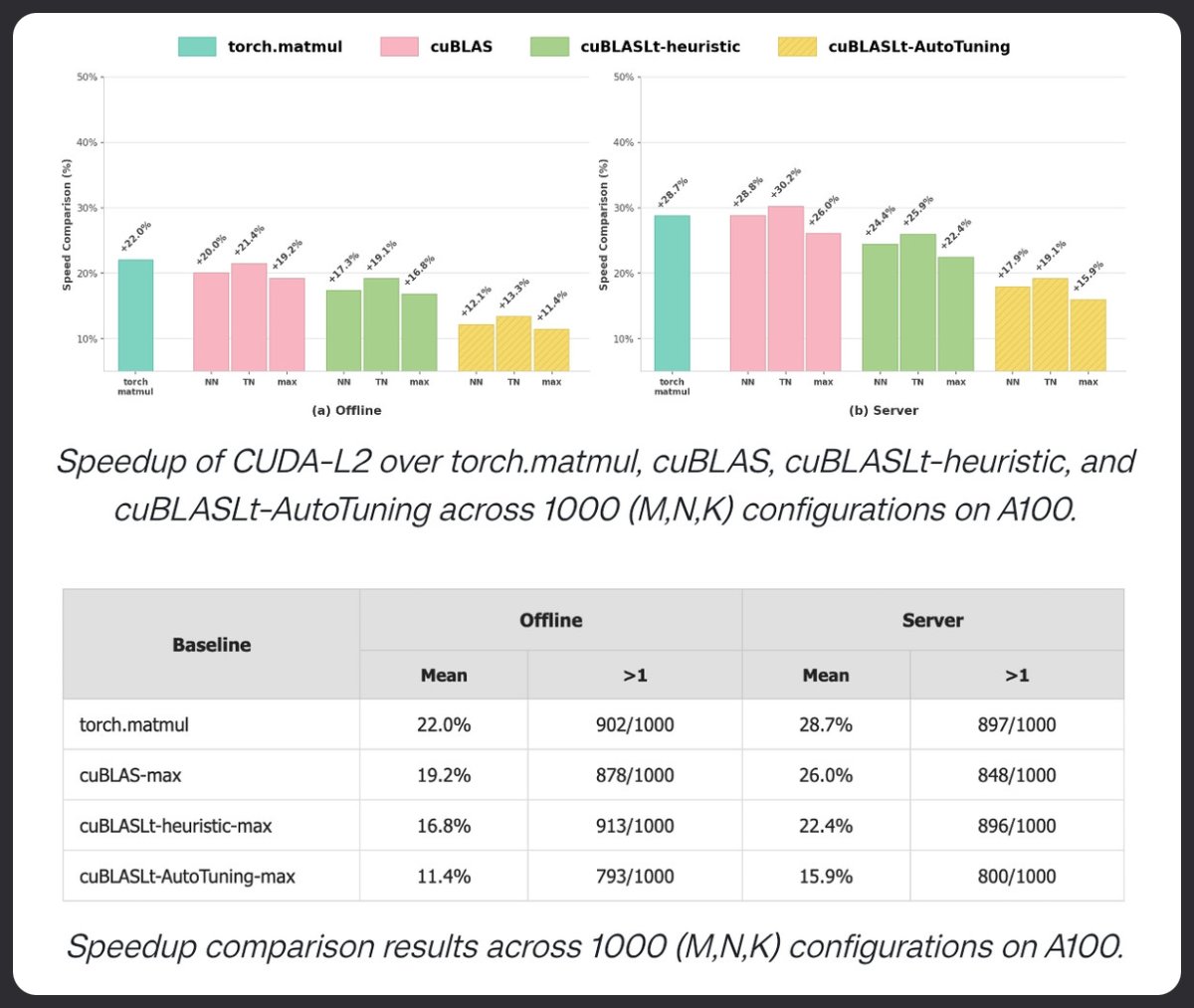
CUDA-L2 使用強化學習在矩陣乘法方面優於 cuBLAS。 經過 1000 個 HGEMM 配置的測試,它在 A100 上優於 torch.matmul、cuBLAS 和 cuBLASLt AutoTuning。 離線模式下效能提升 22%。 伺服器模式下成長 28.7%。 LLM 目前正在調整核心。
📄論文連結:htarxiv.org/pdf/2512.02551🔗 GitHub:https://t.co/xijapZLAgY
正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 2 則推文 · 2025年12月12日 下午6:00
CUDA-L2 使用強化學習在矩陣乘法方面優於 cuBLAS。 經過 1000 個 HGEMM 配置的測試,它在 A100 上優於 torch.matmul、cuBLAS 和 cuBLASLt AutoTuning。 離線模式下效能提升 22%。 伺服器模式下成長 28.7%。 LLM 目前正在調整核心。
📄論文連結:htarxiv.org/pdf/2512.02551🔗 GitHub:https://t.co/xijapZLAgY