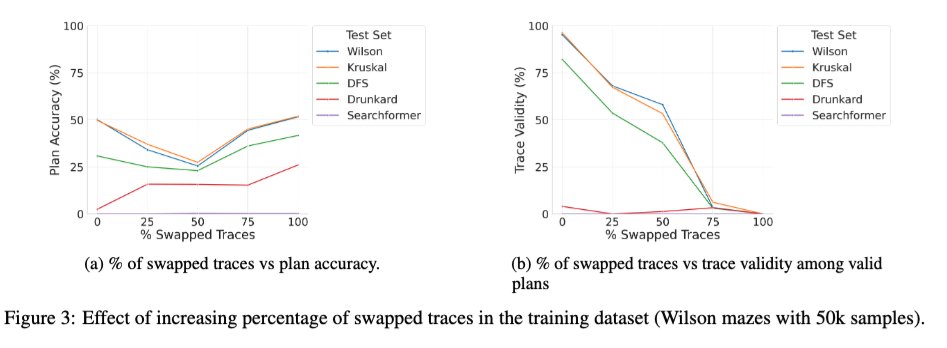
我们刚刚在arXiv上上传了论文《超越语义学》的扩展版本——这篇论文系统地研究了LRM中中间标记的作用——或许你们中的一些人会感兴趣。🧵 1/ 一项引人入胜的新研究探讨了使用正确和错误轨迹混合训练基础Transformer模型的效果。我们注意到,随着训练过程中错误(交换)轨迹的比例从0%增加到100%,模型在推理时的轨迹有效性如预期般单调下降(见下图右侧),但解的准确率却呈现出U形曲线(见下图左侧)!这表明,真正起作用的似乎是训练过程中所用轨迹的“一致性”,而非其正确性。
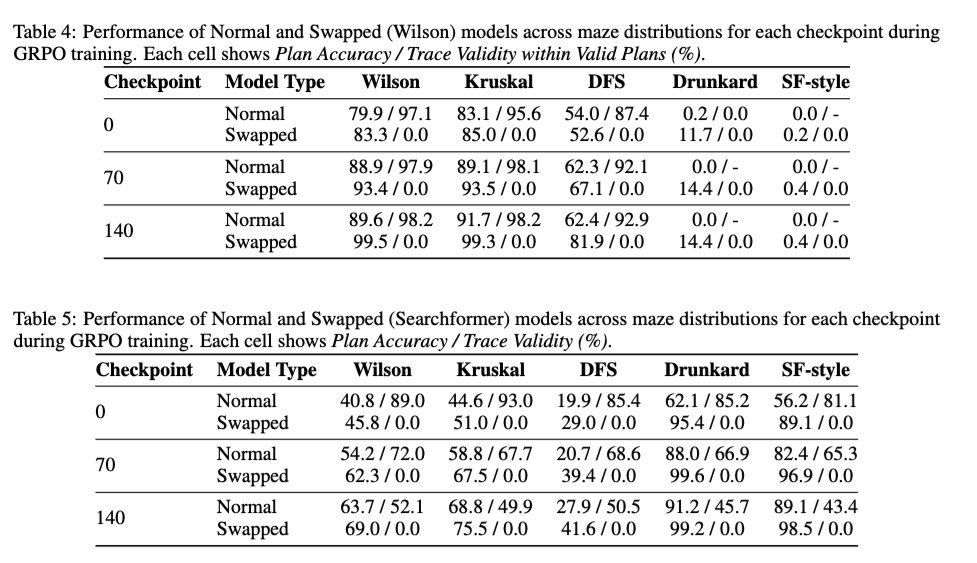
2/ 我们还考察了DeepSeek R1风格的强化学习对轨迹有效性的影响——即强化学习是否能提高基础模型的轨迹有效性。结果表明,强化学习对轨迹有效性基本无影响。即使在模型使用100%交换轨迹训练的情况下,强化学习也能提高求解精度,而不会提高轨迹有效性。
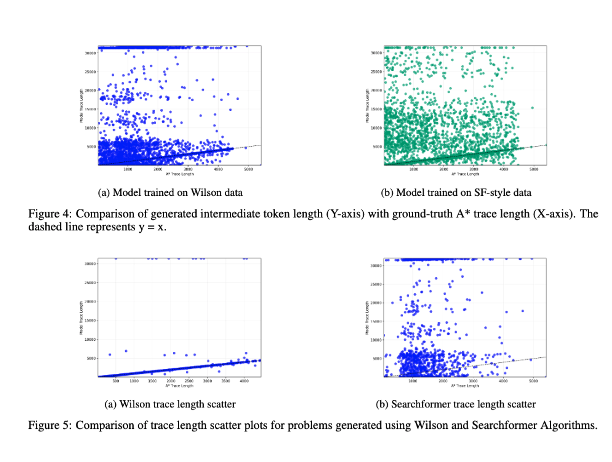
3/ 最后,我们研究了中间词元长度与问题实例的计算复杂度之间的相关性。结果表明,二者之间没有相关性!(我曾在 https://t.co/RL9ZEOKbpQ 中讨论过该实验的早期版本)
4/ 新版本可在 https://t.co/4LGWfiCZ5e 找到arxiv.org/abs/2505.1377592、@kayastechly 和 @PalodVardh12428 在下周的 #NeurIPS2025 研讨会上进行展示,研讨会主题为 LAW、ForLM 和高效推理。欢迎届时莅临交流!