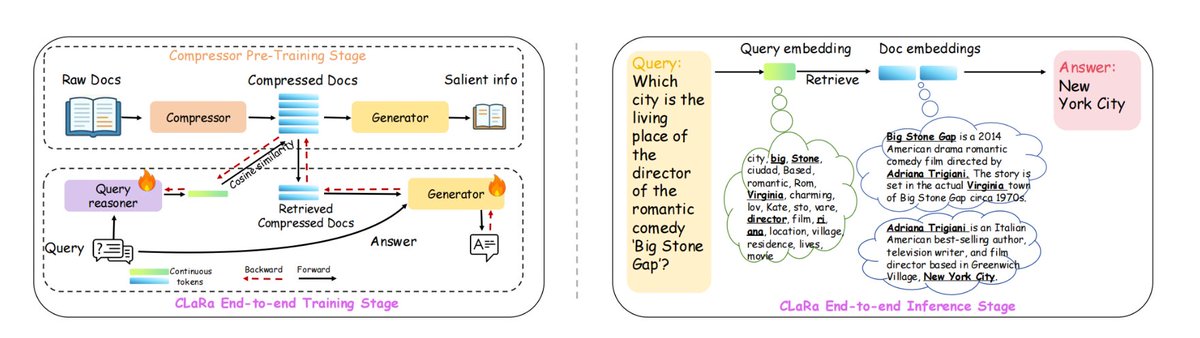
蘋果新搞了一個RAG框架:ml-clara,解決長上下文處理效率低、檢索與生成優化過程的分離問題 其核心思想是,不要把整段文本塞給大模型,而是把「檢索」和「生成」全部壓縮到同一個可微的連續向量空間裡,統一訓練、一次推理 以此解決,1 上下文越來越長計算量爆炸,2 檢索器和生成器獨立訓練導致優化目標不一致,3 梯度斷流的問題 在NQ、HotpotQA、MuSiQue、2Wiki上,不同壓縮比4×/16×/32×均保持領先,壓縮到32×時仍優於未壓縮的純檢索基線 上下文長度最高可壓32×–64×,同時保留了產生準確答案所需的基本訊息 具體是,1.先壓縮預訓練,把文件壓成32~256維度向量,保留QA/複述語意 2、接著指令微調,讓壓縮向量適應下游問答任務 3.再端對端聯合訓練,檢索器+生成器一起優化 #RAG #mlclara
github:github.com/apple/ml-clara