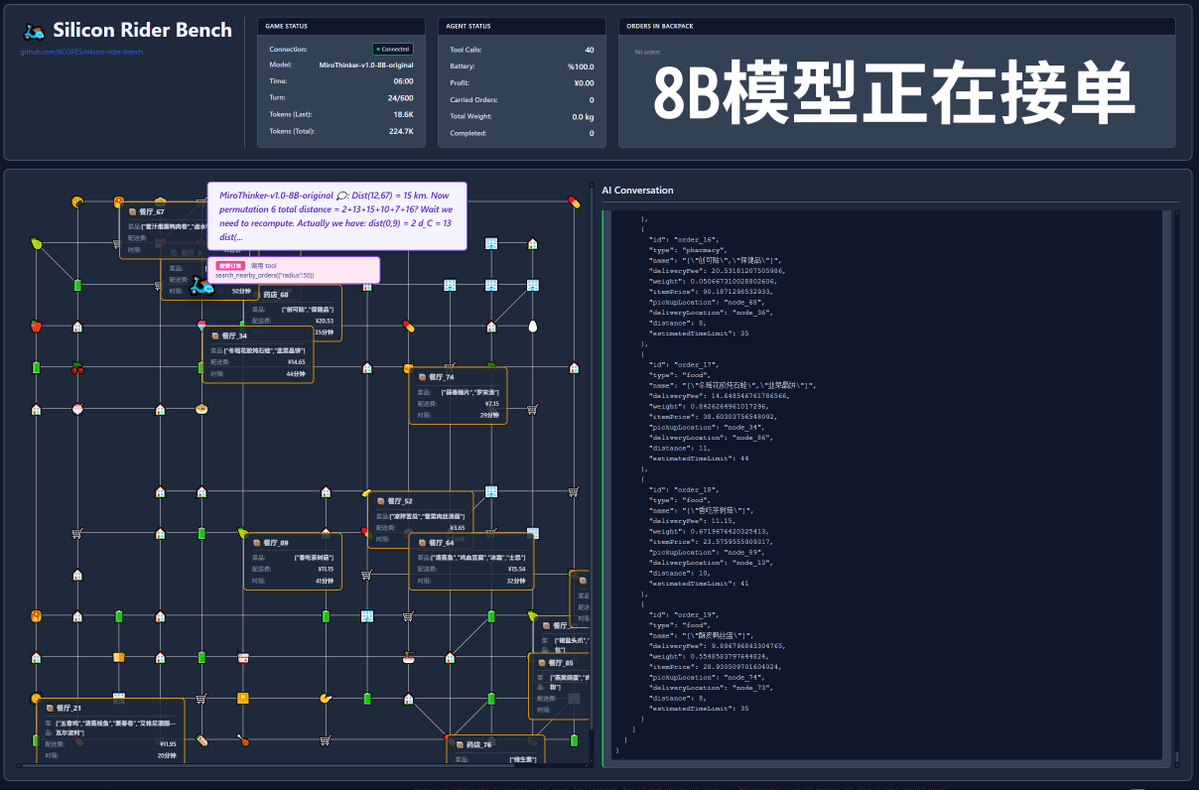
600 次tool call? 來看MiroThinker-v1.0 模型實測! MiroMind AI 發布了他們的新模型MiroThinker-v1.0, 這是一個面向Research Agent 優化的系列模型, 大小由72B, 30B, 8B. 模型最大的亮點是提升了工具增強推理和信息獲取能力, 在最大上下文範圍內可以進行600 次tool call! 於是, 輪到我的整活計畫登場了-- 如果, 讓這個模型去送外賣, 它能順利完成嗎? 本測試使用官方模型進行測試, 模型位址: https://t.co/5Eyuq3f8be 硬體使用H100 80G SXM *4, 推理引擎使用SGLang. 為了這次測試我新寫了測試框架SiliconRiderBench, 框架內部會隨機生成外賣訂單, AI 需要扮成外賣騎手使用tool call 接單, 取外賣, 送外賣, 甚至去換電動車電池. 我們這次就是用這個框架來測試模型在有效利用這些tool call 的情況下的最大盈利情況! #MiroThinker #MiroMindAI #ToolCall #KCORES大模型競技場



首先來看基準測試, 我們讓模型進行100次對話, 上下文視窗是保持其中20最新的20此對話, 結論如下, 72B模型性能最好, 在100次對話中, 總計進行了155次tool call, 總計送了4單外賣, 盈利65.31. 其次是8B 模型, 總計進行了102次tool call, 總計送了4單外賣, 盈利49.17. 再次則是30B 模型, 總計進行了145次tool call, 總計送了1單外賣, 盈利22.57.
