🚨DeepSeek 刚刚做了一些疯狂的事情。 他们建立了一个 OCR 系统,将长文本压缩成视觉标记,将段落转换成像素。 他们的模型 DeepSeek-OCR 在 10 倍压缩下解码精度可达 97%,即使在 20 倍压缩下也能保持 60% 的准确率。这意味着一张图像仅需 LLM 所需 token 的一小部分即可表示整篇文档。 更疯狂?它击败了 GOT-OCR2.0 和 MinerU2.0,同时使用的令牌减少了 60 倍,并且单个 A100 处理器每天可以处理 20 万页以上的数据。 这可以解决人工智能最大的问题之一:长上下文效率低下。 模型可能很快就不会再为更长的序列支付更多费用,而是看到文本而不是阅读文本。 上下文压缩的未来可能根本不是文本的。 可能是光学的👁️ github。 com/deepseek-ai/DeepSeek-OCR
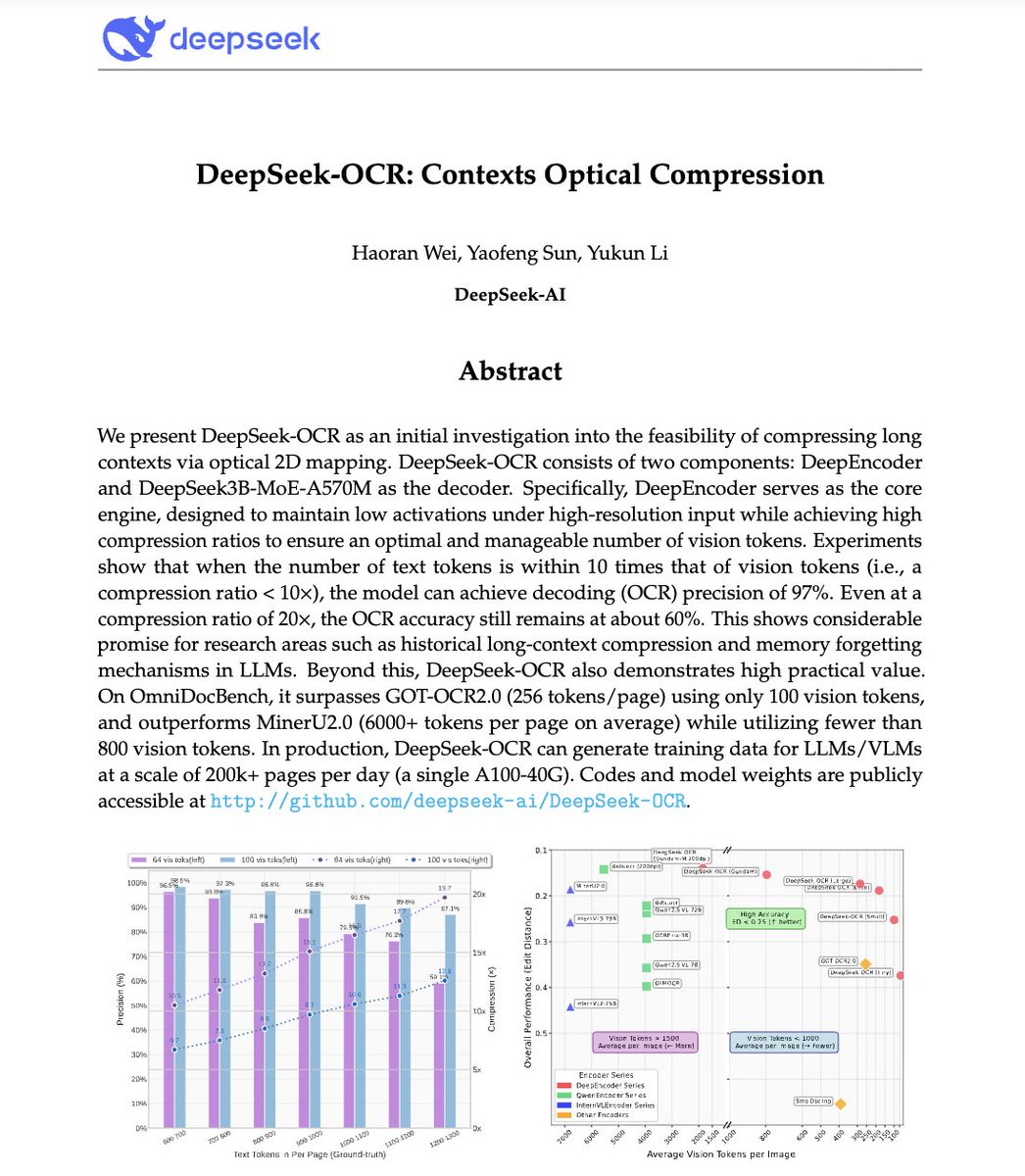
1. 视觉文本压缩:核心思想 LLM 难以处理长文档,因为标记的使用量与长度呈二次方关系。 DeepSeek-OCR 则相反:它不是读取文本,而是将完整文档编码为视觉标记,每个标记代表一段压缩的视觉信息。 结果:您可以将 10 页的文本放入与在 GPT-4 中处理 1 页所需的相同令牌预算中。

2. DeepEncoder - 光学压缩器 认识明星:DeepEncoder。 它使用两个主干网络 SAM(用于感知)和 CLIP(用于全局视觉),由 16×卷积压缩器连接。 这使得它能够保持高分辨率的理解,而不会爆炸激活记忆。 编码器将数千个图像块转换为几百个紧凑视觉标记。

3. 多分辨率“高达”模式 文件各不相同,发票≠蓝图≠报纸。 为了解决这个问题,DeepSeek-OCR 支持多种分辨率模式:Tiny、Small、Base、Large 和 Gundam。 高达模式有效地结合了局部图块 + 全局视图,从 512×512 缩放到 1280×1280。 一个模型,多种分辨率,无需重新训练。

4. 数据引擎OCR 1.0到2.0 他们不仅仅进行文本扫描训练。 DeepSeek-OCR 的数据包括: • 100 种语言的 3000 多万个 PDF 页面 • 1000 万自然场景 OCR 样本 • 1000 万张图表 + 500 万个化学公式 + 100 万个几何问题 它不仅仅是阅读,它还可以解析科学图表、方程式和布局。

5. 这不仅仅是“另一个 OCR”。 这是上下文压缩的概念证明。 如果文本可以用少 10 倍的标记进行视觉表示,那么 LLM 可以使用相同的想法进行长期记忆和有效推理。 想象一下 GPT-5 将 1M 个标记的文档处理为 100K 个标记的图像映射。

不要再浪费时间写提示 → 10,000+ 个随时可用的提示 → 几秒钟内即可创建您自己的 → 终身访问。一次性付款。 领取您的副本👇