Google發布全新的Gemini 2.5 Flash Native Audio 模型 用於驅動各種即時語音應用 「Native Audio」 指的是模型能直接產生自然語音輸出,而不是先生成文字再用語音合成。 它不僅“懂你說的內容”,還“能立刻用人類語音回答”,語調、節奏、停頓都更自然。 三大核心能力全面增強: 1️⃣ 更聰明的“函數呼叫” Gemini 現在能在語音對話中主動呼叫外部資訊來源,例如: 呼叫天氣API; 查詢資料庫; 取得即時新聞或股票資訊。 它不只是“回答”,而是能在“對話過程中”判斷什麼時候要查資料、什麼時候要繼續對話,並且能“邊查邊說”,保持語音流暢。
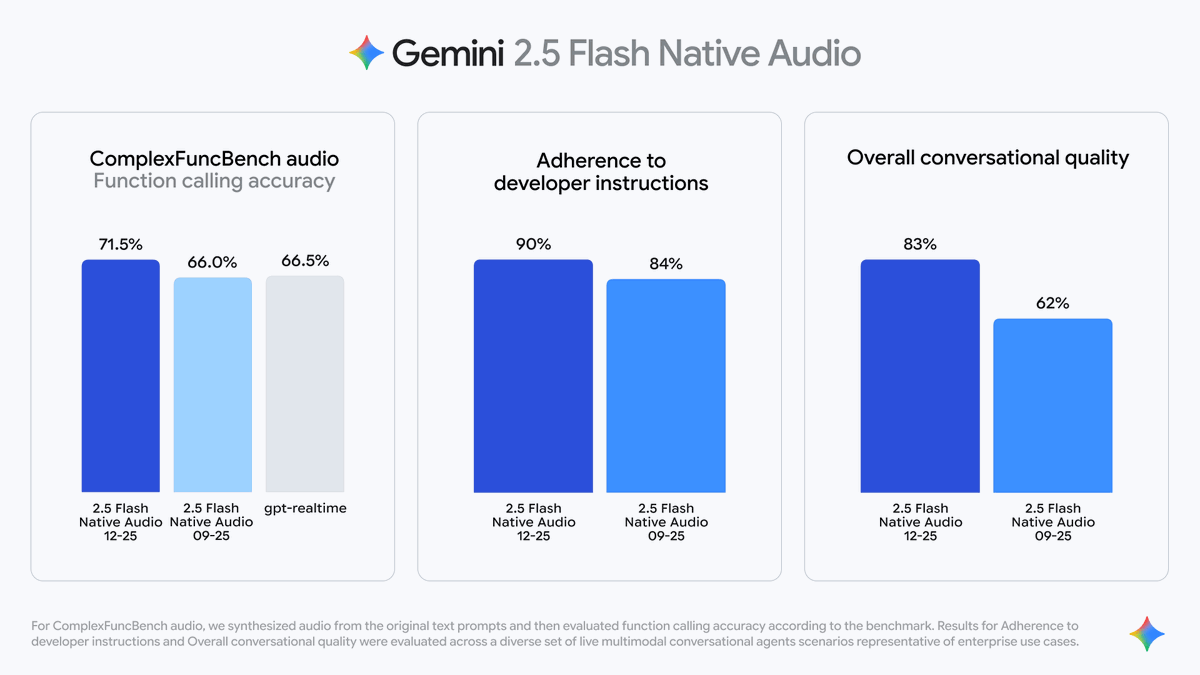
2️⃣ 更強的指令理解 Gemini 2.5 Flash Native Audio 在理解複雜口頭指令方面更精準。 Google 測試數據顯示: 指令遵從率從84% 提升到90%; 輸出內容的完整性與準確性顯著提高。 3️⃣ 對話流暢度升級 Gemini 2.5 Flash Native Audio 能記住多輪對話上下文,語音銜接更自然。
Gemini 2.5 Flash Native Audio 模型現已在Vertex AI 上全面開放,同時也可在Gemini API(預覽版) 中使用。 詳細內容:https://t.co/CnBlan3RBh