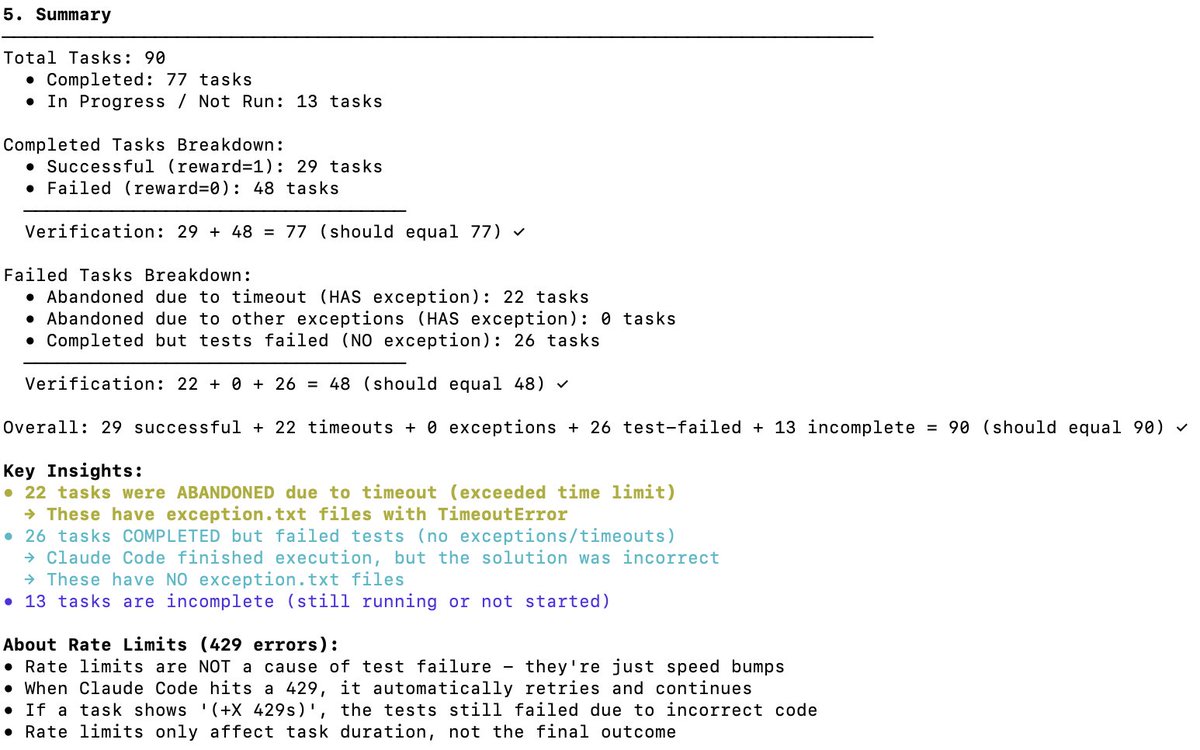
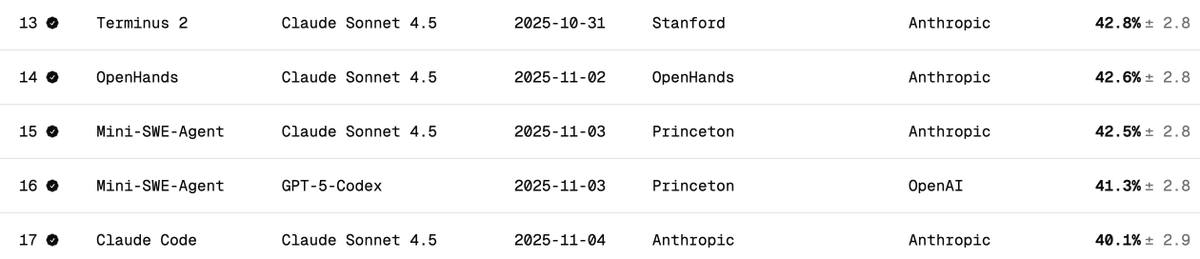
独立验证DeepSeek V3.2在Terminal Bench 2上的性能 终端基准测试用于衡量模型在终端场景(例如 Claude Code、Codex CLI、Gemini CLI)中支持/运行代理的能力。在我看来,这是人工智能软件开发中最重要的逻辑逻辑基准测试。它涉及人工智能如何操作您的命令行界面 (CLI) 来下载软件、开发代码、进行测试等等。 官方比分是多少? 如下表所示,DeepSeek v3.2 的官方得分分别为 46.4(思考型)和 37.1(非思考型)。他们使用了论文中提到的 Claude Code 测试框架。 Claude Code + Sonnet 4.5 在此基准测试中的表现如何? 以下是 Claude Sonnet 4.5 在不同安全带上的终端测试得分。请注意,Claude Code 安全带的得分约为 40%。 使用 Claude Code Harness 运行 DeepSeek V3.2 的得分是多少? 我使用 DeepSeek-Reasoner(Thinking)进行了测试。在近 90 次测试中,Harbor(编排器)停止工作前运行了 77 次。假设这些样本是无偏的,那么 77 这个数字足以说明问题: - 29 - 成功 - 48 - 失败(22 次超时 + 26 次生成错误代码) 这使得得分达到 38%(相当不错,已经接近 Claude Code + Sonnet 4.5 的 40%)。 但可以肯定的是,如果给 DeepSeek v3.2 模型更多时间,它肯定能完成更多超时任务,完成率会远高于 38%——我认为可以达到 50%。但那样就不是公平的比较了(测试创建者建议不要更改超时设置)。 与其他开源软件模型的比较: 以下型号使用 Terminus 2 线束 1. Kimi K2 思考 - 35.7% 2. MiniMax M2 - 30% 3. Qwen 3 Coder 480B - 23.9% 结论: 对于开源软件模型而言,其性能达到了 SOTA 水平,令人难以置信的是,它几乎与 Claude 4.5 相当,然而,我的得分低于 DeepSeek 团队的得分:46.4(再次强调,最后 13 次测试没有运行)。 我怀疑他们可能修改了 Claude 代码的行为。Claude 代码会以特定的方式(例如作为)提示模型,而 DeepSeek v3.2 可能不熟悉或无法很好地处理这些方式。 很高兴得知 DeepSeek 有 Anthropic API 接口,这让使用 Claude Code 进行测试变得非常顺利。我只需要把 settings.json 文件放到 Docker 容器里就行了。 DeepSeek (@deepseek_ai) 应该公开透明地分享他们是如何取得这些分数的。 成本与缓存命中率: 最不可思议的是,运行这 77 个测试只花了 6 美元(Harbor 不知何故放弃了最后 13 个测试)。虽然处理了近 1.2 亿个令牌,但由于大部分令牌都是输入的,并且之后都通过缓存命中(DeepSeek 自动实现了基于磁盘的缓存),所以成本非常低。 向 Terminal Bench 团队提出请求: 请简化恢复未完成任务就已终止的工作的流程。感谢您提供的这项卓越服务。 @terminalbench @teortaxesTex @Mike_A_Merrill @alexgshaw @deepseek_ai