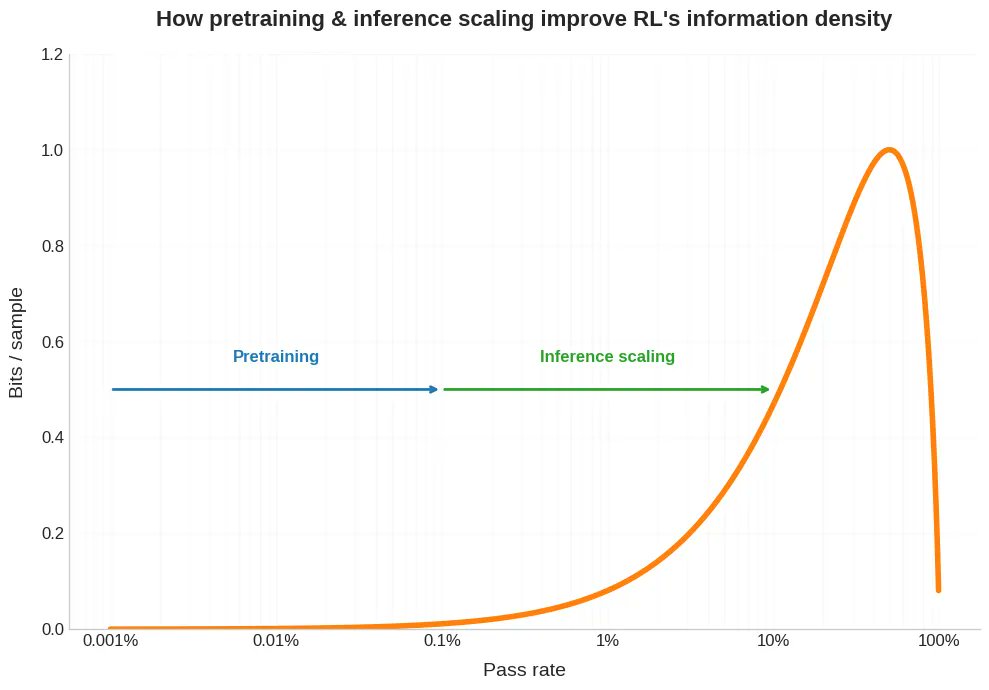
新博文。最近,人们一直在讨论强化学习中获取单个样本所需的计算量远高于预训练。 但这只是麻烦的一半。 在现实生活中,这种昂贵的样本通常只能提供很少的比特位。 这对于 RLVR 的扩展性有重要意义,同时也有助于我们理解为什么自我游戏和课程学习对 RL 如此有帮助,为什么 RLed 模型会呈现出奇怪的锯齿状,以及我们如何思考人类与人类的不同之处。 链接如下。

正在加载线程详情
正在从 X 获取原始推文,整理成清爽的阅读视图。
通常只需几秒钟,请稍候。
共 2 条推文 · 2025年11月17日 17:09
新博文。最近,人们一直在讨论强化学习中获取单个样本所需的计算量远高于预训练。 但这只是麻烦的一半。 在现实生活中,这种昂贵的样本通常只能提供很少的比特位。 这对于 RLVR 的扩展性有重要意义,同时也有助于我们理解为什么自我游戏和课程学习对 RL 如此有帮助,为什么 RLed 模型会呈现出奇怪的锯齿状,以及我们如何思考人类与人类的不同之处。 链接如下。