几天前,我在 @NeurIPSConf 上展示了我们获得 2025 年 BEHAVIOR 挑战赛第一名的解决方案。现在,我们已经开源了我们的解决方案:代码、模型权重和一份详细的技术报告。 让我来详细说说我们做了什么👇
什么是行为挑战? 在这场比赛中,我们必须训练一个策略,使其能够在高质量的模拟环境中完成 50 项机器人家务任务。 该策略控制的是一个带有移动底座的双手人形机器人,任务持续时间从 1 分钟到 14 分钟不等。 请阅读@drfeifei的帖子了解更多详情: https://t.co/jDviv5d6pB
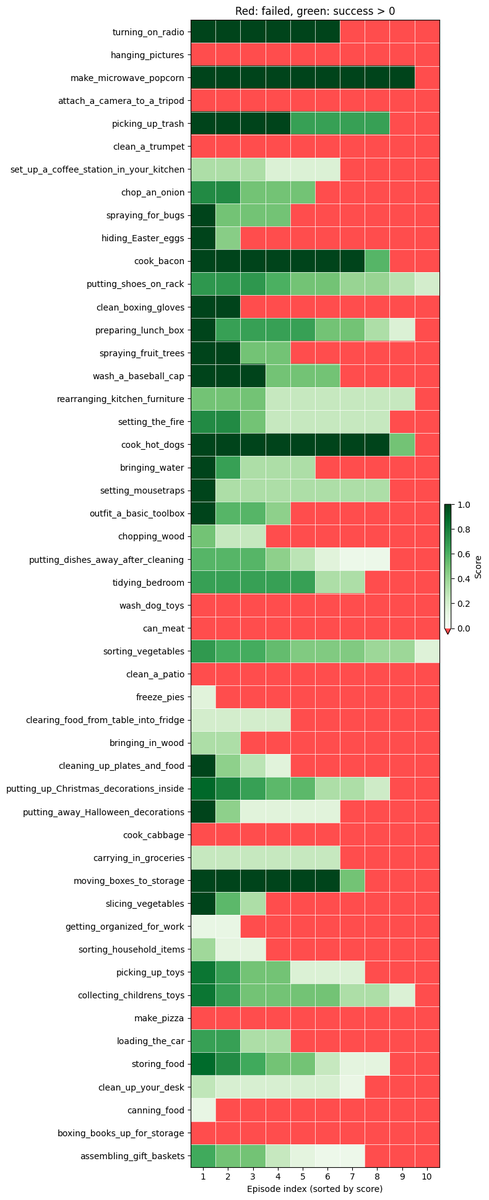
我们独立团队由我、@zaringleb 和 @akashkarnatak 组成,以 26% 的 q 分数(包括完全成功和部分成功)获得第一名。
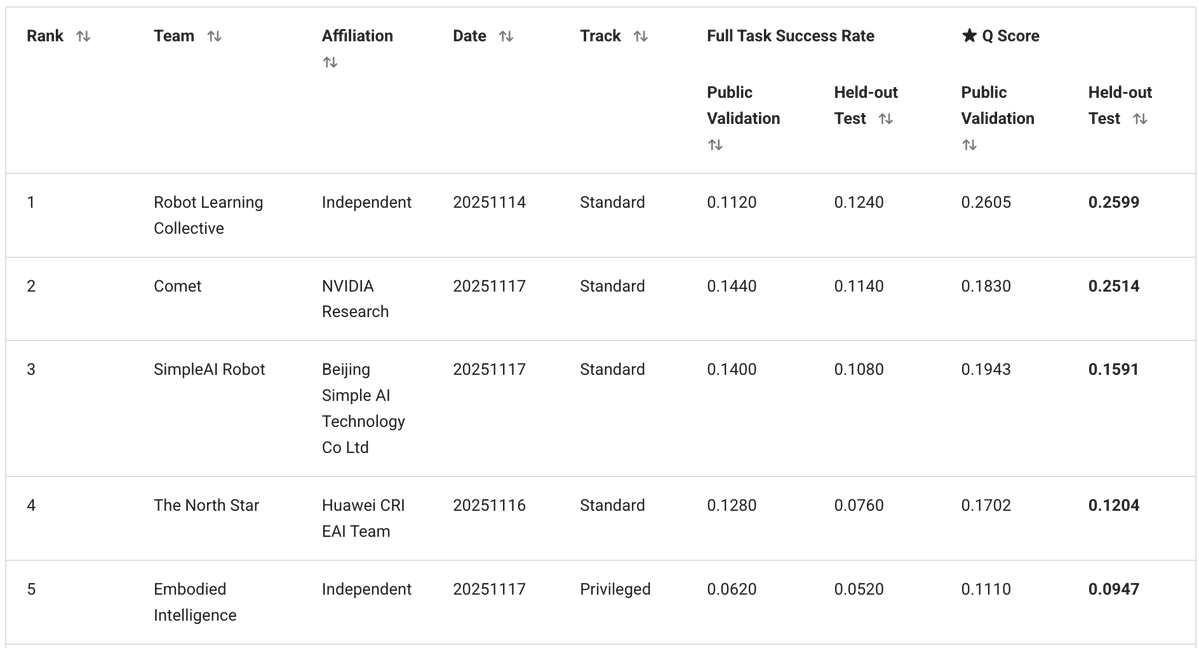
我们的解决方案基于 @physical_int Pi0.5 VLA,并构建于 openpi 仓库之上。 我们对模型以及训练和推理过程进行了大量修改。
