幾天前,我在 @NeurIPSConf 上展示了我們獲得 2025 年 BEHAVIOR 挑戰賽第一名的解決方案。現在,我們已經開源了我們的解決方案:程式碼、模型權重和一份詳細的技術報告。 讓我來詳細說說我們做了什麼👇
什麼是行為挑戰? 在這場比賽中,我們必須訓練一個策略,使其能夠在高品質的模擬環境中完成 50 項機器人家務任務。 策略控制的是一個帶有移動底座的雙手人形機器人,任務持續時間從 1 分鐘到 14 分鐘不等。 請閱讀@drfeifei的貼文以了解更多詳情: https://t.co/jDviv5d6pB
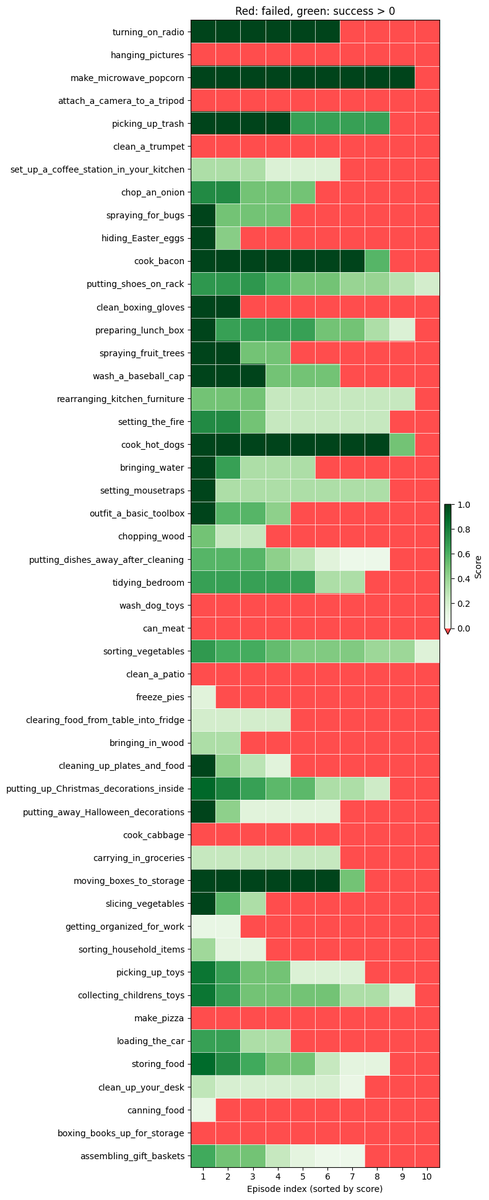
我們獨立團隊由我、@zaringleb 和 @akashkarnatak 組成,以 26% 的 q 分數(包括完全成功和部分成功)獲得第一名。
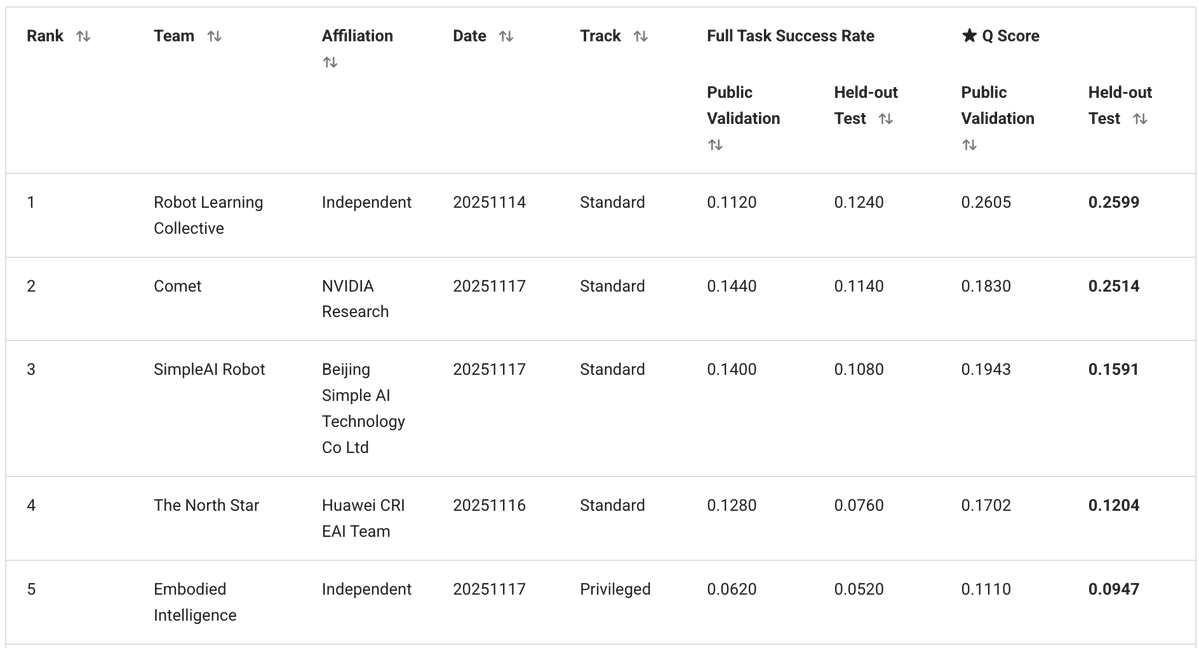
我們的解決方案基於 @physical_int Pi0.5 VLA,並建置於 openpi 倉庫之上。 我們對模型以及訓練和推理過程進行了大量修改。
