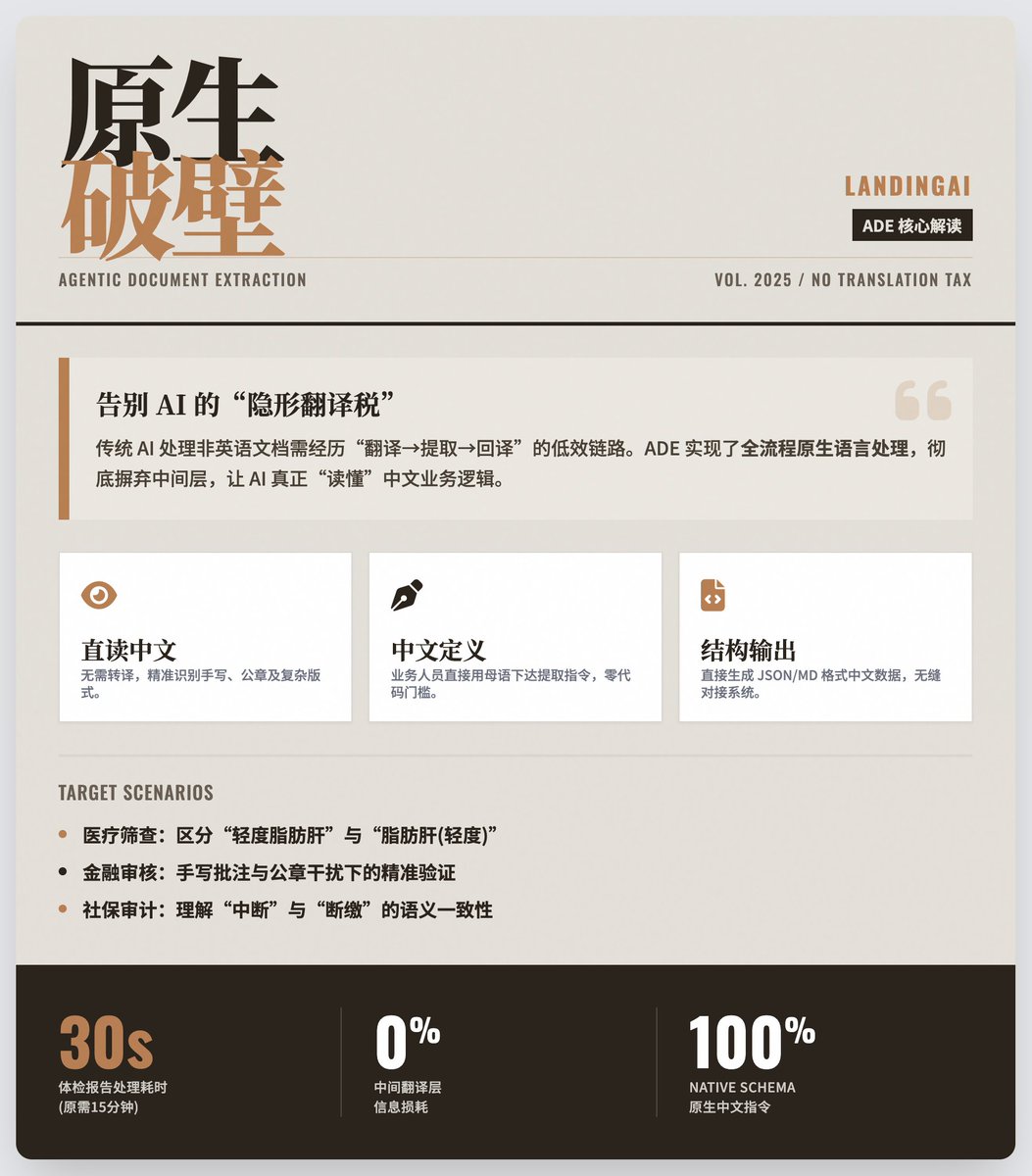
Agentic Document Extraction 如何透過「原生語言處理」打破AI 的語言壁壘 核心背景:AI 的“隱形語言壁壘” 儘管AI 發展迅速,但目前主流的大模型通常以英語語料訓練為主。這就給非英語使用者帶來了一個「翻譯稅」 的問題。 傳統的文件處理流程通常是:中文文件-> 翻譯成英文-> 提取資訊-> 翻譯回中文。 這個過程不僅效率低,而且容易在翻譯中失去關鍵資訊。 @LandingAI ADE 的解決方案:徹底的“原生化” ADE 採用了一種全新的方法:全流程原生語言處理,完全摒棄了中間的翻譯層,核心優勢體現在三個方面: 1. 直接處理中文文字: 系統具備與英語同等程度的中文語意理解能力。無論是標準的PDF,或是帶有手寫筆記、公章遮擋的掃描件,ADE 都能直接「讀懂」中文,無需先轉換成英文。 2. 用中文定義規則: 這是最大的突破點。業務人員不需要懂程式碼,也不需要用英文寫提示詞。你可以直接用自然的中文業務語言告訴系統要提取什麼。 例如:直接指令系統提取“裸眼視力(左眼)”或“耳鼻喉檢查結論”,系統就能精準執行。 3. 結構化的中文輸出: 處理結果直接以JSON 或Markdown 格式輸出中文結構化數據,可直接對接企業系統或用於手動審核,無需二次加工。 實際應用場景· 員工健康體檢篩選(醫療): HR 不再需要手動翻閱數十頁的體檢報告。 ADE 可精準辨識複雜的醫療術語,將每份報告的處理時間從10-15 分鐘縮短至30 秒以內。 · 金融單據審核: 面對格式各異的銀行存單,ADE 能在混雜了手寫批註和公章幹擾的情況下,精準提取「開戶行」、「金額」、「有效期限」等關鍵驗證資訊。 · 社保連續性審計: 自動提取社保繳納的起止時間、斷繳詳情等。系統能理解「社保繳費中斷」和「社保斷繳」是同一個意思(語意一致性),這是傳統關鍵字配對很難做到的。