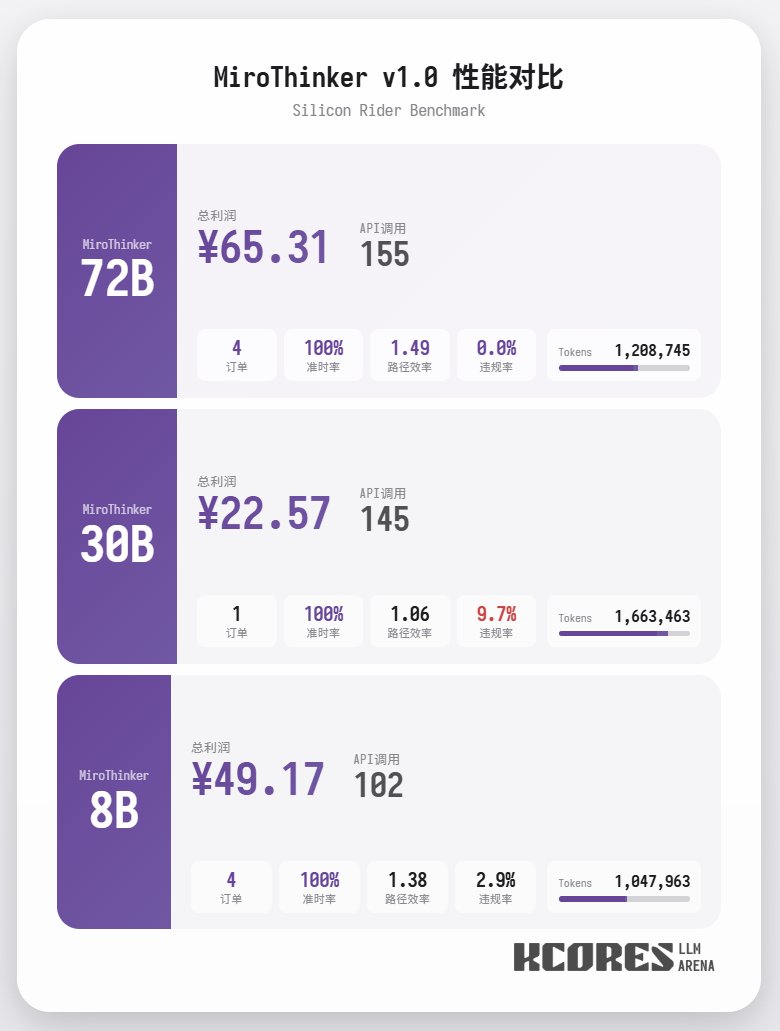
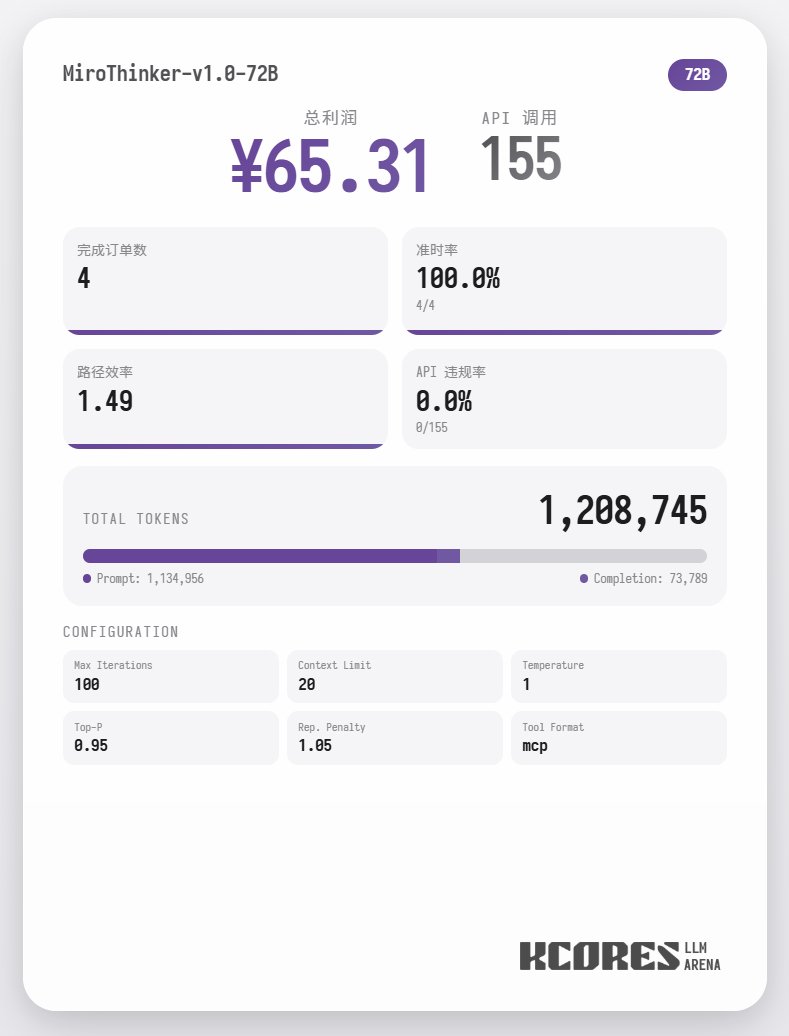
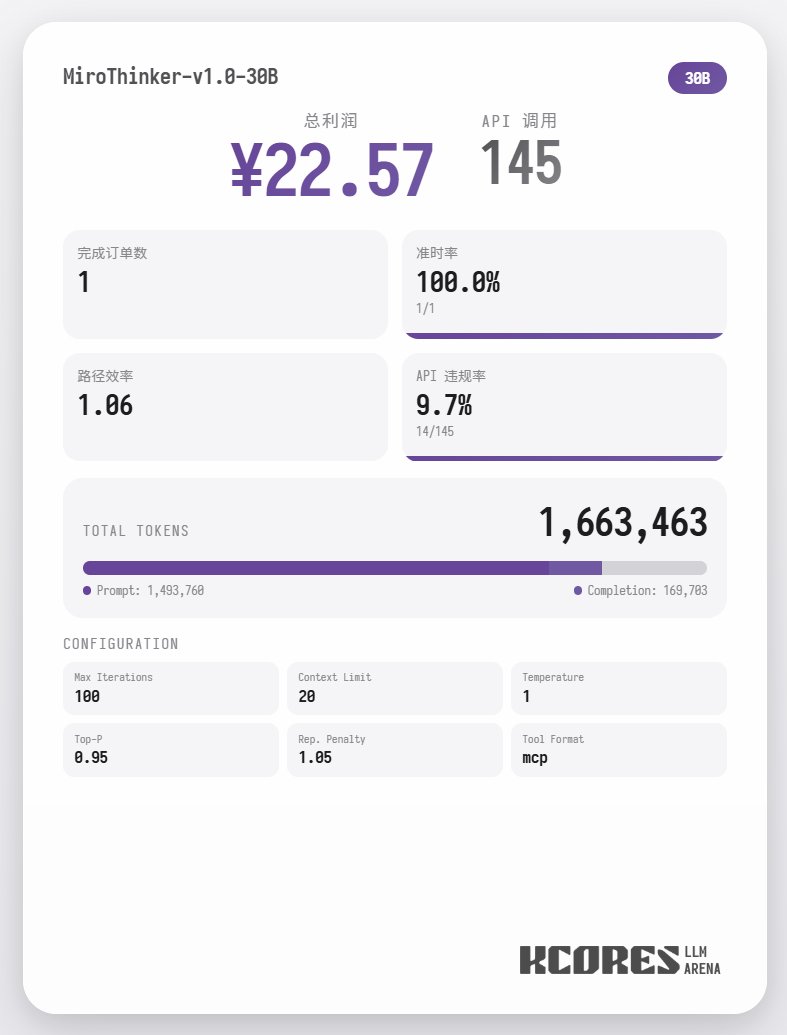
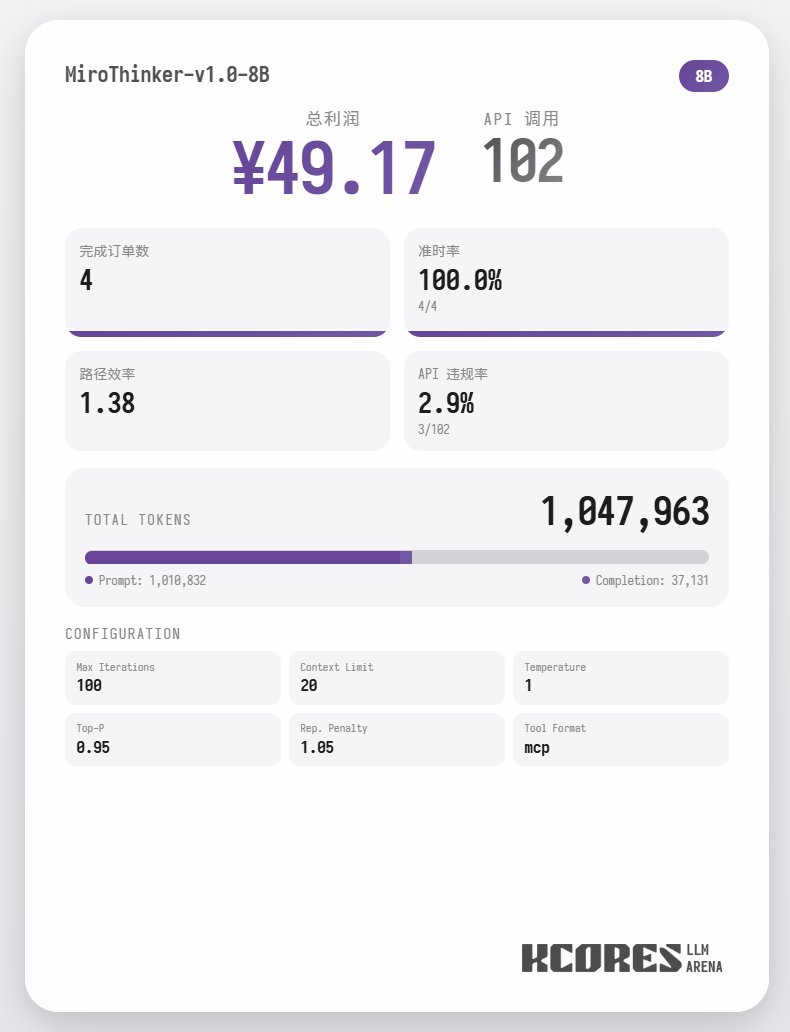