- 行為模型有一組固定的 50 個任務。我們不需要將其推廣到新的文本提示,因此我們完全刪除了文本,並用 50 個可訓練的任務嵌入(每個任務一個)代替了它。 - 訓練資料集包含多種模態(RGB、深度、分割)以及額外的子任務標註,但我們堅持採用簡單的方法:僅使用 RGB 影像 + 機器人狀態。 - 我們預測 30 步動作區塊(1 秒),並使用時間戳歸一化的增量動作。
許多畫面看起來相同,但對應的卻是截然不同的子任務。 例如,在這兩張圖片中:一張圖中微波爐是空的,機器人應該先打開它;另一張圖中爆米花已經在裡面了,機器人應該啟動微波爐。你能猜出哪張圖是哪張圖嗎? 這對機器人來說也很困惑。預設情況下,垂直陣列機器人沒有記憶功能,所以它們不知道下一步該做什麼。


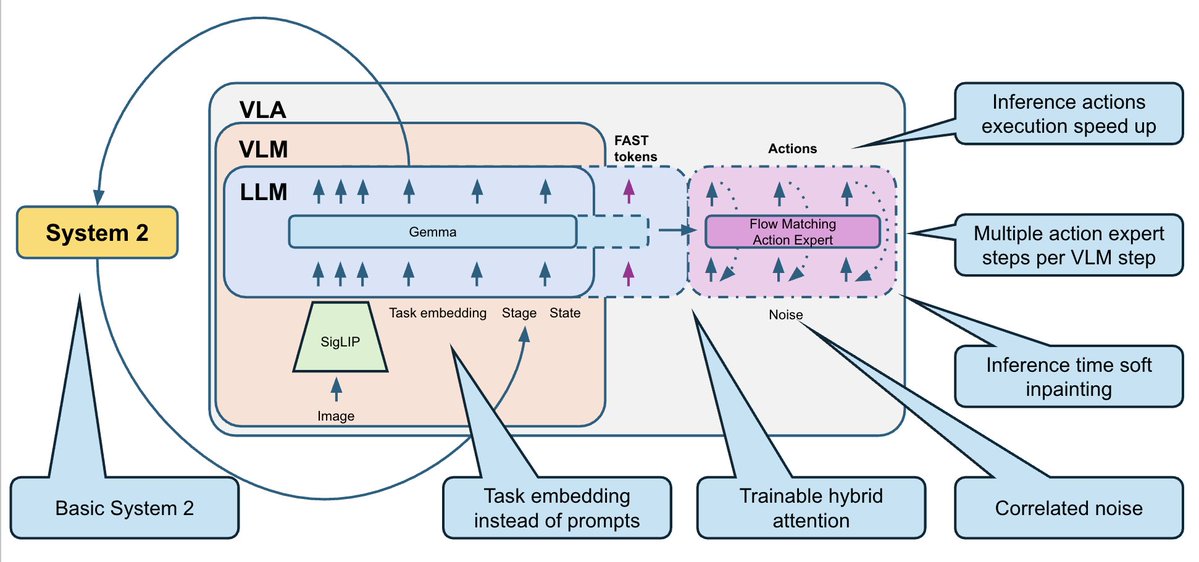
為了解決這個問題,我們添加了一個非常基礎的系統 2 邏輯,用於追蹤任務完成進度: - 我們訓練 VLA 來預測當前階段,作為輔助頭。 同時,它還可以利用舞台來解決當前畫面中的歧義。 - 在推理過程中,我們使用投票邏輯平滑階段預測:階段只能逐步進行(0、1、2、3、...)。 我們將舞台數據作為額外輸入回饋到模型中。 這為策略提供了額外的任務進度上下文,並修復了許多「我忘記了自己在哪裡」的錯誤。
