讓我用最簡潔的方式來闡述。我認為很多人對這個論點的某種解讀存在於極端。但我認為還有很多其他版本的論點本質上是正確的。
「生成知識」是什麼意思?比如說,產生關於一個真但未知的命題 P 的知識?我認為這意味著存在一個上下文命題 C,它能從邏輯邏輯模型 (LLM) 引出一個「論證」 A,該論證為真並蘊含命題 P。如果能做到這一點,那麼它就產生了關於命題 P 的知識。
所以,引用的論點中最明顯錯誤的版本是「這不可能發生」。它顯然會發生,而且經常發生,大多是以一些微不足道的方式。我的應用程式中實作某個功能的程式碼未知。我向LLM(語言學習模組)詢問。它生成了程式碼。瞧,新知識到手了。
既然如此,那就讓我們開始深入探討。首先,最基本的一點是,LLM(法學碩士)所「知道」的任何東西在短期內都是靜態的。它會在每次學習之間忘記所有內容。一旦它推導出A,它並不會自動「知道」P。這似乎與人類略有不同。
一旦歐幾裡得證明了 I.46:你可以構造一個正方形,I.46 就成為他知識的一部分,他可以用它來證明勾股定理。而 LLM 證明了 P 之後,P 並不會以同樣的方式成為它「知識的一部分」。
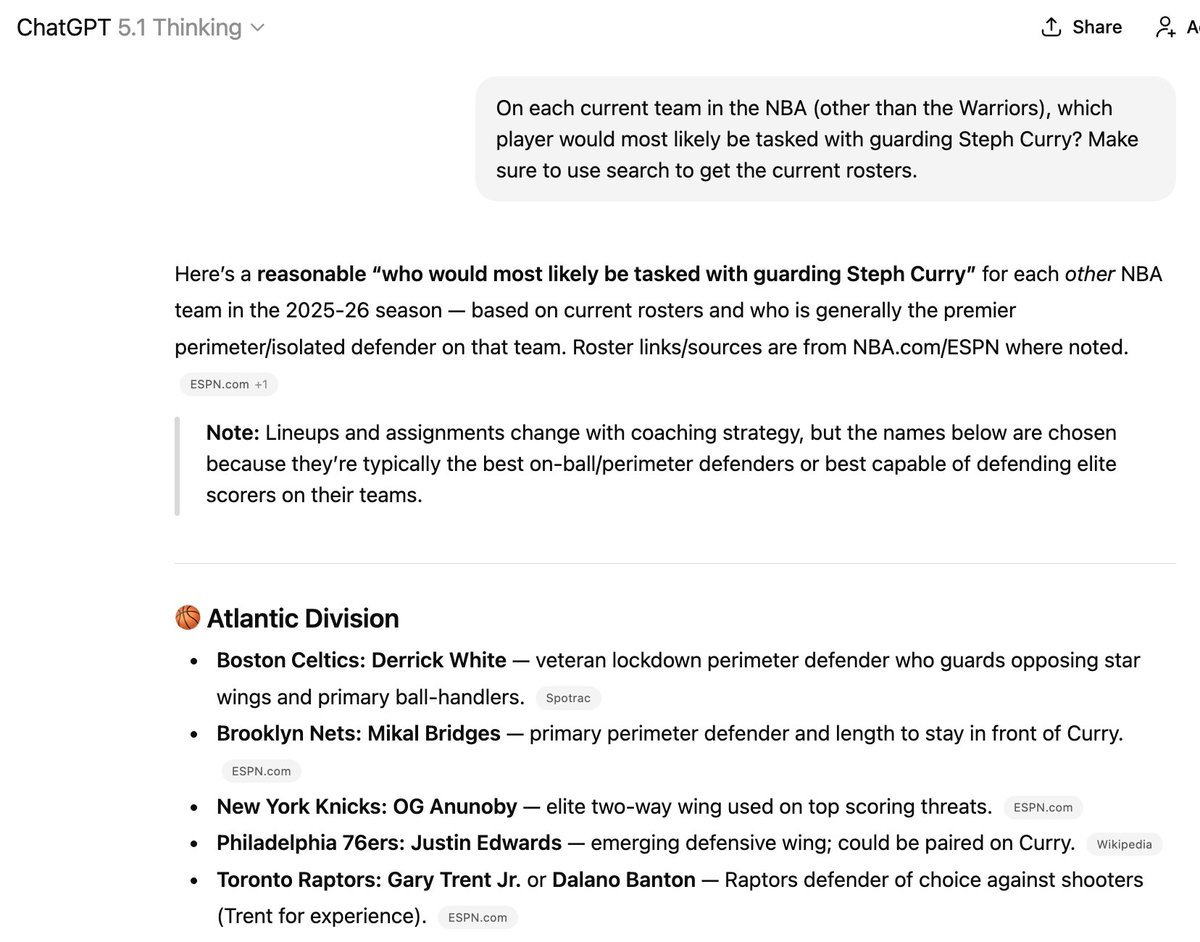
雖然有一些方法可以嘗試將 P 的資料添加到它的訓練資料中,但這仍然相當不可靠。這就是為什麼會出現這種情況。這裡提到的六名球員中有三名已經不在列出的球隊中,但要讓它「知道」新資訊卻很難!
(順便說一句,我並不建議聘請這玩意兒來執教你的NBA球隊)

這一點與「它只能混合已經找到的資訊…」的說法相符。它知道自己知道什麼。這在短期內(即兩次訓練之間)基本上是靜態的,但在長期內會以不可預測的方式演變。
我認為這一點對於聲稱能夠治癒癌症等等的說法至關重要。治癒癌症並非像解決普特南難題那麼簡單。它需要不斷追蹤和連結目前未知的新事實,這些事實甚至可能與現有的認知相違背。
在某些方面,我認為這類似於追蹤哪個球員目前在哪個籃球隊,這項任務即使是擁有無限網路存取權限的博士級推理模型至今也無能為力。
好的,我們再來探討一下鋼鐵人式的另一種想法。 LLM 並非確定性地產生 A,而是以一定的機率生成 A。它也可能以另一個機率產生 B(因為存在“糟糕的論證”),這意味著 ~P。而我們其實並不知道這些機率是多少。
我該如何理解這一切?在它得出正確答案的那個例子中,它是否「創造了知識」?而在這裡,它只是將各種數學資訊片段混合、搭配和重組,這與我引用的那條推文所描述的方式非常相似,而我正在對此進行分析。


透過多種方式,包括一些手動操作和一些自動化操作,我可以驗證這些論點是否正確及其結論是否屬實。在此過程中,我可能會發現一些以前未知的正確論證及其正確結論。
但在我看來,這與其說是一個自主的知識「生成」過程,不如說是一個知識「提取」過程。 LLM包含許多真理和謬誤。挑戰在於提取真理,剔除謬誤。
與許多其他LLM愛好者不同,我認為,將自動補全和隨機猜測下一個詞項等功能美化,實際上是思考這些問題的最正確、最有用的方式。我這麼說是因為我長期以來都是LLM的忠實擁躉。我認為很多人會反對這種描述。
我們永遠無法透過隨機猜測下一個元素來學習新知識。但事實並非如此!如果你把一堆長度相同的針丟在硬木地板上,你可以數出交叉點的數量來估算π的值。這裡面蘊含著大量的資訊。
如果你知道方法,隨機過程就是答案。但我很好奇裡面究竟有多少東西。也許癌症的解藥就藏在某個地方,你只需要給出正確的提示。或者,也許裡面只有幾個未解開的埃爾德什難題和其他一些唾手可得的答案,僅此而已。