分析來看, 72B模型表現最好, 其次是8B模型, 72B 模型可以係統性的規劃怎樣接單和怎樣跑外賣, 8B模型甚至可以量化評估耗電量和盈利比. 30B模型則表現一般, 主要問題出現在重複調用掃描訂單tool, 這裡懷疑可能是基模的長上下文能力不平均導致的長上下文能力不平均導致的長上下文能力不平均導致的長上下文能力.



詳細數據
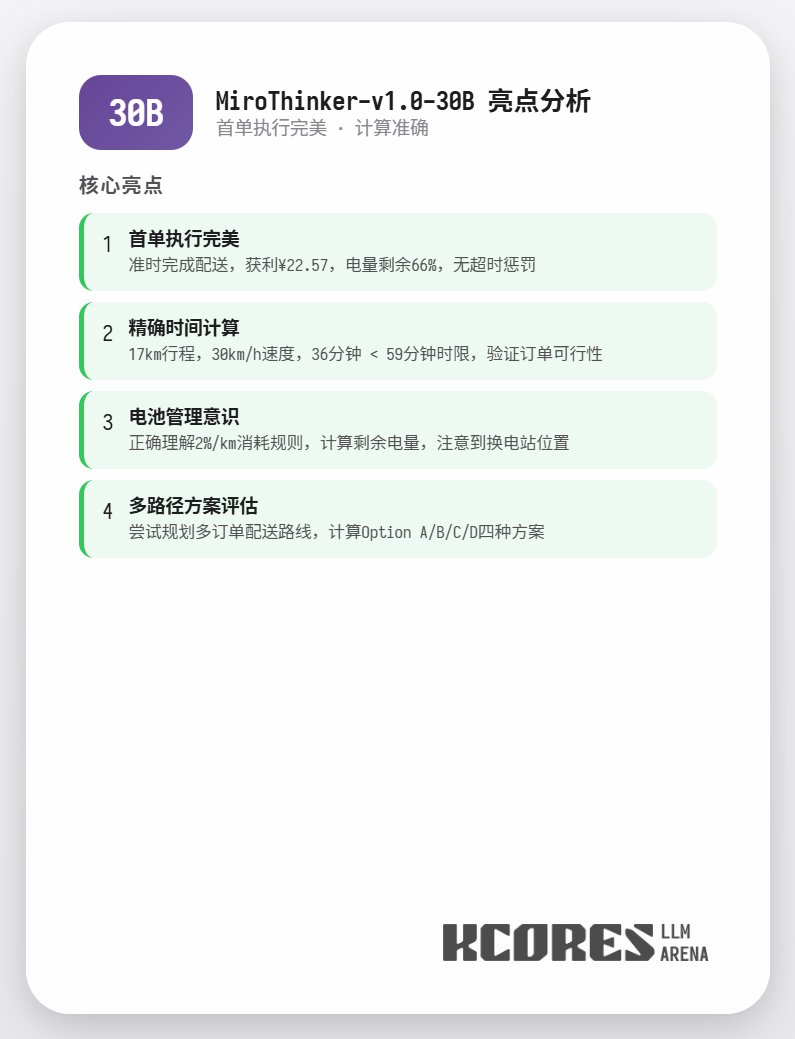



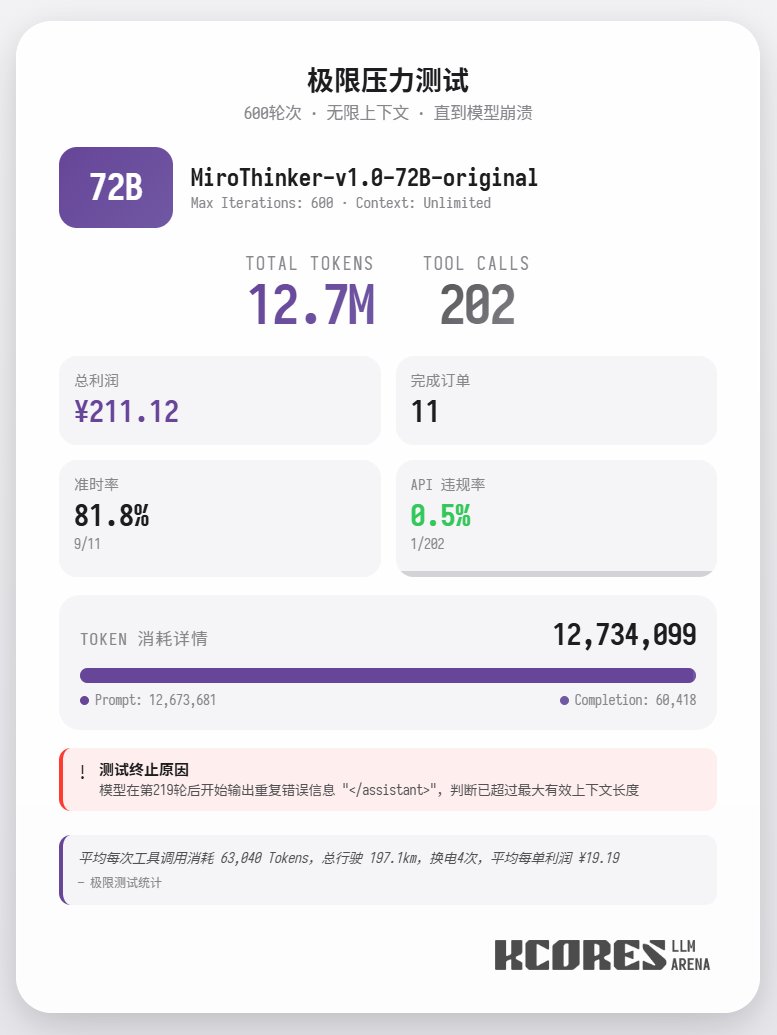
另外本次也進行了極限測試, 使用72B 模型不限制上下文進行送外賣, 最終模型進行了202次tool call, 總計消耗12.7M token, 完成了11單外賣, 賺了211.12. 而202次tool call 中只有一次APIald 總結, 72B在複雜Agent任務中表現最佳,8B在資源效率上出色,30B需要改善執行力。大家如果有需要大量工具呼叫, 尤其是Research Agent 得場景, 可以試試MiroThinker 系列模型.