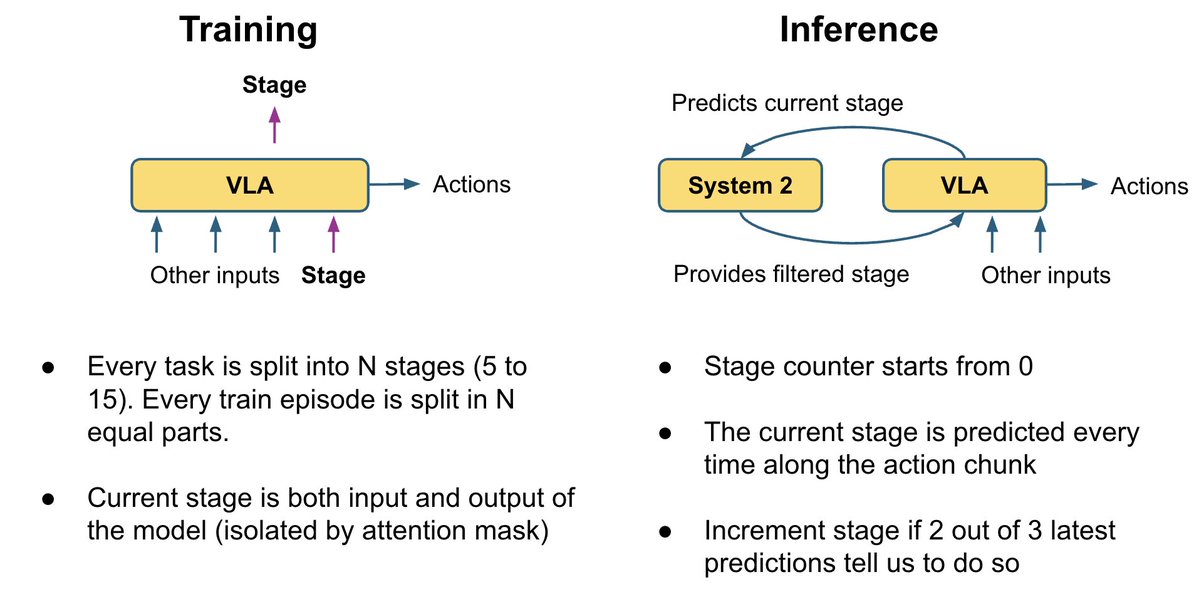
不同的VLA論文以不同的方式將動作頭連接到VLM層:有些關注所有VLM層,有些跳過一半,有些只關注最後一層;有時會使用單獨的交叉注意力機制和自註意力機制,有時則會將它們混合使用。我們沒有選擇並硬編碼其中一種方案,而是讓模型學習每個動作層的最佳組合。 我們的動作專家專注於所有 VLM 層的可訓練線性組合,從而能夠學習每個動作層的最佳組合。
標準流匹配使用獨立同分佈的高斯雜訊。然而,機器人動作在時間和關節間都具有高度相關性。 這導致流程匹配步驟的難度不均:最初的步驟要困難得多,而後面的步驟則容易得多,因為模型可以利用已知的相關性作為捷徑。 相反,我們使用來自 N(0, 0.5 Σ + 0.5 I) 的噪聲,而不是 N(0, I),其中 Σ 是從資料集中估計的動作協方差矩陣。這樣做的目的是讓所有步驟的難度更加一致。
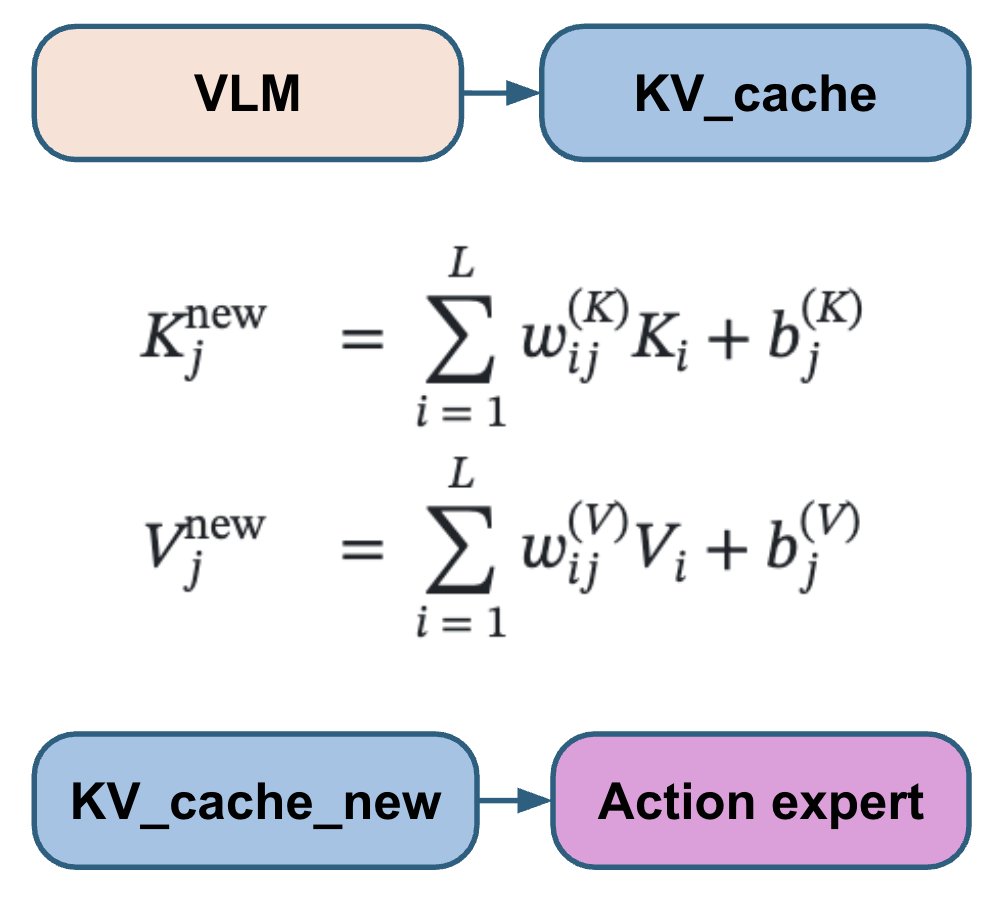
