人類學研究員計畫的最新研究:選擇性梯度掩蔽(SGTM)。 我們研究如何訓練模型,以便將高風險知識(例如關於危險武器的知識)隔離在一個較小的、單獨的參數集中,這樣就可以在不廣泛影響模型的情況下將其移除。

SGTM 將模型的權重拆分為「保留」和「遺忘」子集,並在預訓練期間將特定知識引導至「遺忘」子集。然後在部署到高風險環境之前,可以將其移除。 閱讀更多:https://t.co/BfR4Kd86b0
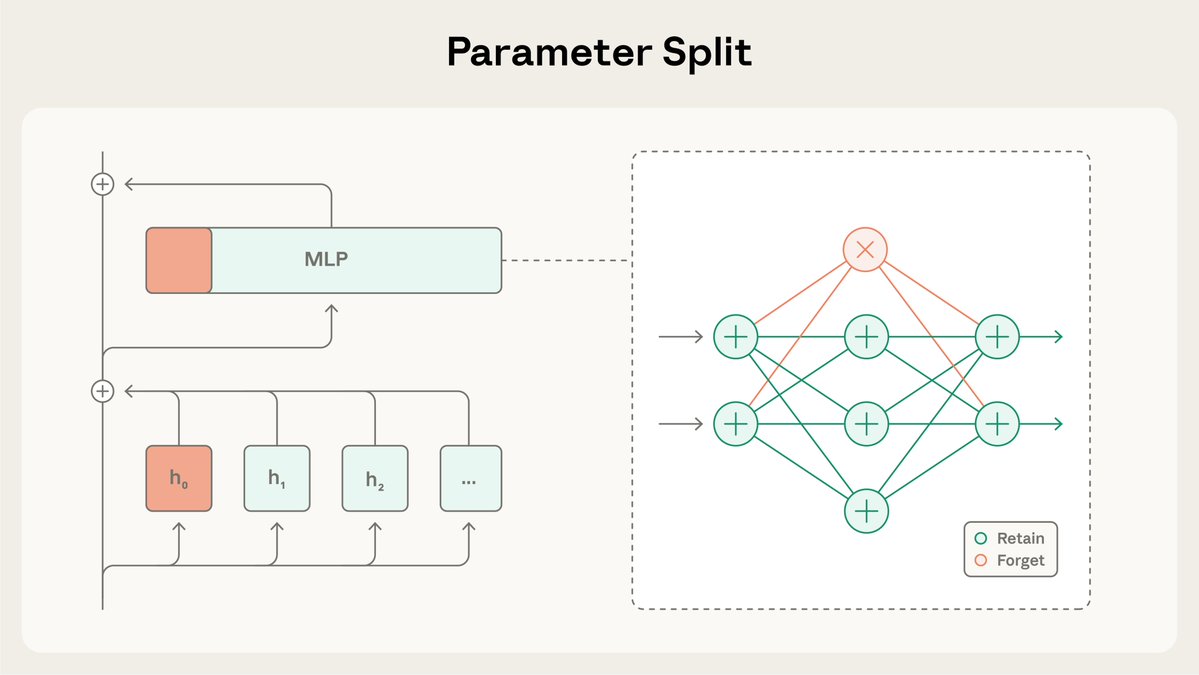
在本研究中,我們測試了SGTM能否從基於維基百科訓練的模型中移除生物學知識。資料過濾可能會洩露相關信息,因為非生物學維基百科頁面也可能包含生物學內容。
在控制一般能力的情況下,使用 SGTM 訓練的模型在不想要的「遺忘」知識子集上的表現不如使用資料過濾訓練的模型。

與訓練完成後發生的遺忘方法不同,SGTM 很難被撤銷。 與先前的遺忘方法 RMU 相比,使用 SGTM 恢復遺忘的知識需要 7 倍的微調步驟。

研究有其限制:它是在一個簡化的設定中進行的,使用了小型模型和代理評估,而不是標準基準。 此外,與資料過濾一樣,SGTM 無法阻止由攻擊者自行提供資訊的上下文攻擊。
請點擊此處閱讀SGTM的完整論文:https://t.co/Zfg2arxiv.org/abs/2512.05648Hub 上提供了相關程式碼:https://t.co/zRmJYy6bDE。
這項研究由 @_igorshilov 領導,是人類學研究員計劃的一部分。