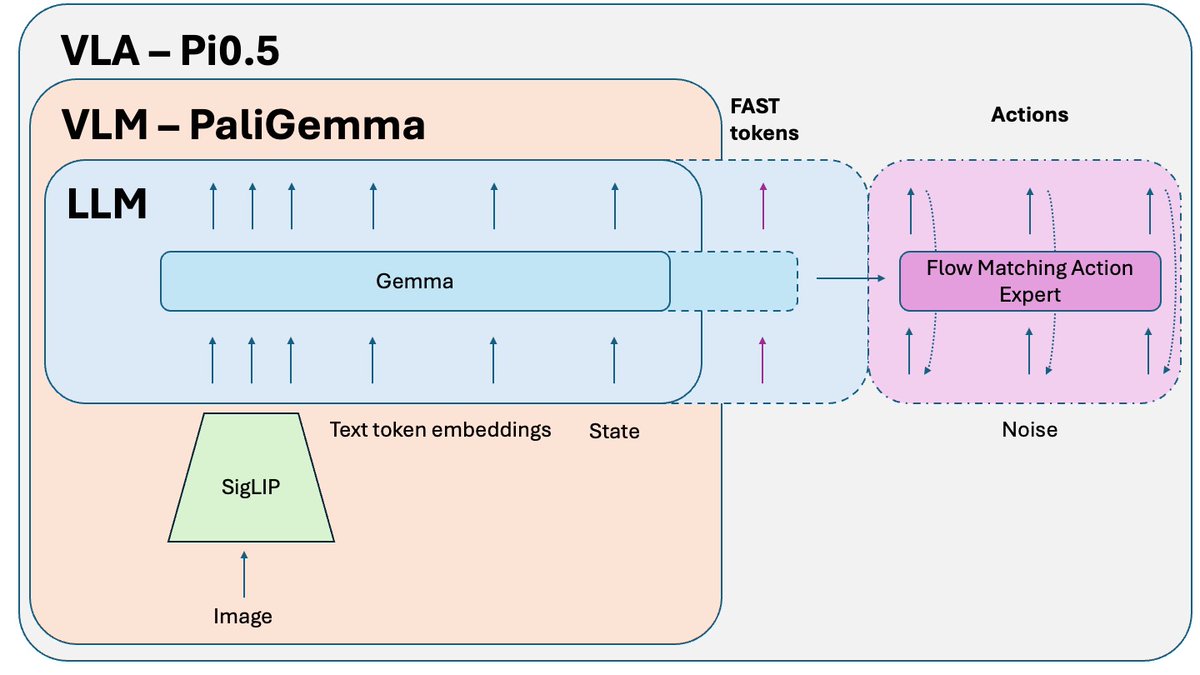
@physical_int 的 Pi0.5 是目前最好的開源端對端機器人策略之一🤖 它是 Pi0 的升級版,最新的 Pi 技術都是基於它開發的。讓我們來探討一下它的運作原理:
與 Pi0 相比,有哪些變化? - FAST 分詞 - Pi0 上有一個可選的 FAST 版本,但對於 Pi0.5 來說,它是訓練過程中必不可少的一部分。 - 系統 2 - 根據 Hi Robot 論文,Pi 0.5 使用其 VLM 部分作為推理高級系統 2,用於推理和規劃複雜任務。 - 更完善的訓練方案和一些小的調整。
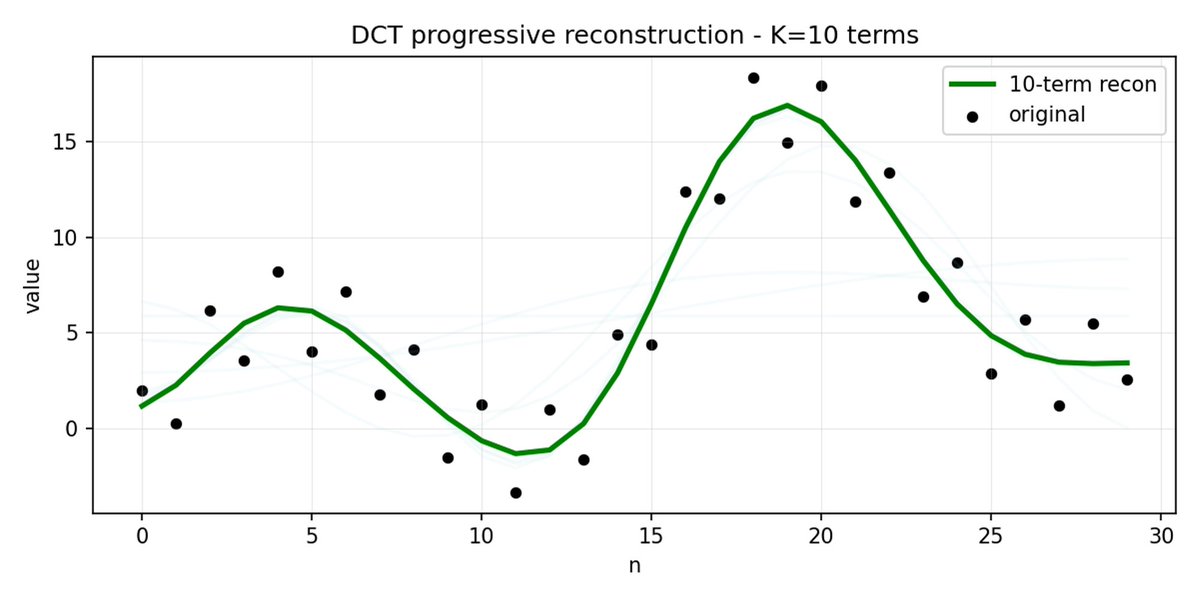
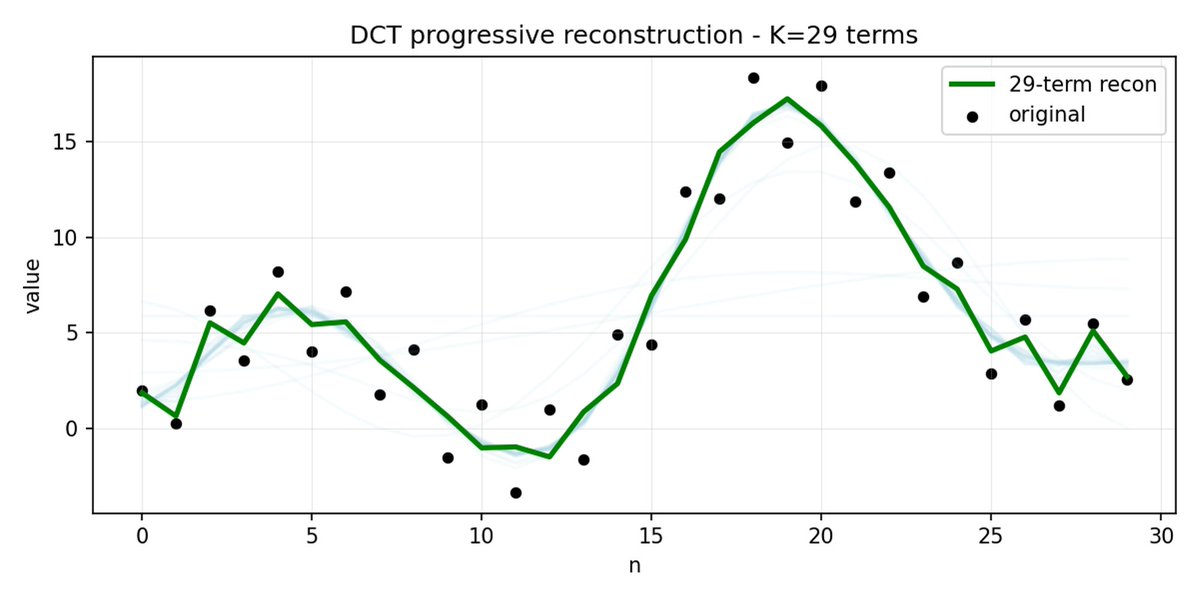
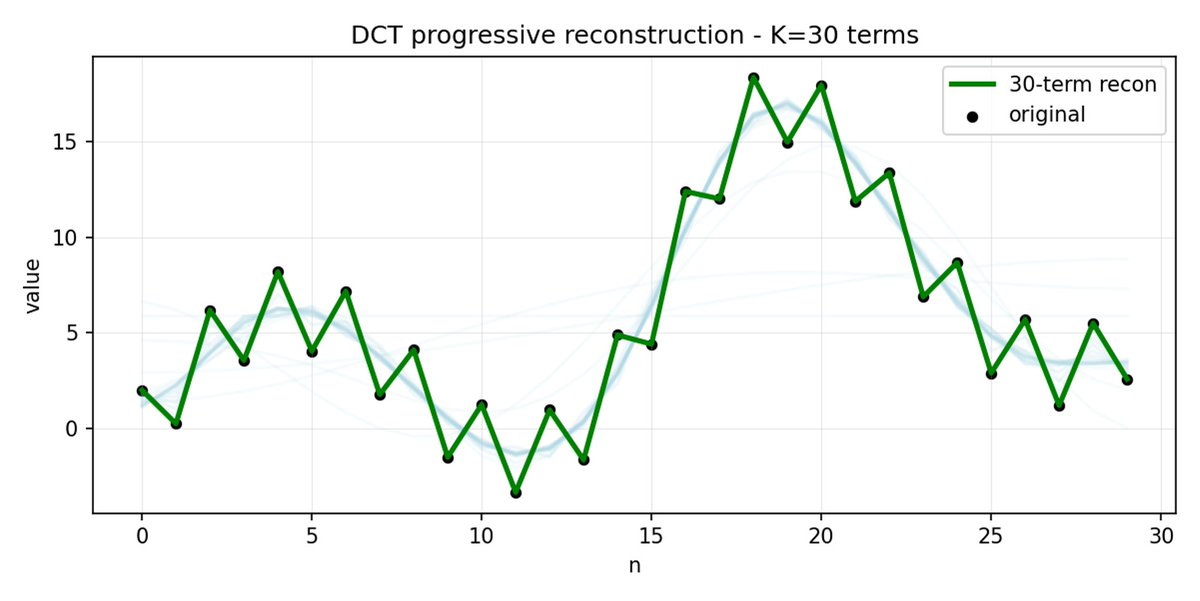
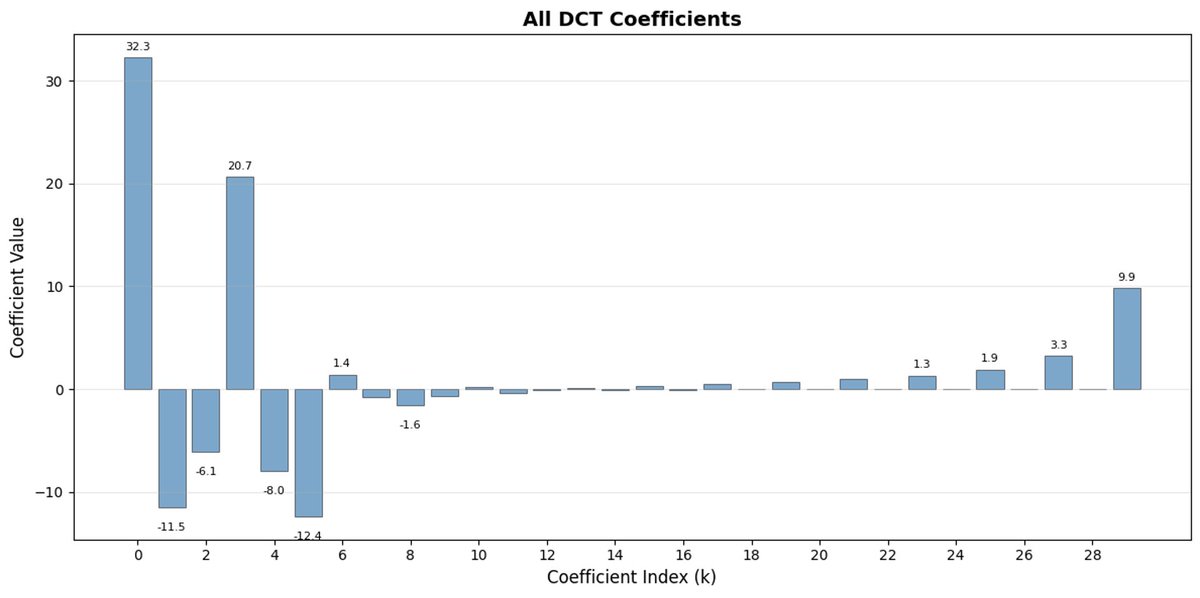
