ChatGPT 的記憶系統非常優秀,但是記憶系統資源消耗一般很大,OpenAI 是如何做到讓記憶系統服務8億用戶的呢? 有人逆向工程了ChatGPT 的記憶系統,發現ChatGPT 的記憶系統比預想的要簡單得多。 沒有向量資料庫,也沒有對聊天記錄進行RAG。 相反,它使用了四個截然不同的層次: 適應你環境的會話元資料、 長期儲存的明確事實、 近期聊天的輕量級摘要, 以及目前對話的滑動視窗。 這篇部落格將詳細分解每個層次的工作原理,以及為什麼這種方法可能優於傳統的檢索系統。

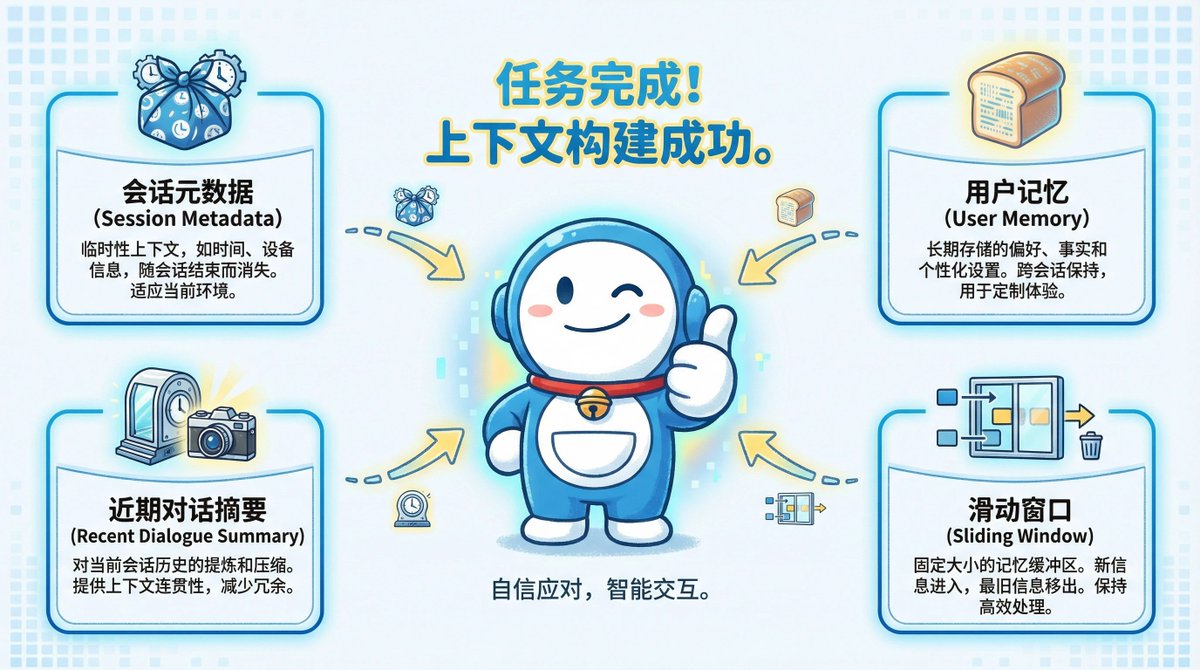
它的核心就是一個四層上下文堆疊。 每次對話,AI都會建造這個“檔案袋”,將關於你的所有關鍵資訊一次性注入模型。 它由四個協同工作的層次組成。

第一層是暫時的環境訊息,例如你的設備和位置,會話結束即消失。 第二層則是你的永久個人檔案,儲存你要求它記住的關鍵事實。

第三層是你近期興趣的“鬆散地圖”,只包含聊天標題摘要,而非全文。 最底層則是當前對話的完整記錄,像滑動窗口,保證即時連貫性。 如果視窗滿了會怎樣?

滑動視窗的意思是,即使當前對話視窗因達到長度限製而“滑動”,最早的消息被移除,你的永久記憶和近期興趣摘要依然會被保留。 這確保了即使在長對話中,AI也不會「忘記」你。
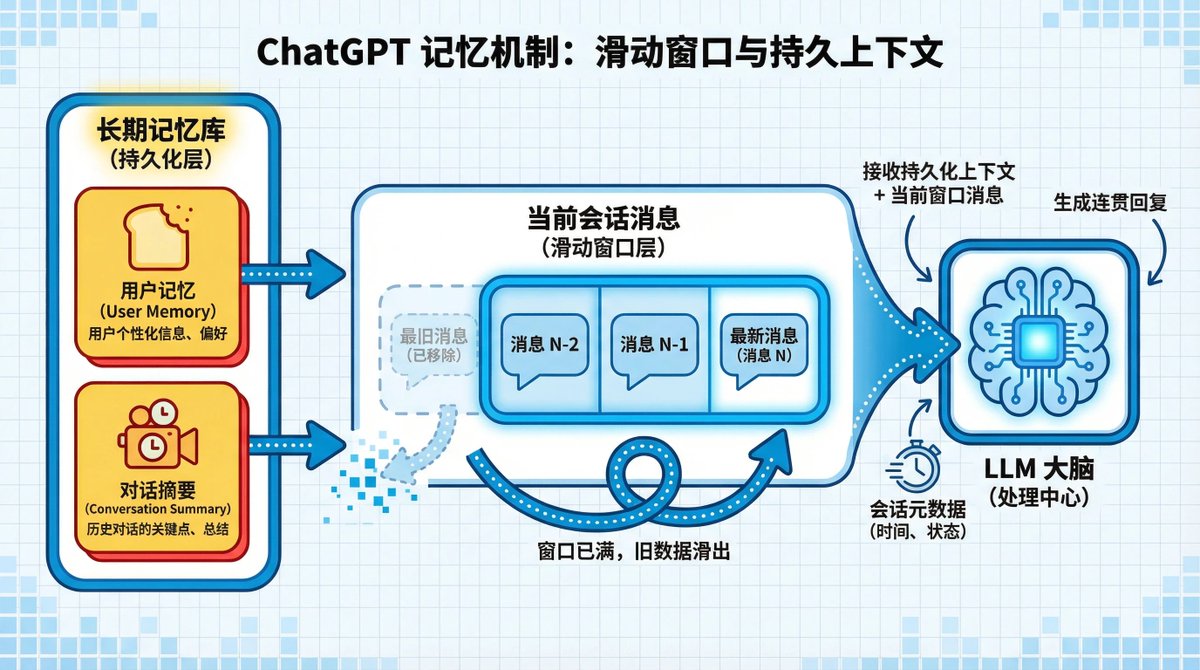
這個四層結構,是工程智慧的勝利。它在個人化、效能和運算成本之間取得了完美的平衡,無需最複雜的系統也能提供最佳的使用者體驗。

這樣,你擁有了一個既能快速回應,又感覺越來越懂你的智慧助理。 文章配圖: ListenHub PPT 原文連結: