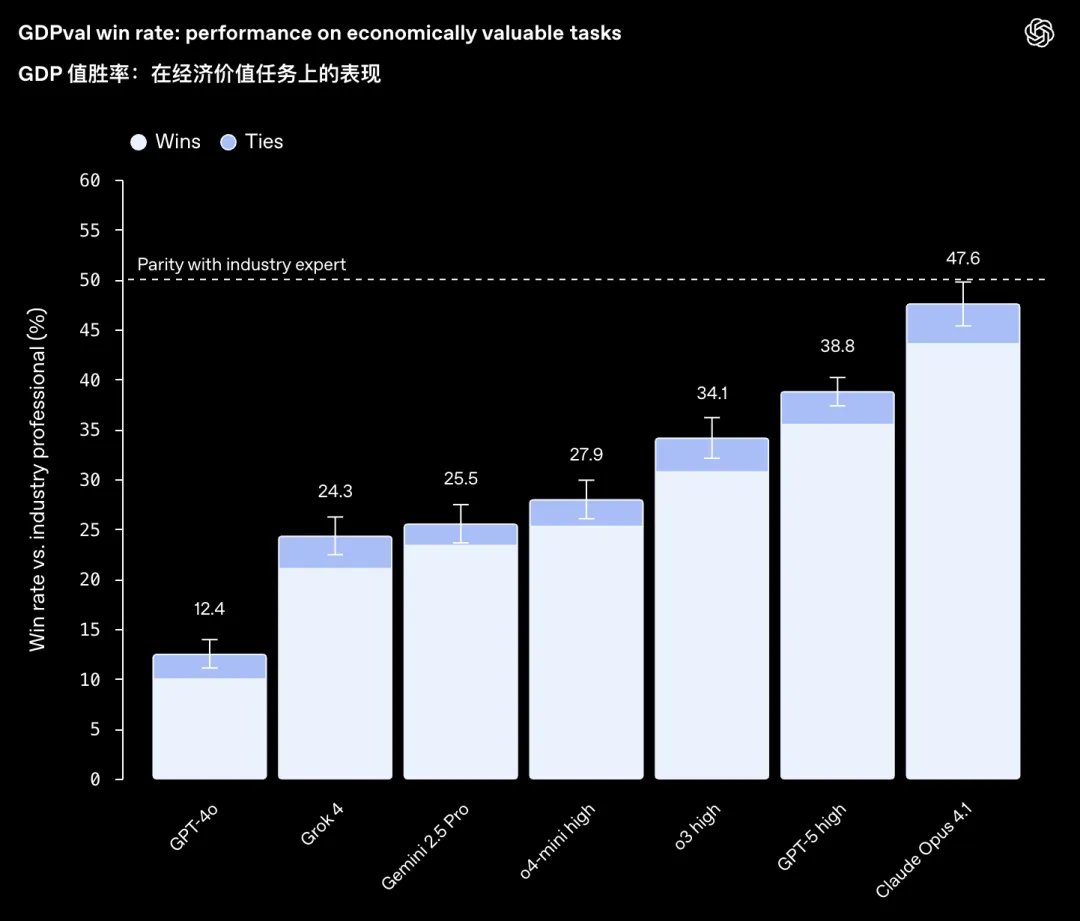
Sam 狂喜,OpenAI 的年底答案GPT 5.2 正式發布 不要被他的版本號欺騙,這是今年OpenAI 的年底大招。 官方定位是:迄今為止面向專業知識工作的最強大模型。 模型效能大幅提升,價格也大幅提升了40%。 在降本的大趨勢下,車型漲價,一般都需要底氣。 這個模型的底氣在哪裡? 前陣子OpenAI 設計了GDPval,一個以國內生產毛額(GDP)這個關鍵經濟指標為靈感。 1320個專業任務,涵蓋了美國GDP 貢獻排名前9 大行業中精選出的44 個職業。 任務要求提交真實的成果作品,例如銷售簡報、會計電子表格、急診排班表、製造流程圖,或短影片。 剛發表GDPval 的時候,Claude Opus 4.1 以47.6 的分數遙遙領先。 但今天, GPT-5.2 直接把分數刷到了70% 以上。
Coding 編碼能力 SWE-Bench Pro 是一項針對真實世界軟體工程的嚴格評估。 與僅測試Python 的SWE-bench Verified 不同,SWE-Bench Pro 測試四種語言,並致力於具備更強的抗污染能力、更高的挑戰性、更豐富的多樣性以及更強的工業相關性。 GPT‑5.2 Thinking 在SWE-Bench Pro 上取得了55.6%的全新最先進水準。超過了Claude Opus 4.5 的52% 和Gemini 3 Pro 的43.3% 。

