#1 基于表征的语言模型探索:从测试阶段到训练后阶段 链接 - https://t.co/NSxfgxeTX4 我们使用强化学习来改进模型,但本质上我们只是在强化基础模型已经知道的东西,很少arxiv.org/abs/2510.11686索,推动模型尝试不同的解决方案,而不仅仅是同一个解决方案的更自信的版本。 主要查询: LLM 的内部表征(隐藏状态)能否指导探索? 刻意探索能否让我们超越简单的磨砺?

#2 - 假设你想向你的视频流管理器(VLM)提供无限的视频流,你会如何防止它们崩溃? 链接 - https://t.co/b0KulnGDS1 对所有历史帧的完全关注是二次方的,最终会导致延迟和内存消耗爆炸式增长。几分钟后,上下文arxiv.org/abs/2510.09608动窗口勉强能保持局部完整性,但全局注释功能会变得非常糟糕。他们将 Qwen2.5-VL-Instruct-7B 微调成一个新的模型 StreamingVLM,并配以相应的推理方案和数据集。其核心设计理念是:将训练与流式推理同步,而不是在推理时添加键值对驱逐启发式算法。其设计的关键组成部分包括:流感知键值缓存、连续 RoPE、重叠式全注意力训练策略以及流式专用数据。这是一篇非常棒的论文,值得专门讨论。

#3 - 这是思考还是作弊?通过测量推理努力来检测隐性奖励作弊 链接 - https://t.co/z2RUEQZuOl 模型通常会奖励走捷径的黑客行为。 有时候,作弊手段在思路链(CoT)中显而易见,也就arxiv.org/abs/2510.01367有时候,作弊则是隐性的奖励机制漏洞。思路链看起来合情合理。 该模型实际上走了捷径(例如,使用泄露的答案、漏洞或 RM 偏差),但却用虚假的解释掩盖了这一点。 如果模型作弊,它只需极少的“真正”推理就能获得高额奖励。因此,作者建议,与其阅读并相信模型的解释,不如衡量一下,如果强制模型提前回答,它能多早获得奖励。 他们将这种方法称为 TRACE(截断推理 AUC 评估)。

#4 - 量化增强的LLM强化学习 链接 - https://t.co/yGkbqg1kVk 代码 - https://t.co/varxiv.org/abs/2510.11696该如何在强化学习github.com/NVlabs/QeRL什么应该使用量化”。 QERL 使用 NVFP4 4 位量化,令人惊讶的是,它通过利用量化噪声来增强探索能力。如图 4 和图 5 中的熵曲线所示,这种噪声使模型的输出分布趋于平坦并提高了熵。 为了使这种噪声在整个训练过程中有用,作者添加了自适应量化噪声,即通过 RMSNorm 注入的高斯扰动(图 6)。 这样既能达到全精度级别的推理质量,又能使用约 25-30% 的内存,并且能将 RL 迭代速度提高 1.2-2 倍,甚至允许在单个 H100 上训练 32B 模型。 结果似乎与全参数强化学习相符。 值得深入研究。

#5 - 如何计算您的 MFU? 链接 - https://t.co/Ve9Cgithub.com/karpathy/nanoc…r 在 nanochat 上进行了一场精彩的讨论

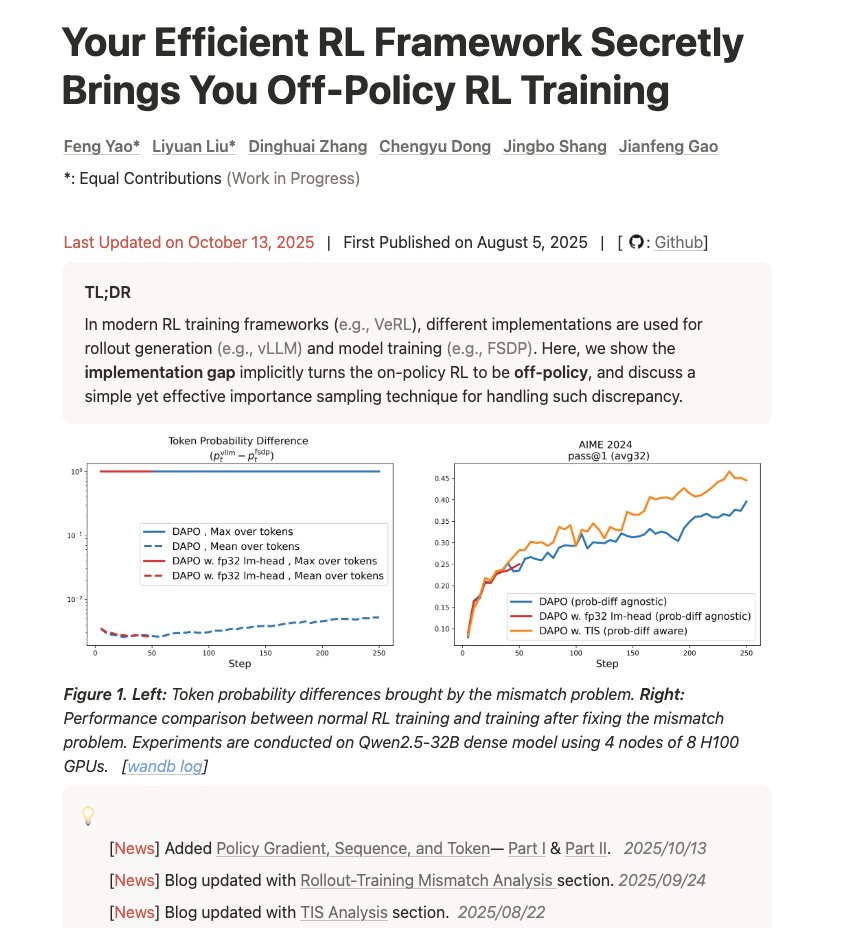
#6 - 你高效的强化学习框架悄悄地为你带来了离策略强化学习训练 链接 - https://t.co/d2Loq5UwZQ 这篇博客写得很好,深入浅出地讲解了训练与推理不匹配以及它如何影响结果。 fengyao.notion.site/off-policy-rl#…题有多严重,以及如何使用重要性抽样来修复它。”