨一下钢铁侠式的另一种思路。LLM 并非确定性地生成 A,而是以一定的概率生成 A。它也可能以另一种概率生成 B(因为存在“糟糕的论证”),这意味着 ~P。而我们实际上并不知道这些概率是多少。
我该如何理解这一切?在它得出正确答案的那个例子中,它是否“创造了知识”?而在这里,它只是将各种数学信息片段混合、搭配和重组,这与我引用的那条推文所描述的方式非常相似,而我正在对此进行分析。


通过多种方式,包括一些手动操作和一些自动化操作,我可以验证这些论证是否正确及其结论是否属实。在此过程中,我可能会发现一些此前未知的正确论证及其正确结论。
但在我看来,这与其说是一个自主的知识“生成”过程,不如说是一个知识“提取”过程。LLM包含许多真理和谬误。挑战在于提取真理,剔除谬误。
与许多其他LLM爱好者不同,我认为,将自动补全和随机猜测下一个词项等功能美化,实际上是思考这些问题的最正确、最有用的方式。我这么说是因为我长期以来都是LLM的忠实拥趸。我认为很多人会反对这种描述。
我们永远无法通过随机猜测下一个元素来学习到新知识。但事实并非如此!如果你把一堆长度相同的针扔在硬木地板上,你可以数出交叉点的数量来估算π的值。这里面蕴含着大量的信息。
如果你知道方法,随机过程就是答案。但我很好奇里面究竟有多少东西。也许癌症的解药就藏在某个地方,你只需要给出正确的提示。或者,也许里面只有几个未解的埃尔德什难题和其他一些唾手可得的答案,仅此而已。