GPT‑5.2 在長上下文推理領域樹立了新的產業標竿。 MRCR v2(多輪共指消解)指標衡量的是,多個完全相同的「針」式使用者請求會被插入到由大量相似請求和回應組成的「 haystack」長文件中,然後要求模型重現第n 個「針」對應的回應。 GPT‑5.2 的第一個在4 針MRCR 變體(最長可達256k token)上達到接近100%準確率的模型。

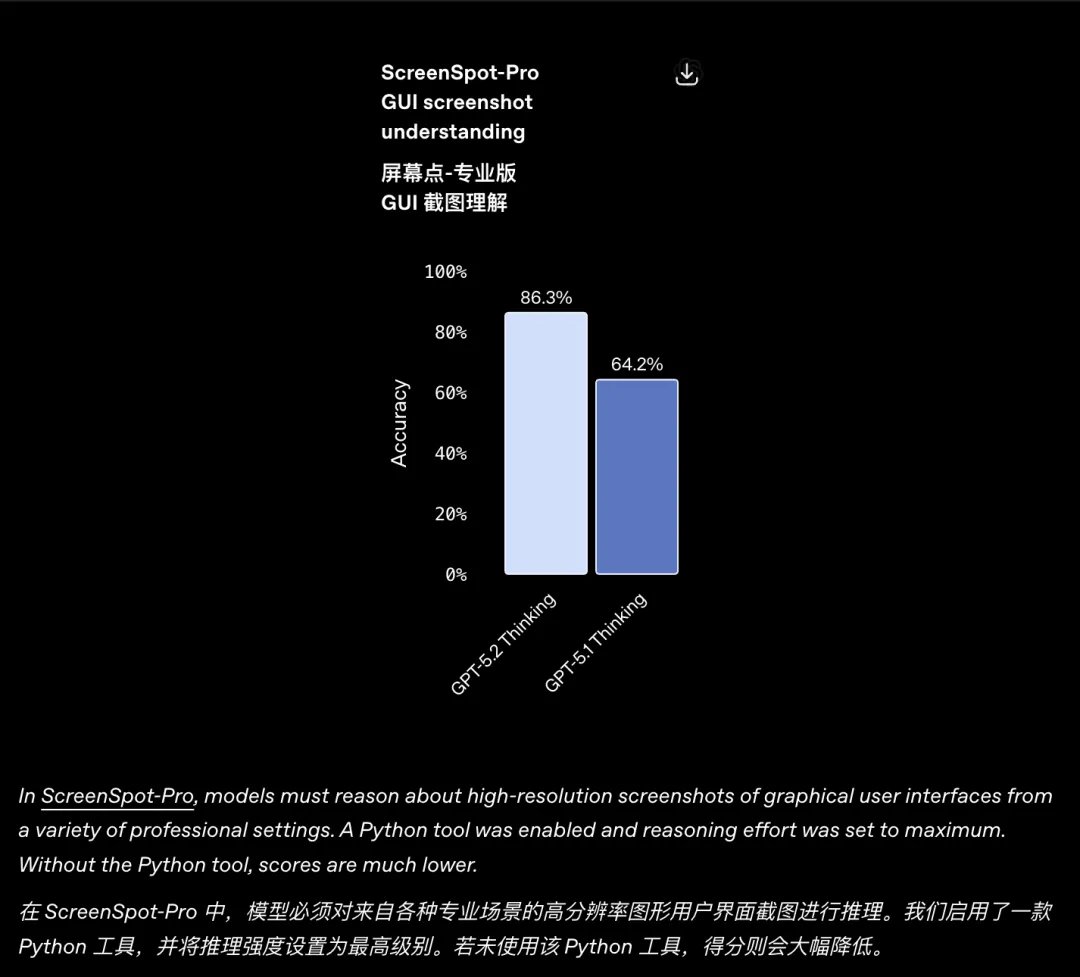
幻覺降低 GPT-5.2 的另一個重大進步在於顯著降低了「幻覺」。錯誤率相比前代降低了30%。 視覺理解 GPT‑5.2 Thinking 在圖表推理和軟體介面理解任務上的錯誤率幾乎降低了一半。

普通版:輸入1.75 美元,輸出14 美元。 專業版:輸入21 美元,輸出168 美元。 整體比GPT 5.1 漲價40% 。 太強了。 太貴了。 AI 今年的趨勢,一個是文字模型漲價(GPT 5.2),一個是圖像模型漲價(banana Pro)。 AI 明年的趨勢,會不會是,視訊模型漲價?