- 行为模型有一组固定的 50 个任务。我们不需要将其推广到新的文本提示,因此我们完全删除了文本,并用 50 个可训练的任务嵌入(每个任务一个)代替了它。 - 训练数据集包含多种模态(RGB、深度、分割)以及额外的子任务标注,但我们坚持采用简单的方法:仅使用 RGB 图像 + 机器人状态。 - 我们预测 30 步动作块(1 秒),并使用按时间戳归一化的增量动作。
许多画面看起来相同,但对应的却是截然不同的子任务。 例如,在这两张图片中:一张图中微波炉是空的,机器人应该先打开它;另一张图中爆米花已经在里面了,机器人应该启动微波炉。你能猜出哪张图是哪张图吗? 这对机器人来说也很困惑。默认情况下,垂直阵列机器人没有记忆功能,所以它们不知道下一步该做什么。


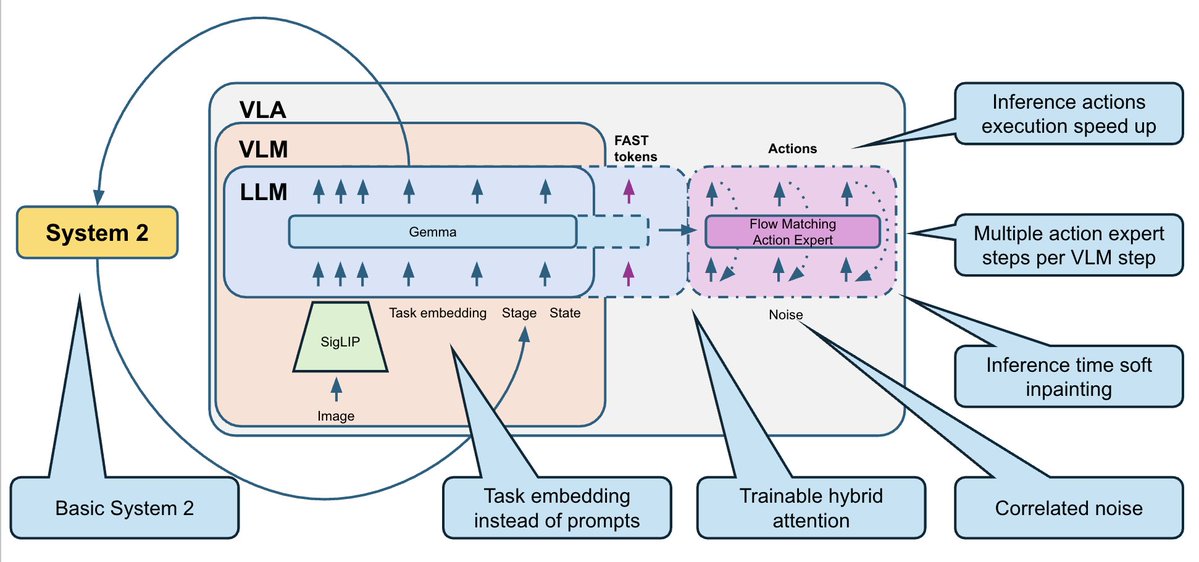
为了解决这个问题,我们添加了一个非常基础的系统 2 逻辑,用于跟踪任务完成进度: - 我们训练 VLA 来预测当前阶段,作为辅助头。 同时,它还可以利用舞台来解决当前画面中的歧义。 - 在推理过程中,我们使用投票逻辑平滑阶段预测:阶段只能逐步进行(0、1、2、3、...)。 我们将舞台数据作为额外输入反馈到模型中。 这为策略提供了额外的任务进度上下文,并修复了许多“我忘记了自己在哪里”的错误。