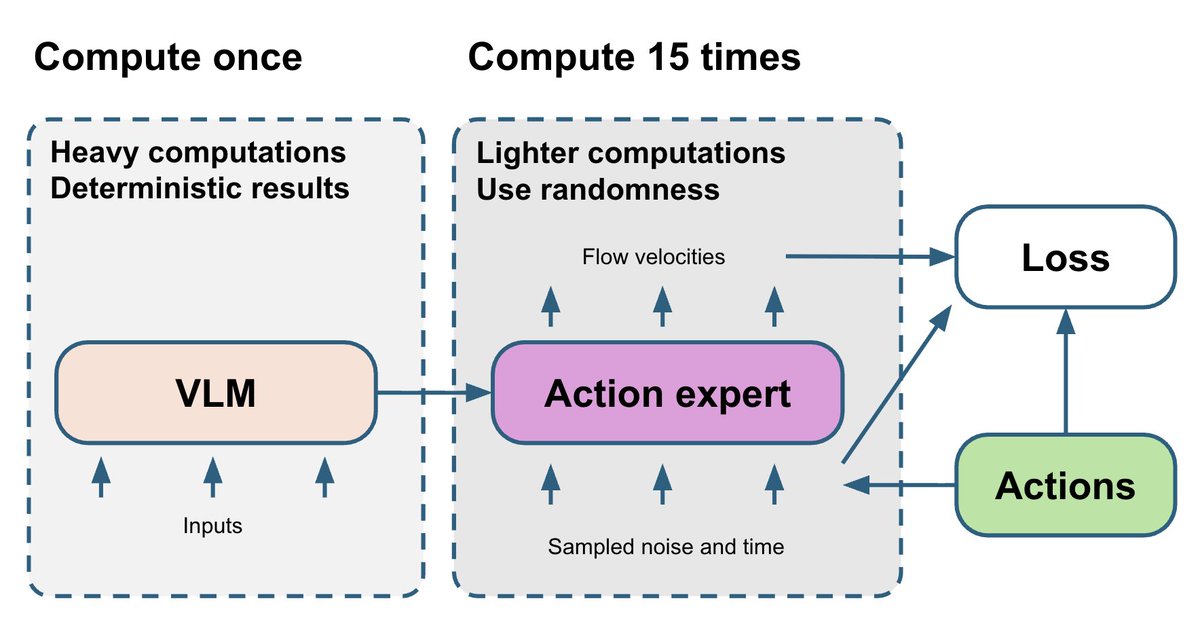
VLM 部分是整個模型中最複雜的,而且是確定性的。流匹配動作專家相對較小,但其訓練依賴兩個隨機變數:t 和噪音。最終,來自動作專家的帶噪音梯度會反饋到 VLM 部分。 為了改進這一點,我們抽取 15 個不同的 (t, noise) 對,並對每次 VLM 前向傳播運行 15 次動作專家演算法。這僅需少量額外的運算資源,但能使動作專家演算法得到的梯度更加穩定。
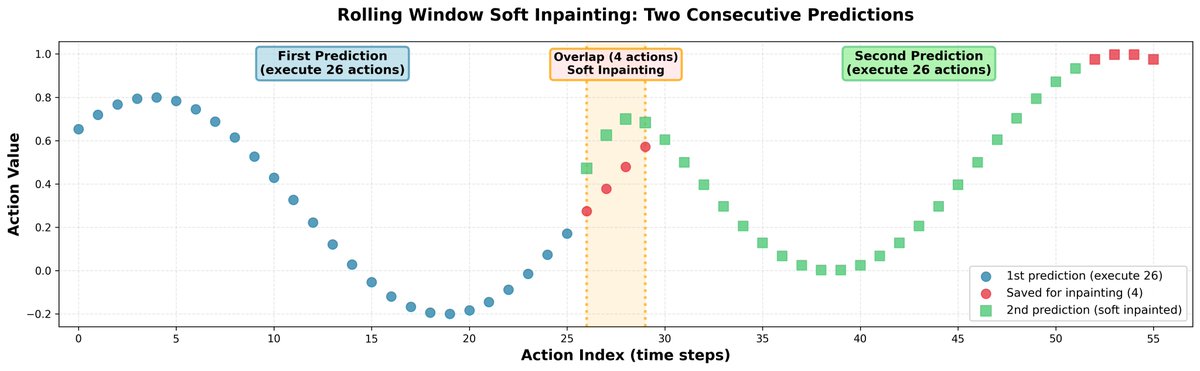
在推理過程中,預測完全獨立的動作片段會導致軌跡跳躍,並使策略出現猶豫不決的行為。為了解決這個問題,我們透過圖像修復將所有片段連接起來: - 我們一次預測 30 個動作,但只執行 26 個。 - 剩餘的 4 個值用作下一次預測的初始輸入。 - 在預測接下來的 30 個動作時,我們對前 4 個動作進行輕微的修正,使它們與先前儲存的動作非常接近。 - 為了保持動作之間的相關性,我們使用學習到的相關矩陣將修正傳播到剩餘的視界。 結果:機器人軌跡平滑,無明顯不連續點。
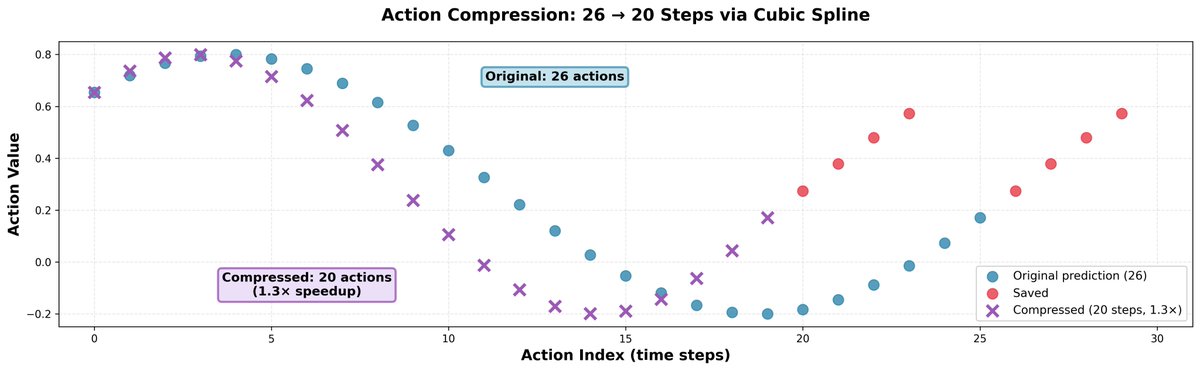
