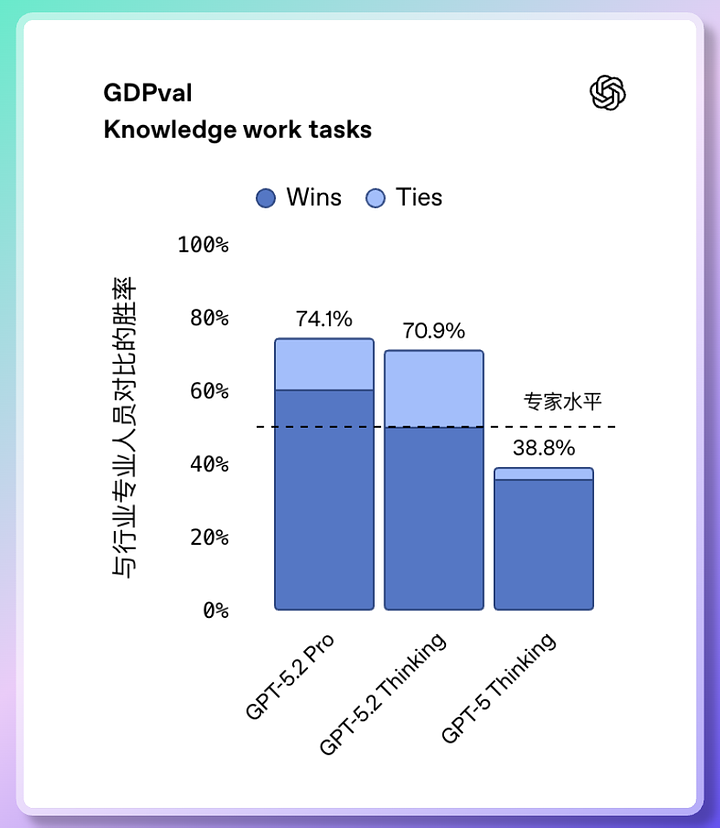
GPT-5.2 模型全解析:專為打工人最佳化 辦公室能力增強 成人模式明年上線 在官方介紹中,OpenAI 稱GPT-5.2: “為知識型工作(Knowledge Work)打造。” 在GDPval 測驗(涵蓋44 個專業職業任務)中, GPT-5.2 Thinking 的得分高達70.9%, 意味著它在多數知識型工作上已經能和行業專家媲美。 它能做什麼? ✅ 製作完整的財務模型 ✅ 設計結構清晰的商業PPT ✅ 撰寫分析報告與投資建議 ✅ 分析數十頁複雜資料文檔 速度方面: 它完成任務的速度比人類專家快11 倍, 成本卻只有1%。 💡 官方數據顯示: ChatGPT 企業用戶平均每天節省40–60分鐘 而重度使用者每周可節省10小時以上。
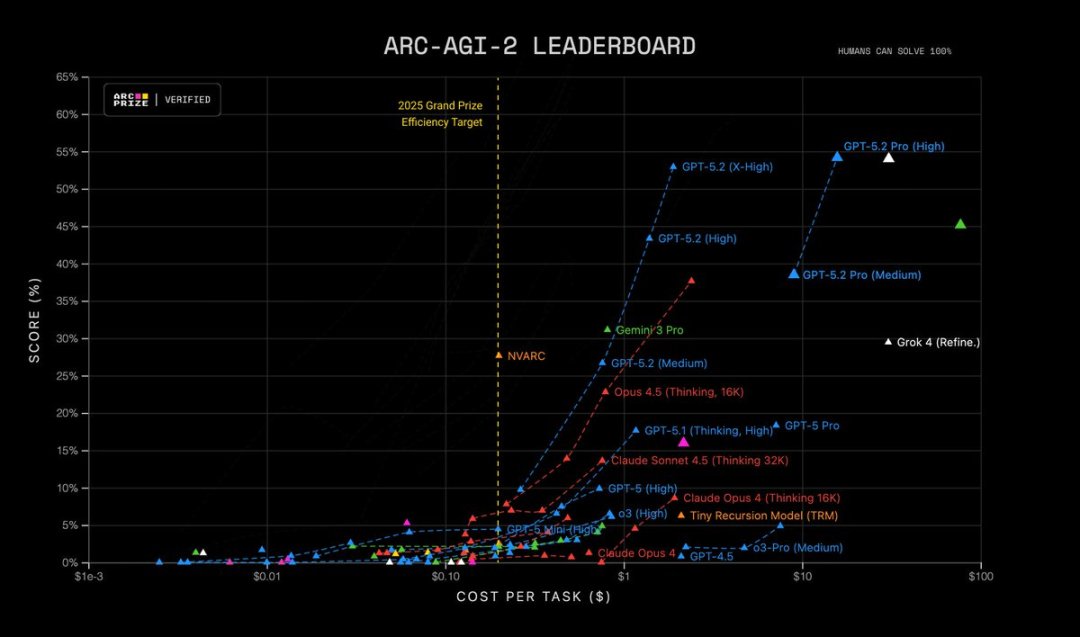
