1/n:大多数人忽略的是,DeepSeek 团队已经破解了 LLM 最复杂领域——难题的证明生成——中备受恐惧和追求的自我提升循环。 看看这个循环会在哪一处断裂,应该会很有意思。谁去叫醒埃利泽·尤德科夫斯基! @teortaxesTex
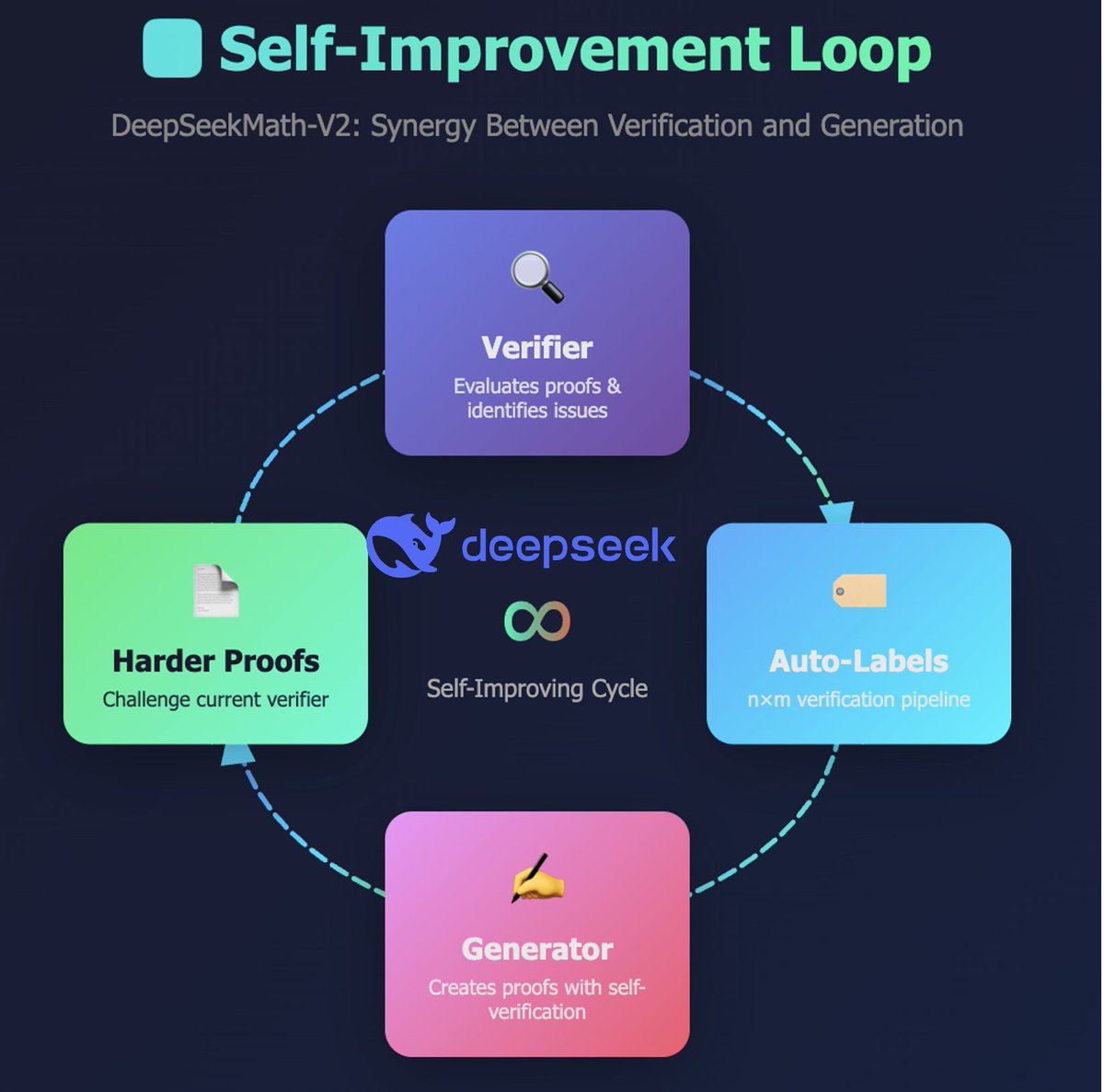
2/n: “我真是太蠢了”时刻(类似于 DeepSeek R1 的“顿悟时刻”) DeepSeekMath-V2论文最重要的技术突破并非达到IMO金牌水平!!!那究竟是什么呢? 它赋予模型可靠验证自身采样生成结果的能力。这对逻辑线性模型(即使是推理型逻辑线性模型)来说一直非常困难。 引用: “当证明生成器无法一次性生成完全正确的证明时——这在IMO和CMO等竞赛的难题中很常见——迭代验证和改进可以在一定程度上提高结果。这包括使用外部验证器分析证明,并提示生成器解决已发现的问题。” 然而,我们观察到一个关键的限制:当被要求一次性生成并分析自己的证明时,生成器往往会声称其正确性,即使外部验证者很容易发现缺陷。 换句话说,虽然生成器可以根据外部反馈改进证明,但它无法像专门的验证者那样严格地评估自己的工作。 这一观察促使我们赋予证明生成器真正的验证功能。 @gm8xx8 @teortaxesTex @rohanpaul_ai @ai_for_success
3/n:DeepSeekMath-V2 模型实际上受到了威胁,不得作弊。 你可以在提示模板里看到。梁文峰是个严厉的家长!!!