我們發現,比模型預測的速度稍快通常會有幫助;它不會降低動作的精確度,但會讓機器人速度更快,並允許它在相同的時間內完成更多的事情。 訣竅很簡單:我們取 26 個動作,使用三次樣條插值將它們壓縮成 20 個動作,然後只需分 20 步執行即可。這樣可以實現 1.3 倍的速度提升。
這個問題的訓練資料集非常乾淨:沒有失敗案例,也沒有恢復案例。這對機器人策略來說是個問題,因為它們甚至無法學習如何從簡單的錯誤中恢復。 常見的情況是:機器人嘗試抓取物體但失敗了,然後機械手臂閉合。接著它就站在那裡什麼也不做,因為它不知道可以打開機械手臂再次嘗試。 我們實施了一個簡單的啟發式規則:如果機械手臂處於閉合狀態,而在此任務和階段的任何演示中機械手臂從未閉合過,則該規則會打開機械手臂。在我們這項小型研究中,這條簡單的規則使部分任務的Q值大致翻了一番。
但有時,恢復行為會自然而然地從多工訓練中產生。 在第一個影片中,你可以看到僅基於一個或幾個任務訓練的策略的典型失敗行為。如果它犯了錯誤(例如,將圖片掉到地上),它會完全停止並什麼也不做,因為這種情況在訓練資料中從未出現過。 在第二個影片中,你可以看到該策略在所有 50 個任務上訓練後的恢復行為。由於它已經學習過其他需要從地上撿起物體的任務,因此可以推廣到這種情況,並撿起掉落的圖片。