FAST 是一種分詞方法,它使用 DCT(離散餘弦變換)和 BPE(位元組對編碼)將動作序列壓縮成訊息非常密集的離散標記。 DCT 是 JPEG 影像壓縮中使用的同一種演算法。 它將訊號表示為不同頻率的餘弦函數總和。前幾個分量捕捉訊號的整體趨勢和形狀,其餘分量則捕捉越來越多的細節。 漸進式 JPEG 首先發送低頻分量,影像看起來模糊,然後隨著分量的增加而逐漸清晰。



FAST 對動作方塊也執行相同的操作。 與其預測 30 個相關的行動值,不如預測一個更短、更有意義的表示。 通常情況下,你只需要保留幾個主要係數(其中包含原始訊號的大部分能量),仍然可以很好地重建軌跡。
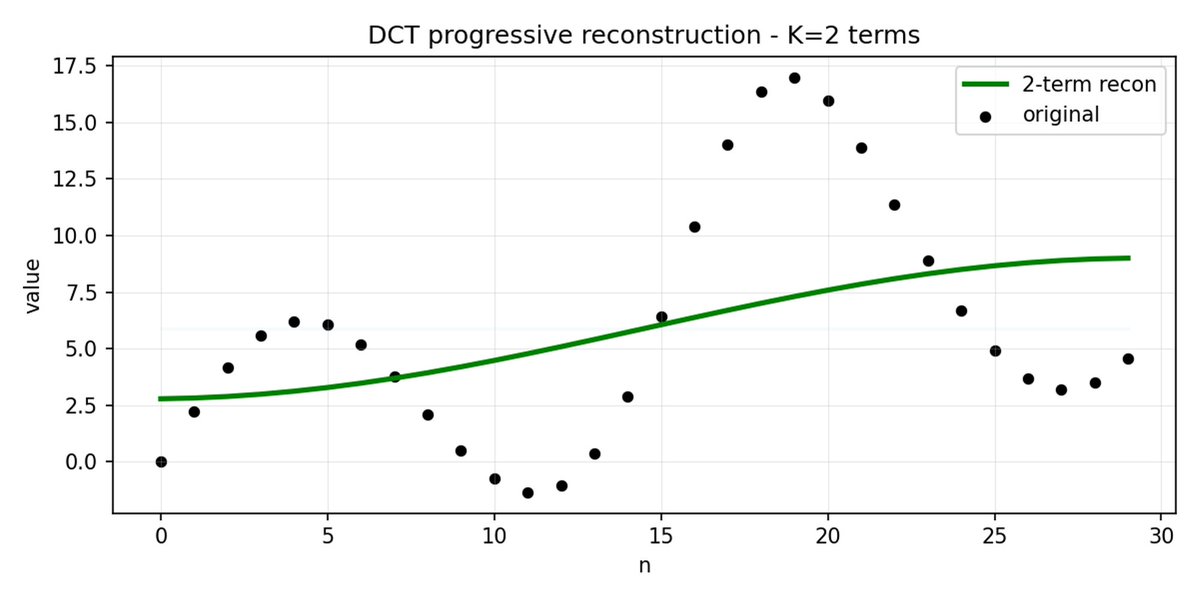
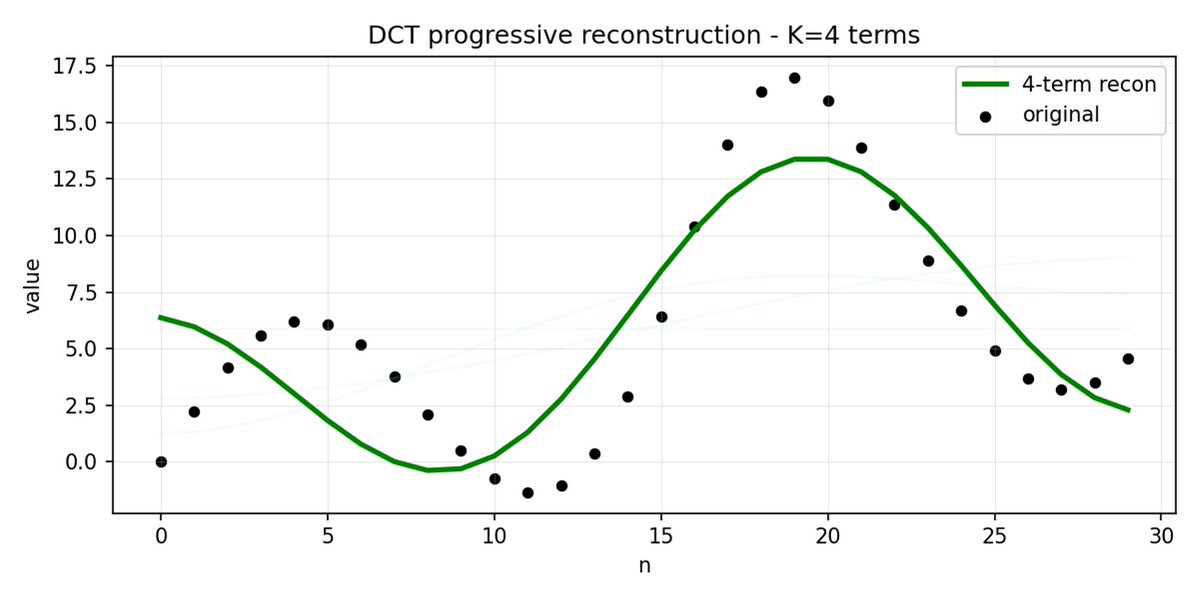
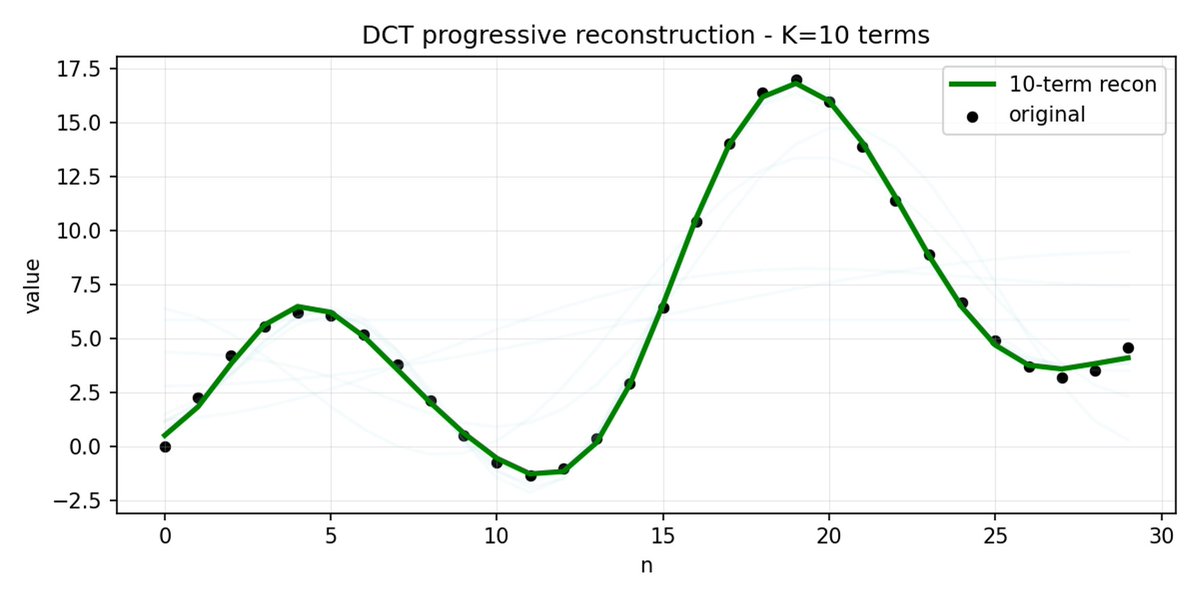
位元組對編碼 (BPE) 是 LLM 中最常用的分詞方法。 它會尋找最常見的單字對,並將它們合併成單字。 