为什么我们接受使用前向 KL 分布(左图)从数据/模型中近似分布? 为什么不努力开发出类似(右图)的算法呢?
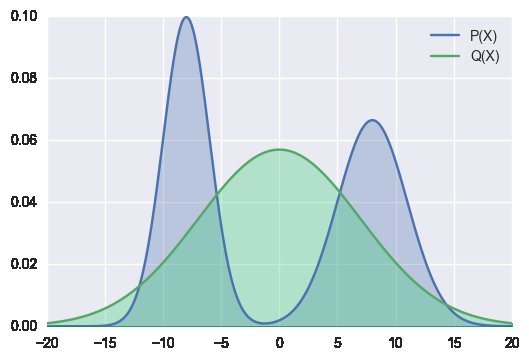

或者,我们是否已经这样做了,因为我们通过增加近期偏差而不是整个分布来最小化 KL 效应?
正在加载线程详情
正在从 X 获取原始推文,整理成清爽的阅读视图。
通常只需几秒钟,请稍候。
共 2 条推文 · 2025年11月2日 07:14
为什么我们接受使用前向 KL 分布(左图)从数据/模型中近似分布? 为什么不努力开发出类似(右图)的算法呢?
或者,我们是否已经这样做了,因为我们通过增加近期偏差而不是整个分布来最小化 KL 效应?