1️⃣ 推理:更強的多步驟邏輯與數學能力 GPT-5.2 Thinking 在多個科學與數學高難度推理評測中創紀錄: GPQA Diamond 科學問答測驗:92.4%(Pro 版93.2%); ARC-AGI-1 抽象推理:86.2%(首次突破90% 門檻的模型) ARC-AGI-2 高階推理:52.9%,刷新思考鏈模型記錄 FrontierMath 高等數學評測:40.3%,遠超過前代; HMMT 數學競賽題:99.4% AIME 數學評量:100% 全解

GPT-5.2 Pro (High) 在ARC-AGI-2 上處於SOTA 水平,以每任務$15.72 的成本獲得54.2% 的得分!超越所有模型。
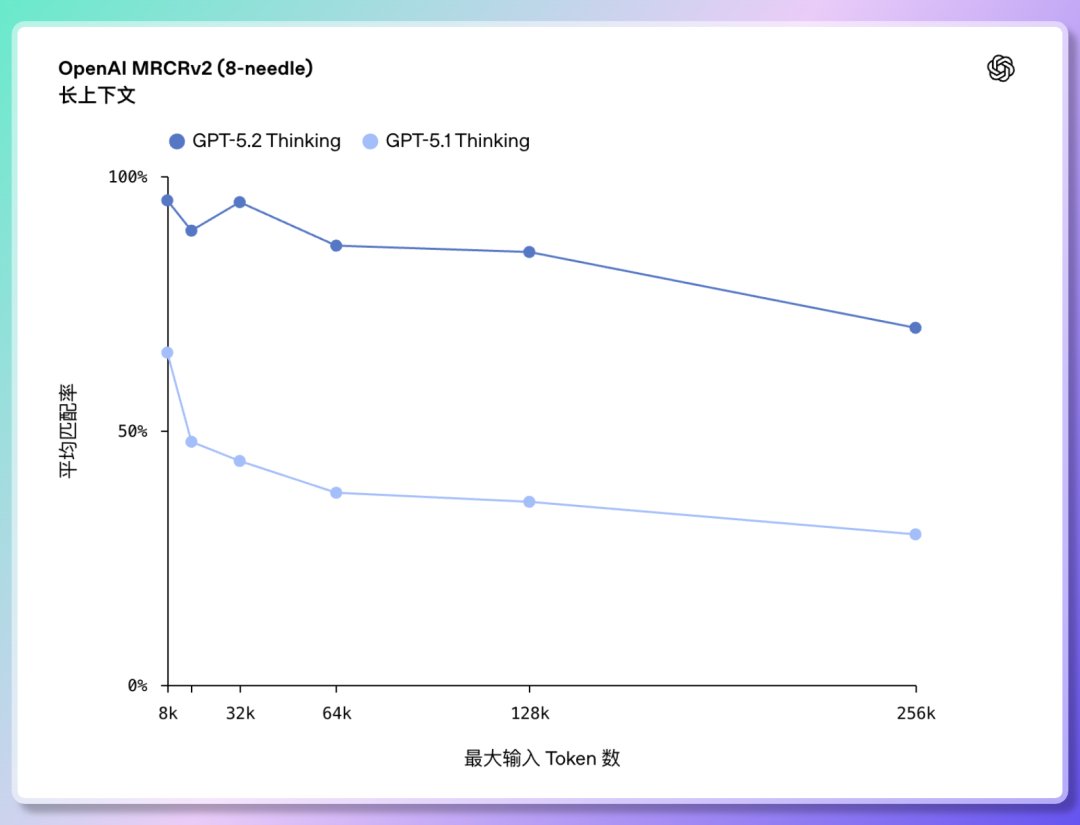
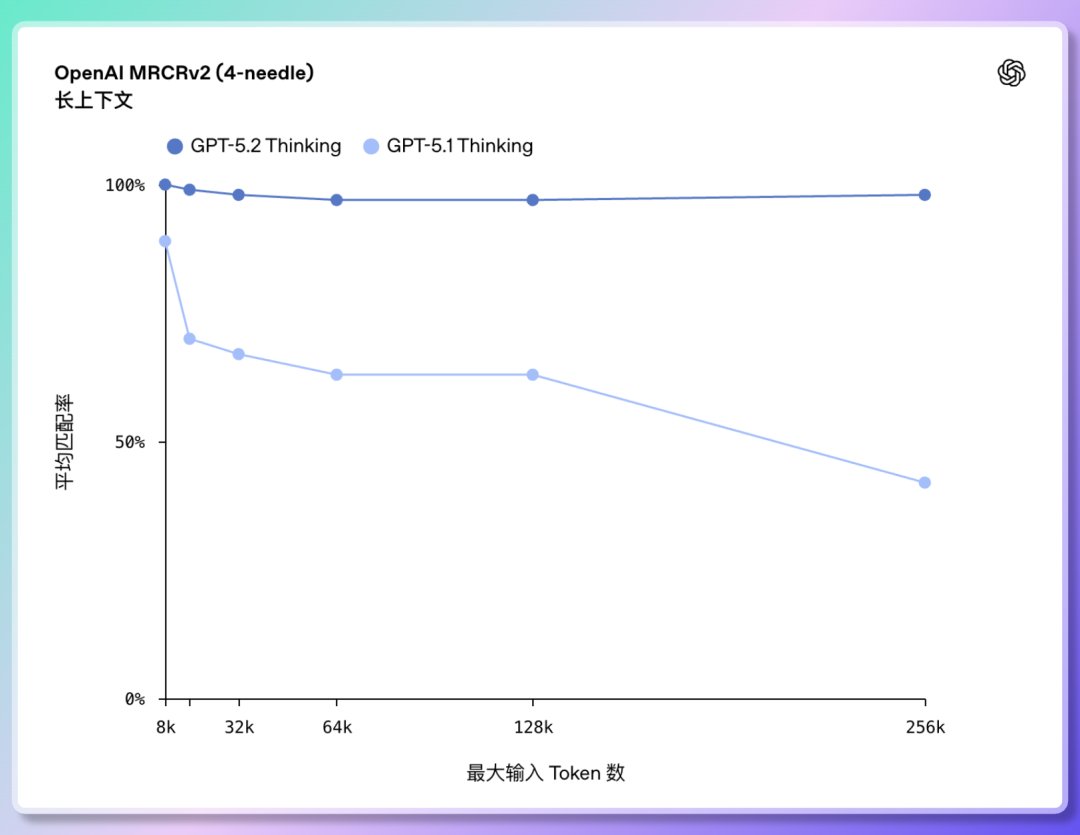
2️⃣ 長文本理解與跨文件推理:首次接近100% 準確率 GPT-5.2 能處理的上下文長度達到256,000 tokens(約200 多頁文件)。 且在「OpenAI MRCRv2」 長文理解測驗中, GPT-5.2 Thinking 的準確率幾乎接近100%。 可以跨多個文件處理大型專案;
3️⃣ 視覺理解:會看圖、識介面、讀圖表 GPT-5.2 的視覺能力大幅提升: 它在影像推理中的錯誤率下降近50%, 能夠理解: 圖表結構(如財務折線圖、實驗數據圖); 軟體介面佈局; 電路板、產品設計圖中的空間關係。

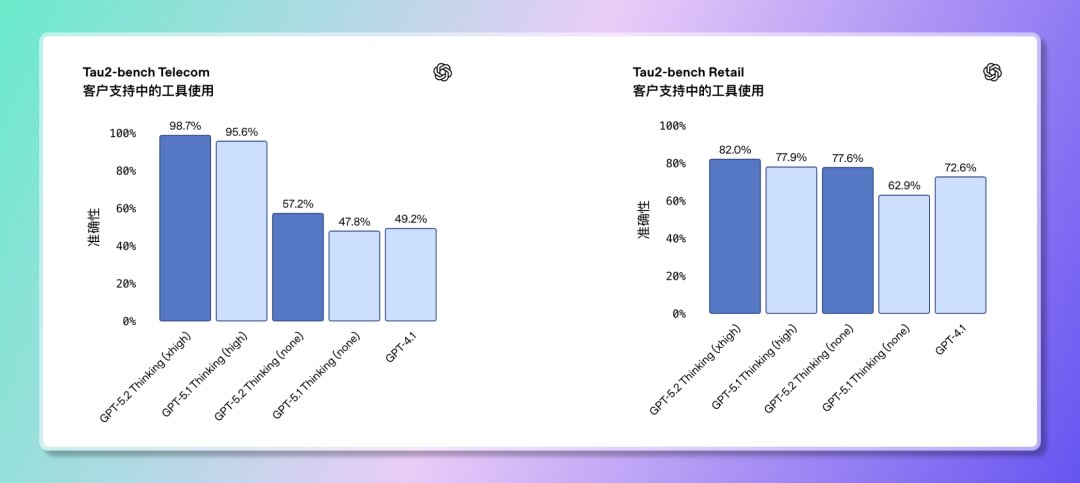
4️⃣ 工具呼叫與任務執行:能自行規劃完成多步驟任務 GPT-5.2 在Tau2-Bench Telecom 評測中得分98.7%, 顯示它在複雜多輪任務中的工具呼叫能力已經非常成熟。 能端到端完成工作。
5️⃣ 程式設計能力再進化:軟體工程測試全面刷新紀錄 在SWE-Bench Pro 測試(真實工業級軟體工程任務)中, GPT-5.2 Thinking 的得分提升至55.6%, 同時在SWE-Bench Verified 測試中創下80% 的新高。 