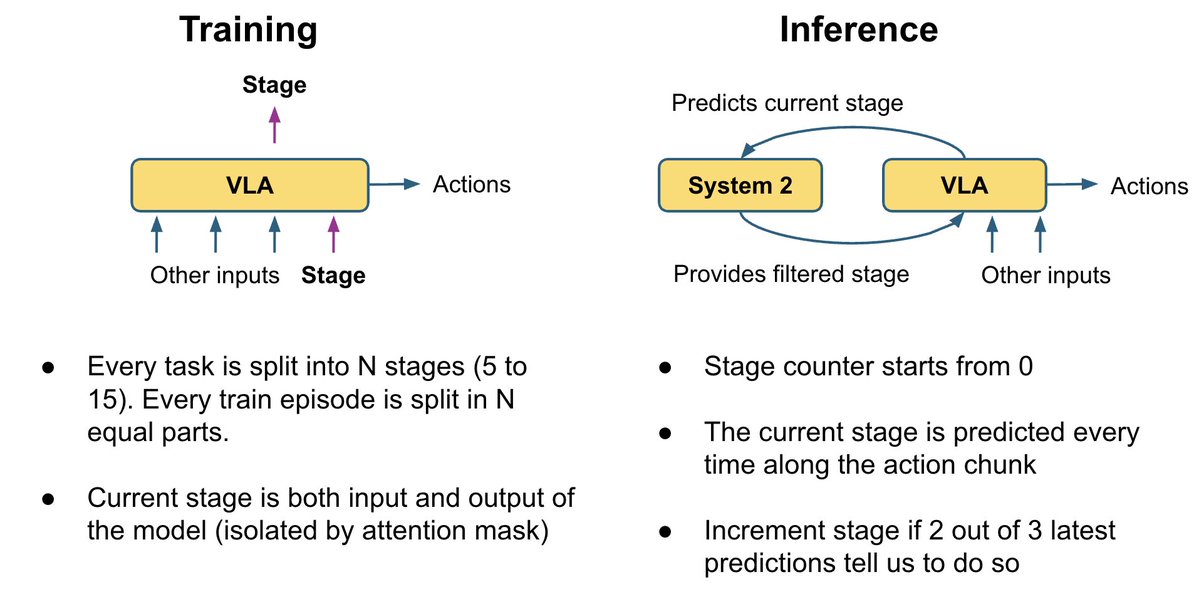
不同的VLA论文以不同的方式将动作头连接到VLM层:有些关注所有VLM层,有些跳过一半,有些只关注最后一层;有时会使用单独的交叉注意力机制和自注意力机制,有时则会将它们混合使用。我们没有选择并硬编码其中一种方案,而是让模型学习每个动作层的最佳组合。 我们的动作专家关注所有 VLM 层的可训练线性组合,从而能够学习每个动作层的最佳组合。
标准流匹配使用独立同分布的高斯噪声。然而,机器人动作在时间和关节间都具有高度相关性。 这导致流程匹配步骤的难度不均:最初的步骤要困难得多,而后面的步骤则容易得多,因为模型可以利用已知的相关性作为捷径。 相反,我们使用来自 N(0, 0.5 Σ + 0.5 I) 的噪声,而不是 N(0, I),其中 Σ 是从数据集中估计的动作协方差矩阵。这样做的目的是使所有步骤的难度更加一致。
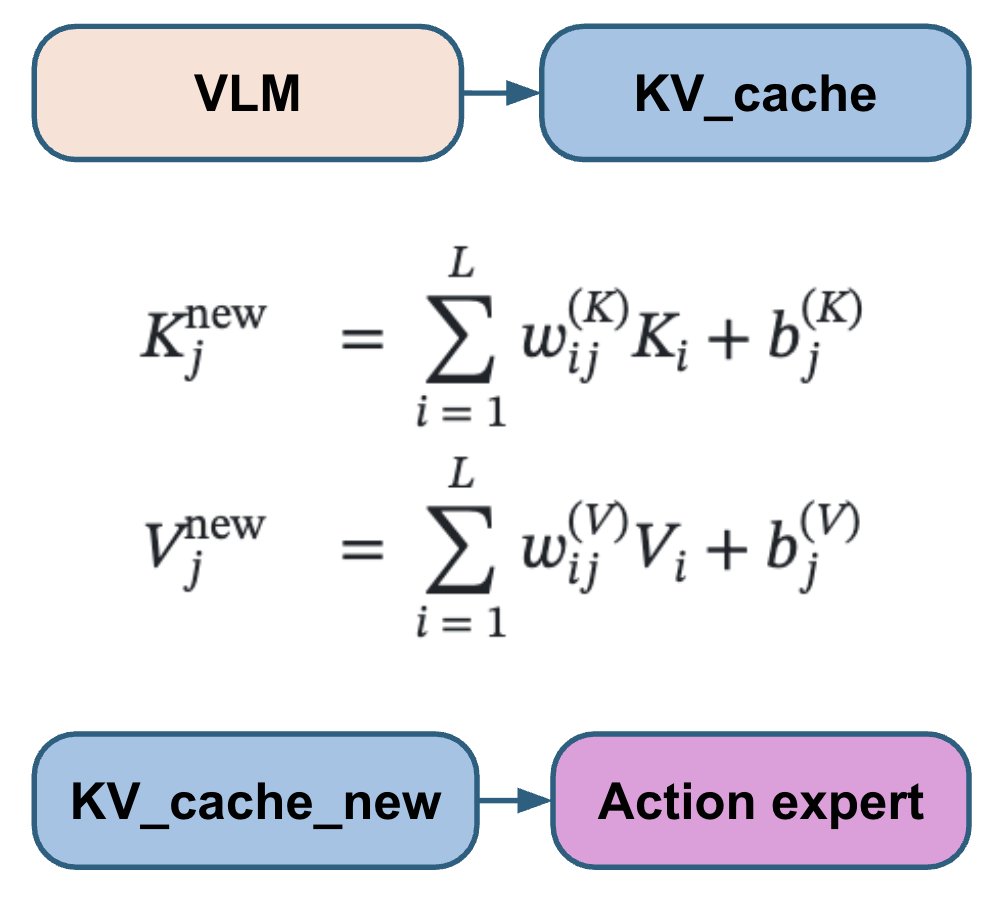
