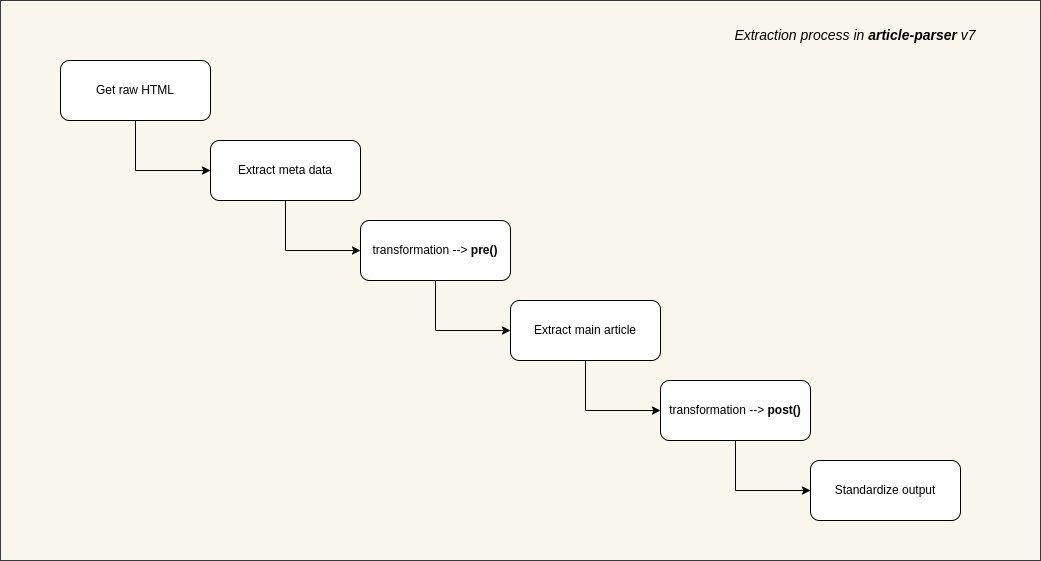
想要抓取網頁內容餵給AI 或做稍後讀應用,最大的阻礙往往不是網絡請求,而是如何從滿屏的廣告、側邊欄和導航裡,精準提取出正文。 最近發現article-extractor 這個開源函式庫,專門用來解決這個問題,能從複雜的URL 中智慧辨識並提取核心文章資料。 能夠自動去除頁面雜質,回到結構化的標題、正文、封面圖、作者甚至閱讀時長。 GitHub:https://t.co/bF0hvCYr8I 支援自訂轉換邏輯(Transformations),允許針對特定網域編寫預處理或後處理規則,大幅提升提取精度。 相容於Node.js、Bun 以及瀏覽器環境,且支援配置代理程式和自訂Headers,方便應對反爬策略。 如果正在開發內容聚合、RSS 閱讀器或需要清洗網頁資料以進行大模型訓練,這個函式庫非常值得加入工具箱。