當應用於量化 DCT 時,許多高頻成分的 0 係數以及不同關節的常見組合運動被合併到單一標記中,導致強壓縮。
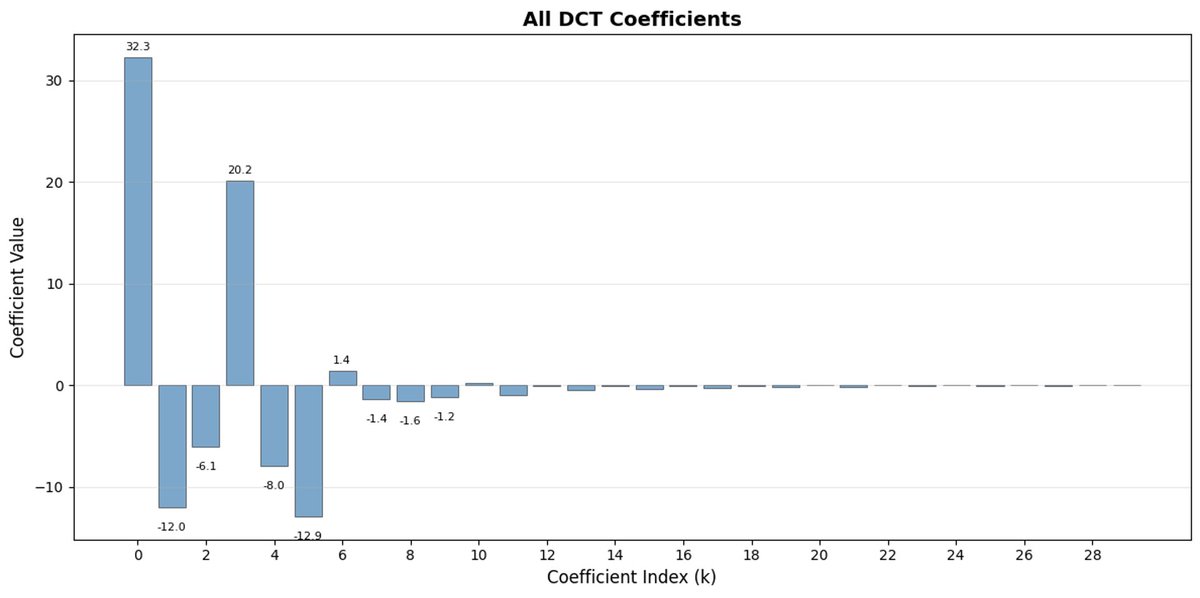
如果您的動作存在高頻雜訊(例如每個時間步的歸一化偽影),FAST 的壓縮效果可能會很差,係數不再接近零,壓縮效果也會下降。 真實機器人數據通常是平滑的,所以大多數情況下都沒問題——只需注意數據預處理即可。
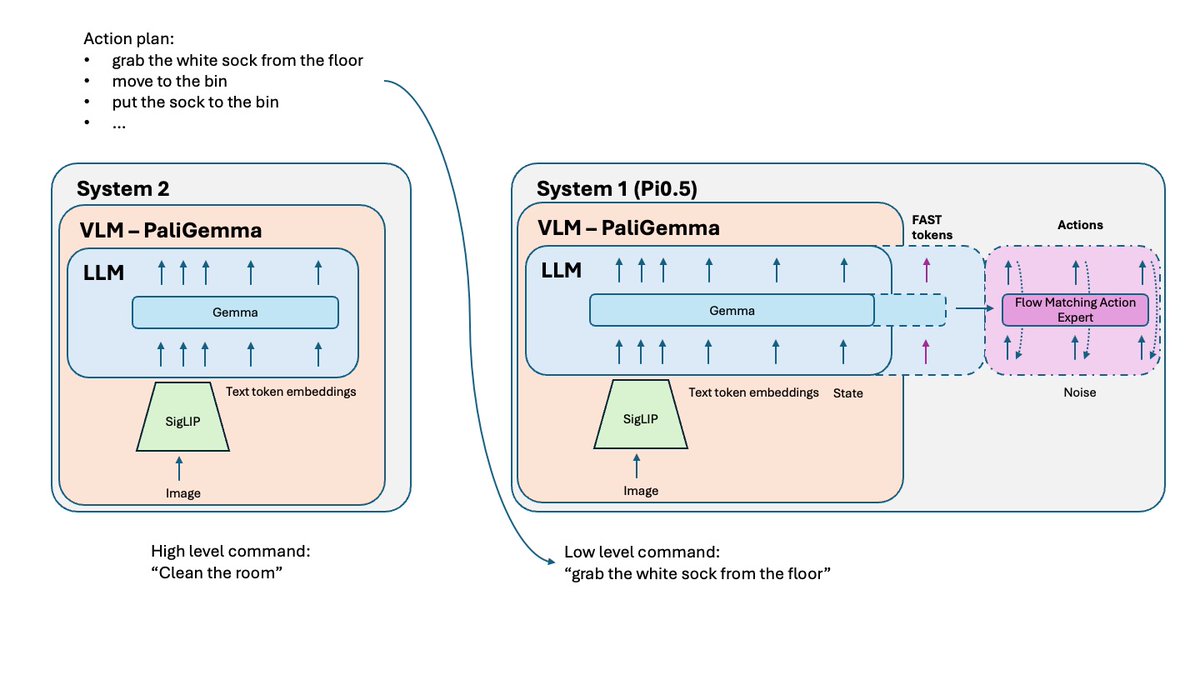
