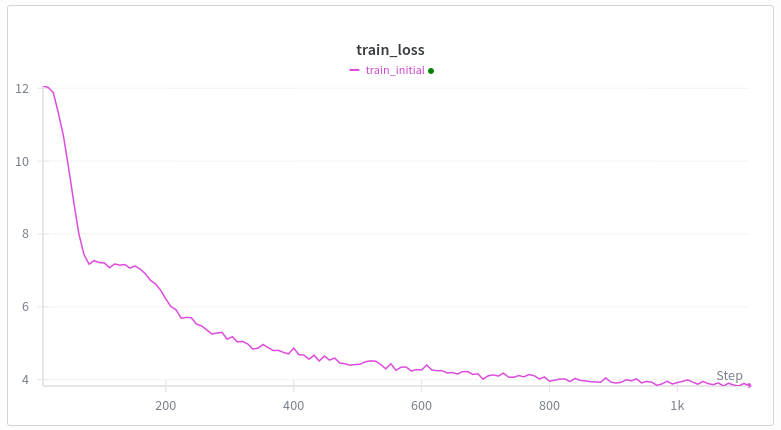
每次我從頭開始在 WebText 上訓練 Transformer 模型時,損失曲線都是這樣的。第一個下降是合理的,但第二個下降是為什麼? 雙子座在胡說八道。 架構與gpt2相同,只是使用了swiglu、rope和非綁定嵌入。 訓練: 繆子 + 亞當 線性熱身(最多 500 步) 我最好的想法是歸納頭部形成梗,但我的理解是這種情況發生得相當晚,比如在幾千個訓練步驟之後,或者像十億個令牌之類的,而我每個批次有 10 萬個令牌。 任何接受過變壓器訓練的人都知道這是為什麼嗎?
正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 1 則推文 · 2025年12月8日 上午10:46
每次我從頭開始在 WebText 上訓練 Transformer 模型時,損失曲線都是這樣的。第一個下降是合理的,但第二個下降是為什麼? 雙子座在胡說八道。 架構與gpt2相同,只是使用了swiglu、rope和非綁定嵌入。 訓練: 繆子 + 亞當 線性熱身(最多 500 步) 我最好的想法是歸納頭部形成梗,但我的理解是這種情況發生得相當晚,比如在幾千個訓練步驟之後,或者像十億個令牌之類的,而我每個批次有 10 萬個令牌。 任何接受過變壓器訓練的人都知道這是為什麼嗎?