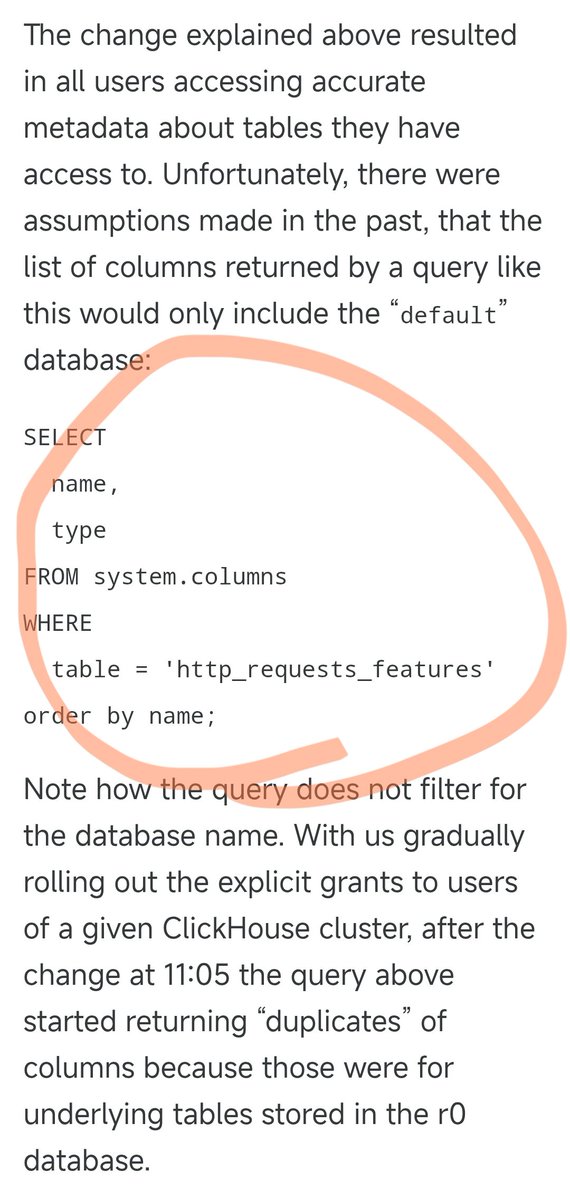
昨晚Cloudflare 的故障就是下面這個SQL 所導致的。 之前,這個SQL 運作好好的,只會查詢default 資料庫的列資訊。 但昨天他們升級了某些用戶權限,就導致這個SQL 會同時返回default 資料庫和底層r0 資料庫的解信息,而他們在調整權限時,完全沒有任何一個人想到了要去相應的修改這個SQL。 於是,查詢結果翻倍了,導致結果文件大小翻倍,原本只有大約60個的文件,變成了大約120個特徵。 這裡就要說到一個關鍵設計了。 Cloudflare的反爬蟲模組為了效能最佳化,預先分配了固定大小的內存,並且硬編碼了一個上限:最多支援200個特徵。 這個限製本來設得挺寬鬆的,畢竟實際上只用60個,留了3倍多的餘裕。 但是,當特徵檔因為重複資料而導致超過200個特徵限制時,問題就來了。 Rust程式碼裡有個檢查,如果特徵數超限就會panic(崩潰),直接回傳500錯誤。 更糟的是,這個特徵檔案每5分鐘自動產生一次,並且會快速推送到全球所有伺服器。由於權限調整是逐步推送到各個資料庫節點的,所以每5分鐘,根據查詢落在哪個節點上,可能產生好文件,也可能產生壞文件。 這就導致了一個非常詭異的現象:系統時好時壞,一會兒恢復正常,一會兒又全面崩潰。這種症狀讓工程師們一度懷疑是不是遭到了DDoS攻擊。 巧合的是,Cloudflare的狀態頁面(託管在第三方,完全獨立於Cloudflare基礎設施)恰好在這個時候也掛了,更加深了"遭受攻擊"的懷疑。 於是就讓他們在定位問題時想錯了方向,浪費了一些時間。 直到權限調整逐步推送到所有節點,每個節點都開始產生壞文件,系統進入了穩定的故障狀態,工程師最終才定位到真正的問題,從而修復了故障。 這次故障,從北京期間11月18日19:28左右開始,到22:30初步恢復,再到19日01:06徹底恢復,總共經歷了差不多5.5個小時,是Cloudflare 自2019年以來的最大故障。