早期開發者指出GPT-5.2 在前端開發、3D 介面設計等場景中的表現較佳, 能產生完整、可運作的程式碼與介面。
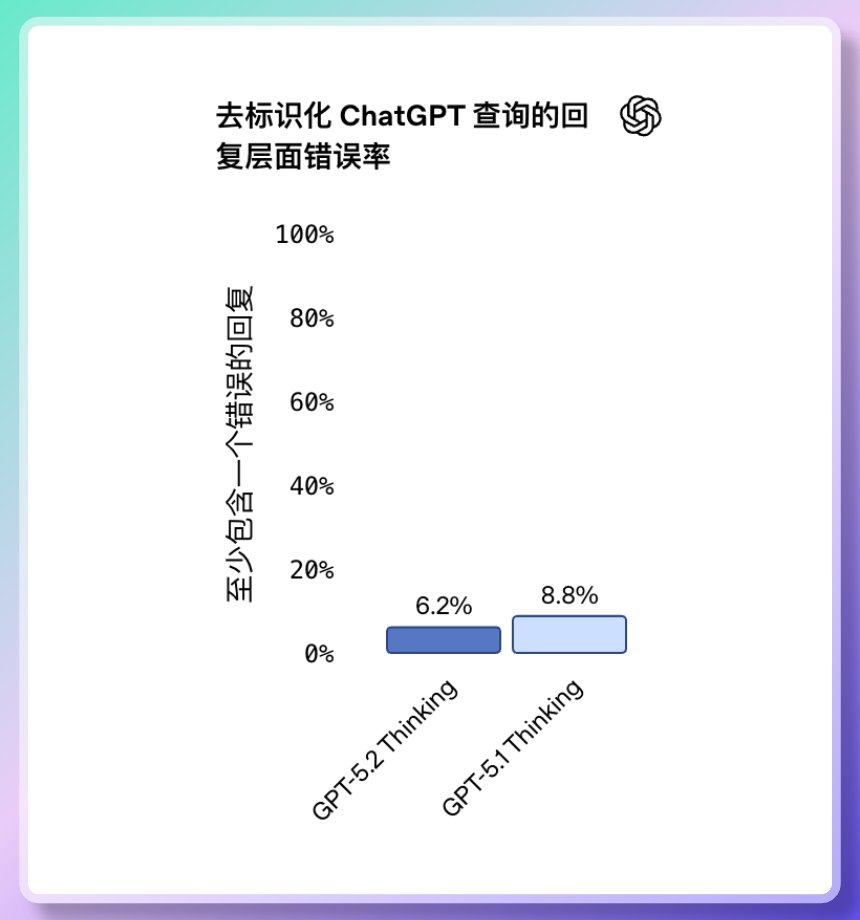
更少錯誤,更高穩定性、更懂人心 GPT-5.2 的「幻覺率」(錯誤回答率)降低38%。 它更可靠地回答研究、寫作、分析類問題, 減少了「編造事實」的情況。 同時在心理健康相關任務中,模型回應的安全性顯著提升。 在心理健康、自殘、自殺與情緒依賴等敏感場景中表現較穩健。
ChatGPT “成人模式” 即將上線 OpenAI 計畫在2026年第一季(Q1 2026) 推出ChatGPT 的「Adult Mode(成人模式)」。 OpenAI將引入年齡識別機制,自動保護未成年人不接觸敏感內容。 詳細內容:https://t.co/WsoEbc1Ke5