VLM 部分是整个模型中最复杂的,而且是确定性的。流匹配动作专家相对较小,但其训练依赖于两个随机变量:t 和噪声。最终,来自动作专家的带噪声梯度会反馈到 VLM 部分。 为了改进这一点,我们抽取 15 个不同的 (t, noise) 对,并对每次 VLM 前向传播运行 15 次动作专家算法。这仅需少量额外的计算资源,但能使动作专家算法得到的梯度更加稳定。
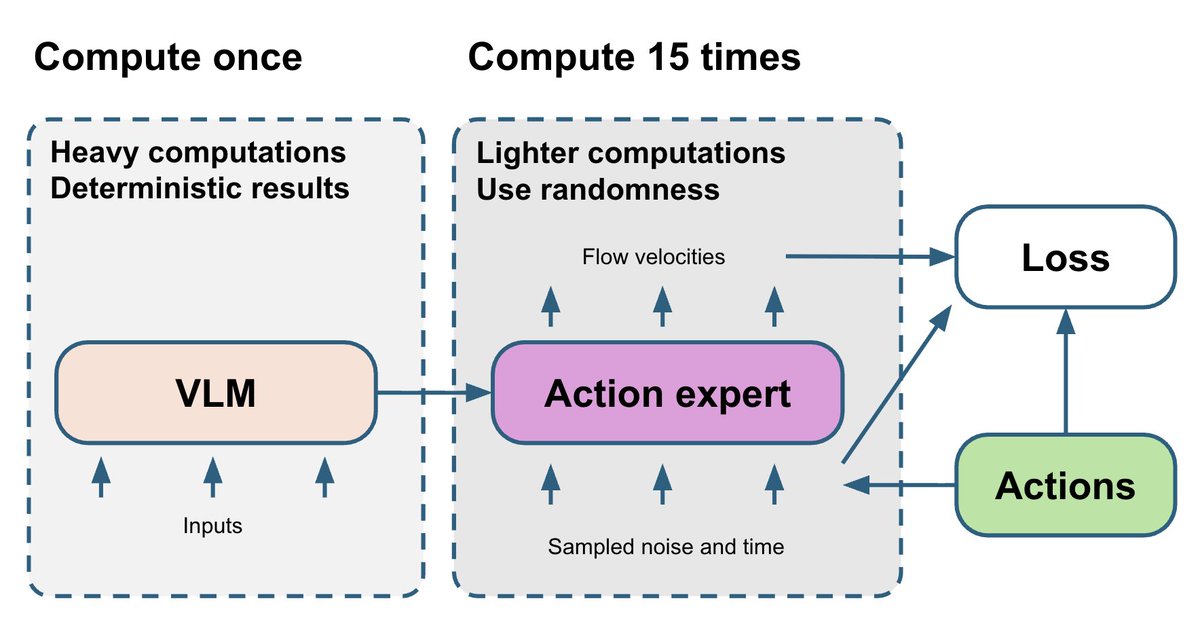
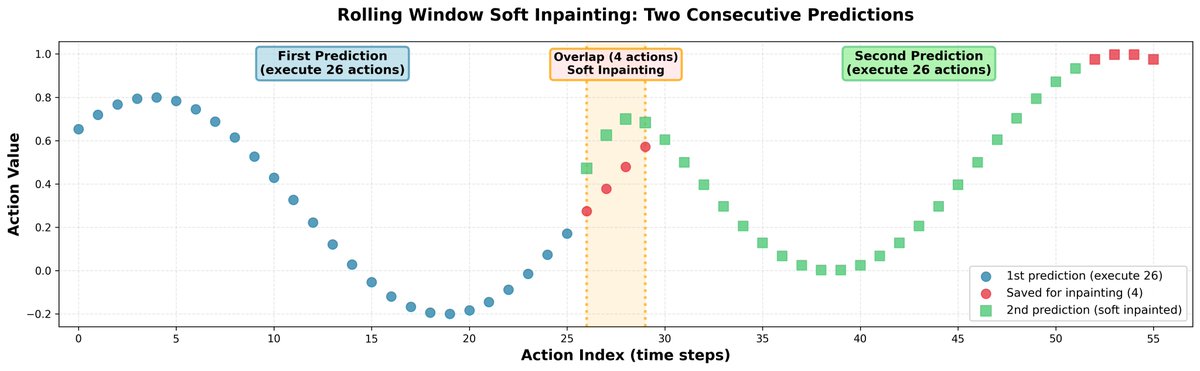
在推理过程中,预测完全独立的动作片段会导致轨迹跳跃,并使策略出现犹豫不决的行为。为了解决这个问题,我们通过图像修复将所有片段连接起来: - 我们一次预测 30 个动作,但只执行 26 个。 - 剩余的 4 个值用作下一次预测的初始输入。 - 在预测接下来的 30 个动作时,我们对前 4 个动作进行轻微的修正,使它们与之前保存的动作非常接近。 - 为了保持动作之间的相关性,我们使用学习到的相关矩阵将修正传播到剩余的视界。 结果:机器人轨迹平滑,无明显不连续点。
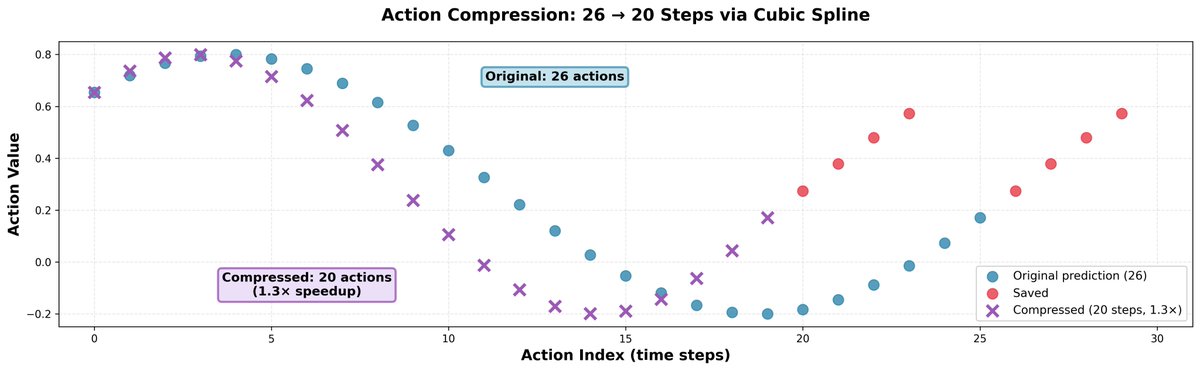
