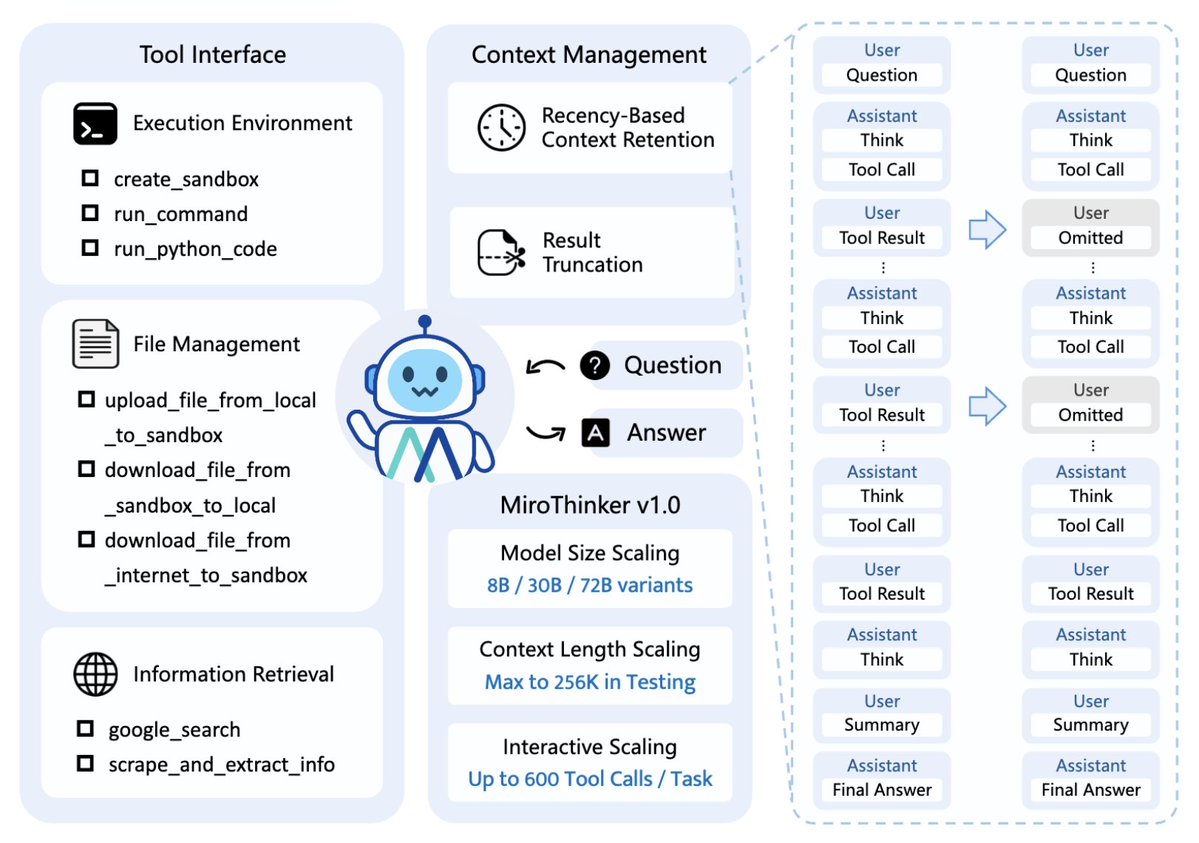
MiroMind 團隊推出了一款全新的開源bAgent 模型:MiroThinker v1.0 它的最大創新是提出了一個新概念:“深度互動Scaling(Interactive Scaling)” 突破Scaling Law 瓶頸,讓AI 自我進化 這個概念突破了傳統「模型規模越大→效能越好」的線性成長規律,轉而強調「模型與環境互動的深度與頻次」 才是智慧成長的關鍵因素。 - MiroThinker 支援與外部工具(如搜尋引擎、Linux 沙箱、語音辨識等)進行多次互動和推理,能夠靈活使用工具來獲取資訊、完成任務。 - 256K 上下文:能記得非常多的資訊(幾十萬字)。 - 單次可執行600 次工具呼叫:AI 能持續使用搜尋、程式碼執行、計算、翻譯等外部工具。 - 能進行複雜推理與長時間任務:不是簡單回答問題,而是能分步驟思考、查資料、比較方案。 什麼是「深度互動Scaling」? 表現∝ 模型與環境的互動深度× 反思頻率 換句話說就是: - 模型不是被動吸收知識,而是主動與環境互動; - 每次試誤與反思都會讓模型在策略空間中「自我進化」; - AI 越「動手做」:越能糾正錯誤、提升推理品質。 就像人類透過「反覆試錯、動手實踐」才能真正學會複雜的事情。 🧩 舉例說明: 就像人類學習烹飪,單看食譜是遠遠不夠的,必須親自嘗試、失敗、修正、再嘗試。 對AI 而言,多輪環境互動+ 回饋修正= 智慧進化的真正燃料。每次互動都是一次“學習”,智能就會越來越強。 因此,MiroThinker 將「上下文長度」和「交互輪數」都提升至極限,形成真正的「深度思考循環(Thinking Loop)」。
多個國際評測中 成績接近甚至超過GPT-5 高級版: 在複雜網頁理解測試(BrowseComp)中得分47.1%,逼近OpenAI 的DeepResearch (51.5%)。 在人類終極推理測驗(HLE)中,超過GPT-5-high。 在中文任務上超越DeepSeek-v3.2 約7.7 個百分點。

完全開源與可重複性 MiroThinker v1.0 的所有核心資源全部開源,包括: - 模型權重 - 推理與互動框架 - 訓練與強化學習基礎設施 - 評測資料集 - 完整技術報告 詳細介紹xiaohu.ai/c/a066c4/mirot…d GitHugithub.com/MiroMindAI/Mir…by