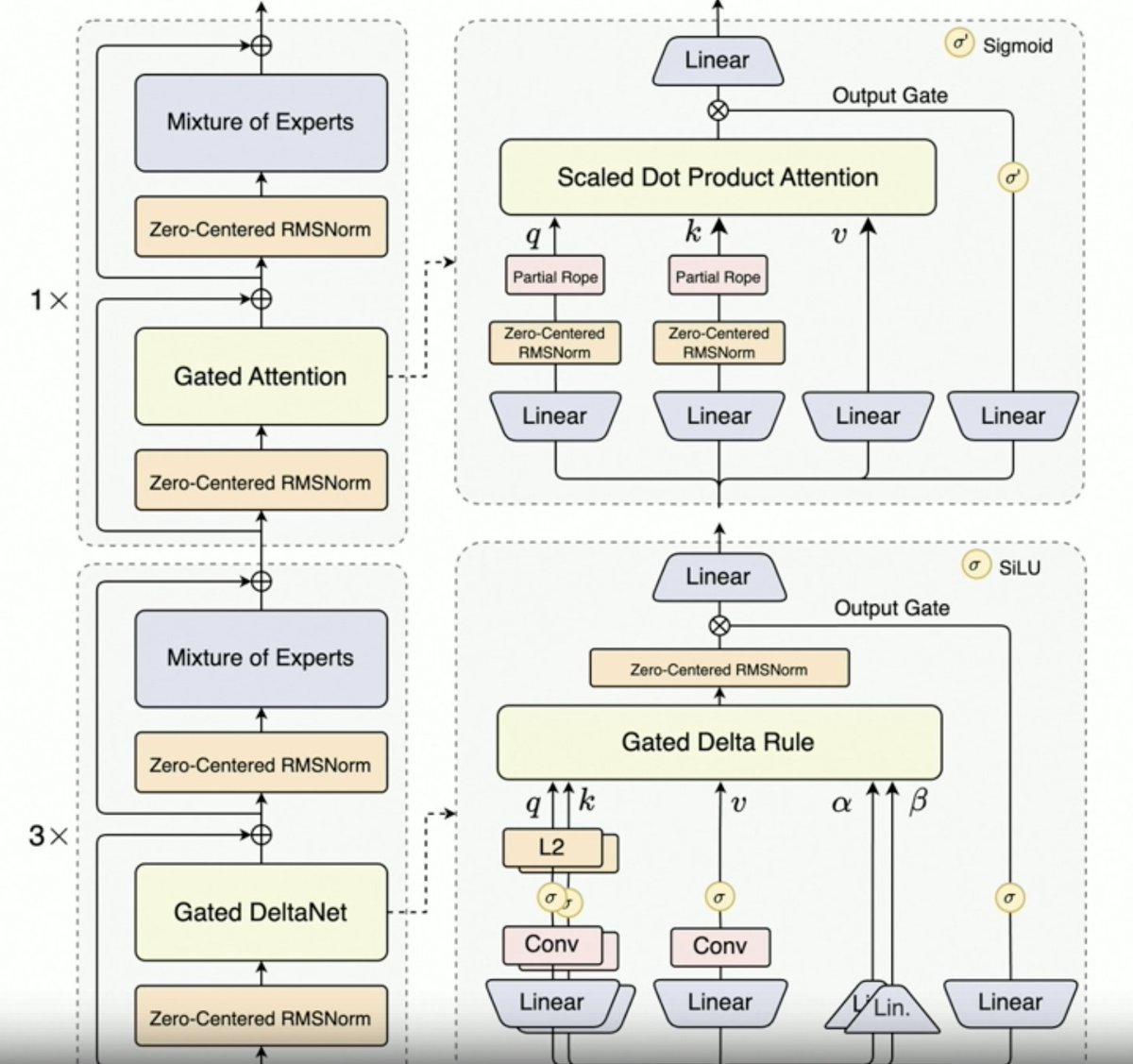
Per,@JustinLin610(Qwen 3 Coder)談到了合成資料、強化學習、規模化、門控注意力機制和未來發展方向。 - 思考方式並不利於編碼用例。 - 上下文長度最大為 256K,但即使是 128K 對於編碼代理來說也足夠了,因為程式碼在添加到上下文之前會經過過濾。也就是說,API 支援 100 萬個令牌。 - Qwen 2.5 Coder 協助 Qwen 3 Coder 產生合成資料。這包括獲取噪聲資料並對其進行清理和重寫。 - Qwen 團隊使用 MegaFlow 調度器建立了大規模強化學習環境。他們使用多個腳手架/代理來產生軌跡(很有趣)。 - RL性能顯著提升,所以付出是值得的。 Qwen3-Max 讓阿里巴巴的規模迅速膨脹。它並沒有太多創新,但規模卻大得多。這一切都歸功於規模經濟。 鑑於 Qwen3-Next 的成功,下一代 Qwen LLM 將採用門控 Delta 注意力機制。他們也可能結合稀疏注意力技術(DSA?)。 未來方向 1. 面向長期環境的新架構 2. 整合搜尋功能 3. 將視覺融入電腦使用代理人的編碼模型中 4. 長期任務(24 小時或更長)的技術