我们发现,比模型预测的速度稍快一些通常会有帮助;它不会降低动作的精确度,但会让机器人速度更快,并允许它在相同的时间内完成更多的事情。 诀窍很简单:我们取 26 个动作,使用三次样条插值将它们压缩成 20 个动作,然后只需分 20 步执行即可。这样可以实现 1.3 倍的速度提升。
这个问题的训练数据集非常干净:没有失败案例,也没有恢复案例。这对机器人策略来说是个问题,因为它们甚至无法学习如何从简单的错误中恢复。 一种常见的情况是:机器人尝试抓取物体但失败了,然后机械臂闭合。接着它就站在那里什么也不做,因为它不知道可以打开机械臂再次尝试。 我们实施了一个简单的启发式规则:如果机械臂处于闭合状态,而在此任务和阶段的任何演示中机械臂从未闭合过,则该规则会打开机械臂。在我们这项小型研究中,这条简单的规则使部分任务的Q值大致翻了一番。
但有时,恢复行为会自然而然地从多任务训练中产生。 在第一个视频中,你可以看到仅基于一个或几个任务训练的策略的典型失败行为。如果它犯了错误(例如,将图片掉到地上),它会完全停止并什么也不做,因为这种情况在训练数据中从未出现过。 在第二个视频中,你可以看到该策略在所有 50 个任务上训练后的恢复行为。由于它已经学习过其他需要从地上捡起物体的任务,因此可以推广到这种情况,并捡起掉落的图片。
