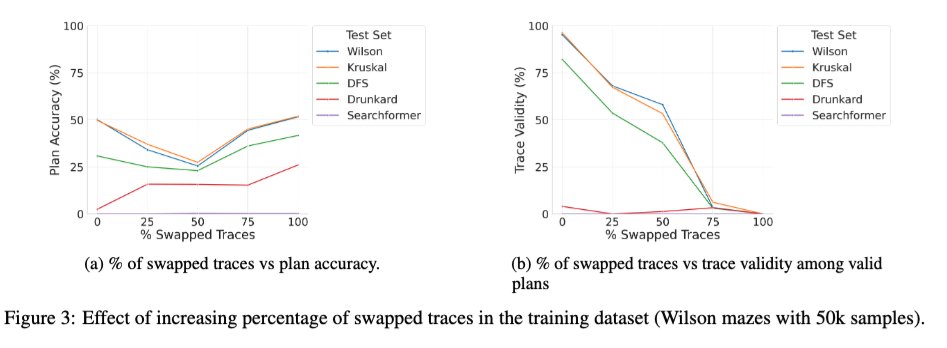
我们刚刚在arXiv上上传了论文《超越语义学》的扩展版本——这篇论文系统地研究了LRM中中间标记的作用——或许你们中的一些人会感兴趣。🧵 1/ 一项引人入胜的新研究探讨了使用正确和错误轨迹混合训练基础Transformer模型的效果。我们注意到,随着训练过程中错误(交换)轨迹的比例从0%增加到100%,模型在推理时的轨迹有效性如预期般单调下降(见下图右侧),但解的准确率却呈现出U形曲线(见下图左侧)!这表明,真正起作用的似乎是训练过程中所用轨迹的“一致性”,而非其正确性。
正在加载线程详情
正在从 X 获取原始推文,整理成清爽的阅读视图。
通常只需几秒钟,请稍候。
共 1 条推文 · 2025年11月26日 16:12
我们刚刚在arXiv上上传了论文《超越语义学》的扩展版本——这篇论文系统地研究了LRM中中间标记的作用——或许你们中的一些人会感兴趣。🧵 1/ 一项引人入胜的新研究探讨了使用正确和错误轨迹混合训练基础Transformer模型的效果。我们注意到,随着训练过程中错误(交换)轨迹的比例从0%增加到100%,模型在推理时的轨迹有效性如预期般单调下降(见下图右侧),但解的准确率却呈现出U形曲线(见下图左侧)!这表明,真正起作用的似乎是训练过程中所用轨迹的“一致性”,而非其正确性。