基於簡單任務訓練的 VLA 策略,在將這些任務組合成複雜的、長期的問題時可能會遇到困難。 為了解決這個問題,需要用到更高等級的系統 2。 Pi0.5 使用與系統 1 (VLA) 相同的 VLM,但呼叫頻率要低得多,用於推理問題並定義下一步操作。之後,該指令會被傳送給系統 1 執行。
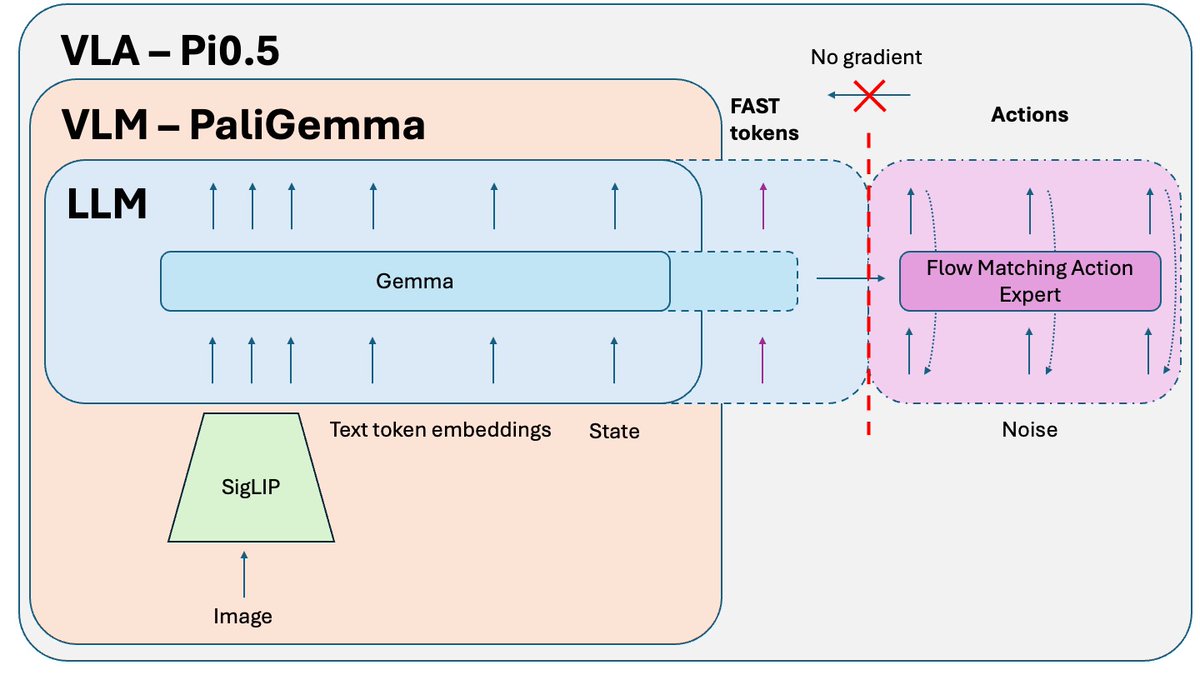