计算资源在这场比赛中至关重要。整个训练数据集包含超过1000小时的远程操作数据,在8块H200 GPU上训练一个epoch大约需要两周时间。我们训练策略大约用了30天,相当于大约两个epoch。 我们非常感谢 @nebiusai 为我们提供 GPU 点数赞助,使这一切成为可能。
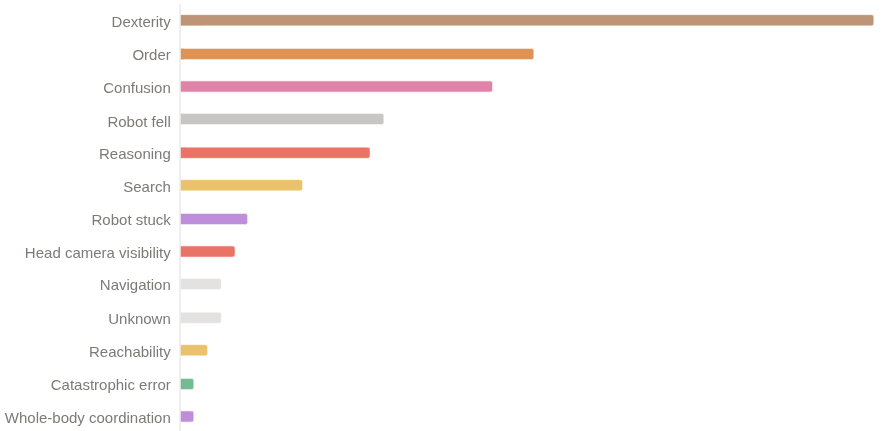
尽管我们获得了第一名,但我们相信仍有很大的提升空间。 我们获得了 26% 的 q 值和 11-12% 的二元成功率。 该政策至今仍未成功的主要原因有: - 灵巧性问题(抓握、松手) 长序列中的进度错误 进入非分布状态后感到困惑
我们已将解决方案中的所有内容开源:代码、模型权重和详细的技术报告。 代码:https://t.co/LLSd6VtbaE 重量:https://t.co/f3ZUF175rV 技术报告:https://github.com/IliaLarchenko/…制一段视频,详细介绍一下。敬请期待🎥