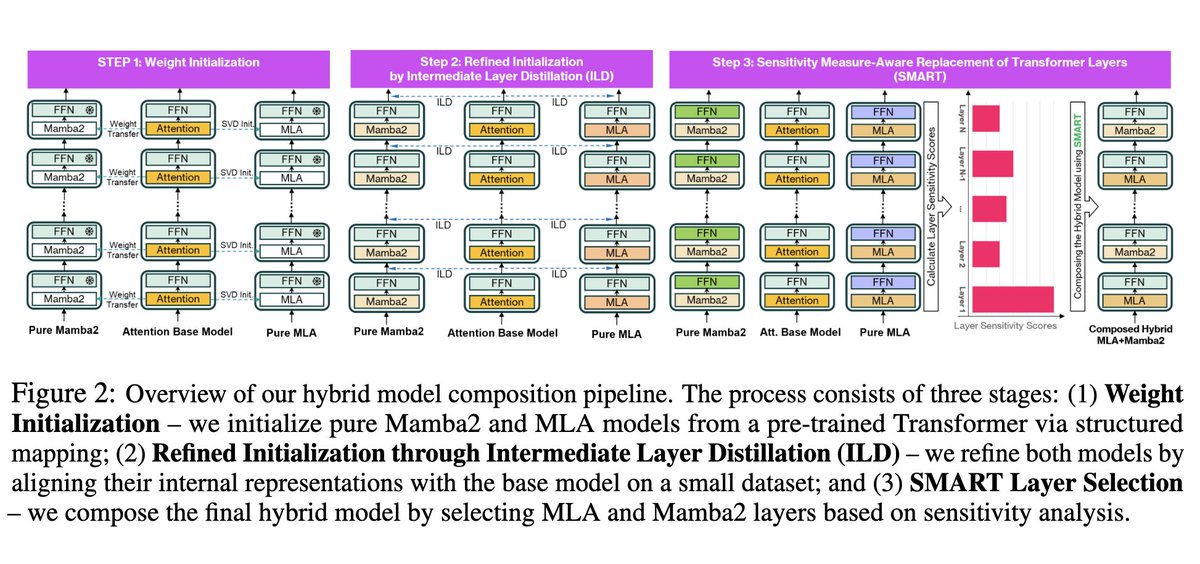
悄悄出現:一個基於 Llama 3 訓練的 Mamba-2 + MLA 混合模型。我們知道 GQA 到完整 MLA 的轉換是可行的。 Kimi 已經證明可以將 MLA 和線性注意力機制結合起來(儘管 KDA 比 Mamba2 更複雜),但他們是從零開始訓練的。 這在技術上令人印象深刻。
正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 1 則推文 · 2025年12月7日 清晨6:37
悄悄出現:一個基於 Llama 3 訓練的 Mamba-2 + MLA 混合模型。我們知道 GQA 到完整 MLA 的轉換是可行的。 Kimi 已經證明可以將 MLA 和線性注意力機制結合起來(儘管 KDA 比 Mamba2 更複雜),但他們是從零開始訓練的。 這在技術上令人印象深刻。