在 Pi0.5 論文之後發布的一個額外技巧,用於訓練該模型的開源版本,是知識隔離。 當您共同訓練 VLM 部分(已在網路規模資料上預先訓練)和動作專家(隨機初始化)時,來自動作專家的雜訊梯度會破壞 VLM 的預訓練結果。它會逐漸遺忘其預先訓練的知識。 解決方法是將梯度與動作專家隔離,並允許它僅影響動作專家權重,同時在 FAST 動作標記 + 相關非動作資料上訓練 VLM。
推理過程中的另一個問題是,由於分塊處理,運動不平滑。 模型預測下一個資料區塊,執行它,然後暫停以預測下一個資料區塊(如下視頻,3 倍速)。 如果在前一個程式碼區塊執行之前嘗試預測下一個程式碼區塊,而模型在執行一個截然不同的操作模式時跳到另一個操作模式,則可能會導致致命的錯誤。 解決方案是圖像修復——這通常用於圖像生成。我們可以在執行上一個資料區塊的同時預測下一個資料區塊,但我們會強制新的預測與前一個資料區塊的結尾完全匹配。 結果是運動更加流暢,沒有跳躍和停頓,並且模型的性能和吞吐量更高。
如果你想深入了解(包括圖片、演示和微調說明),請觀看我的新影片:https://t.co/TDdhedJiDn