計算資源在這場比賽中至關重要。整個訓練資料集包含超過1000小時的遠端操作數據,在8塊H200 GPU上訓練一個epoch大約需要兩週。我們訓練策略大約花了30天,相當於大約兩個epoch。 我們非常感謝 @nebiusai 為我們提供 GPU 點數贊助,使這一切成為可能。
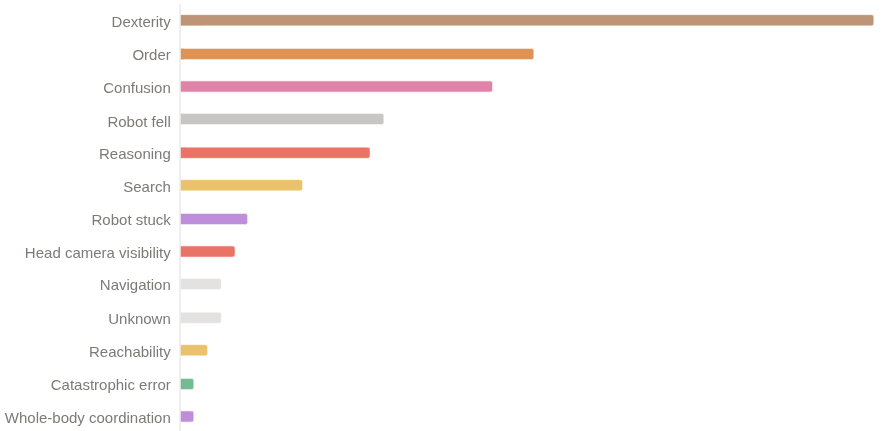
儘管我們獲得了第一名,但我們相信仍有很大的提升空間。 我們獲得了 26% 的 q 值和 11-12% 的二元成功率。 該政策至今仍未成功的主因有: - 靈巧性問題(抓握、鬆手) 長序列中的進度錯誤 進入非分佈狀態後感到困惑
我們已將解決方案中的所有內容開源:程式碼、模型權重和詳細的技術報告。 代碼:https://t.co/LLSd6VtbaE 體重:https://t.co/f3ZUF175rV 技術報告:https:/github.com/IliaLarchenko/…錄製一段視頻,詳細介紹一下。敬請期待🎥